点击上方“icloud布道师”,“星标或置顶公众号”
逆境前行,能帮你的只有自己

************************************
春风她吻上我的脸
告诉我现在是春天
春天里处处花争艳
别让那花谢一年又一年
本文制作需要3小时,阅读需要5分钟
系统调优概述
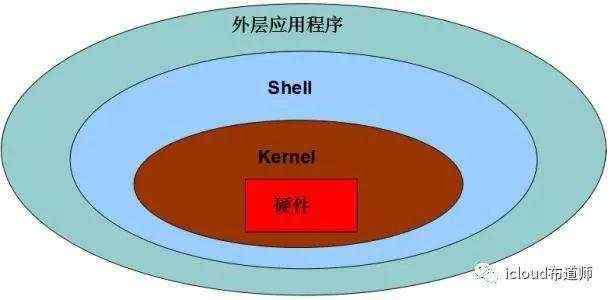
系统调优
:
1.系统的运行状况: CPU -> MEM -> DISK*-> NETWORK -> 应用程序调优
2. 分析是否有瓶颈(依据当前应用需求)
3. 调优(把错误的调正确)
性能优化:
指的找打系统中的瓶颈并去除这些瓶颈
性能优化其实是对OS 各子系统达到一种平衡的定义,这些子系统包括了:
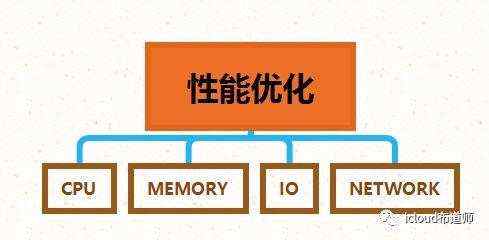
这些子系统都是相互关联的,任何一个出现高负载都会产生影响
比如:
大量的网页调入请求导致内存队列的拥塞;
网卡的大吞吐量可能导致更多的 CPU 开销;
大量的 CPU 开销又会尝试更多的内存使用请求;
大量来自内存的磁盘写请求可能导致更多的 CPU 以及 IO 问题;
所以要对一个系统进行优化,查找瓶颈来自哪个方面是关键,虽然看似是某一个子系统出现问题,其实有 可能是别的子系统导致的.
调优就像医生看病,因此需要你对服务器所有地方都了解清楚。
当系统出了问题,运行卡,如何快速找出以下进程:
1、找出系统中使用CPU最多的进程?
2、找出系统中使用内存最多的进程?
3、找出系统中对磁盘读写最多的进程?
4、找出系统中使用网络最多的进程?
查看CPU负载相关工具
查看CPU负载
uptime
[root@bogon ~]# uptime 17:09:27 //系统时间 up 2 days, //运行时间 4 users, //登录用户 load average: 0.00, 0.02, 0.33 // 系统负载,即任务队列的平均长度。三个数值分别为 1分 钟、5分钟、15分钟前到现在的平均值。
例1:找出前当系统中,CPU负载过高的服务器?
服务器1: load average: 0.15, 0.08, 0.01 1核
服务器2: load average: 4.15, 6.08, 6.01 1核
服务器3: load average: 10.15, 10.08, 10.01 4核
答案:服务器2 如果服务器的CPU为1核心,则load average中的数字 >=3 负载过高,如果服务器的CPU为 4核心,则load average中的数字 >=12 负载过高。
经验:单核心,1分钟的系统平均负载不要超过3,就可以,这是个经验值。
查看使用CPU情况
top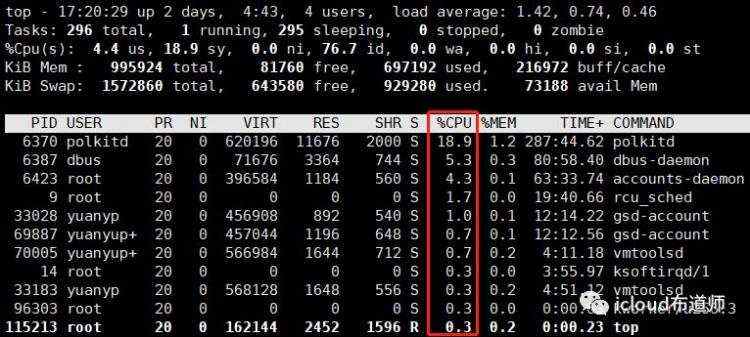
top 显示出现的每个列的含义分别为:
PID: 进程描述符
USER: 进程的拥有者
PR:进程的优先级
NI: nice level
SIZE: 进程拥有的内存(包括code segment + data segment + stack segment)
RSS: 物理内存使用
VIRT(virtul memory usage): 进程需要的虚拟内存大小
RES(resident memory usage): 常驻内存
SHARE: 和其他进程共享的物理内存空间
STAT:进程的状态,有 S=sleeping,R=running,T=stopped or traced,D=interruptible sleep(不可中断的睡眠状态),Z=zombie。
%CPU: CPU使用率
%MEM: 物理内存的使用
TIME: 进程占用的总共cpu时间
COMMAND:进程的命令
&& `top命令参数`f : 选择显示或隐藏对应的列的内容,进入后按a-z即可显示或隐藏o: 可以改变列的显示顺序,进入后按小写的 a-z 可以将相应的列向右移动,而大写的 A-Z 可以将相应的列向左移动。最后按回车键确定。F或O: 进入后按a-z可以将进程按照相应的列进行排序,选定排序列按回车键退出之后还可以按R对当前选定列进行排序倒转。k : 终止一个进程。系统将提示用户输入需要终止的进程PID,以及需要发送给该进程什么样的信号。一般的终止进程可以使用15信号;如果不能正常结束那就使用信号9强制结束该进程。默认值是信号15。在安全模式中此命令被屏蔽i: 忽略闲置和僵死进程。这是一个开关式命令q: 退出程序S: 切换到累计模式。s : 改变两次刷新之间的延迟时间。系统将提示用户输入新的时间,单位为s。如果有小数,就换算成ms。输入0值则系统将不断刷新,默认值是5 s。需要注意的是如果设置太小的时间,很可能会引起不断刷新,从而根本来不及看清显示的情况,而且系统负载也会大大增加r: 重新安排一个进程的优先级别。系统提示用户输入需要改变的进程PID以及需要设置的进程优先级值。输入一个正值将使优先级降低,反之则可以使该进程拥有更高的优先权。默认值是10。l: 切换显示平均负载和启动时间信息。即显示影藏第一行m: 切换显示内存信息。即显示影藏内存行t : 切换显示进程和CPU状态信息。即显示影藏CPU行c: 切换显示命令名称和完整命令行。 显示完整的命令。 这个功能很有用。M : 根据驻留内存大小进行排序。P: 根据CPU使用百分比大小进行排序。T: 根据时间/累计时间进行排序。W: 将当前设置写入~/.toprc文件中。这是写top配置文件的推荐方法h或者? 显示帮助画面,给出一些简短的命令总结说明--------------------- 作者:weixin_42500678 来源:CSDN 原文:https://blog.csdn.net/weixin_42500678/article/details/80754737
cat proc/cpuinfo[root@bogon ~]# cat proc/cpuinfo processor : 0 #系统中逻辑处理核的编号,逻辑CPU个数 1个vendor_id : GenuineIntel #CPU制造商 因特尔”原厂cpu family : 6 #CPU产品系列代号model : 158 #CPU属于其系列中的哪一代的代号model name : Intel(R) Core(TM) i5-7400 CPU @ 3.00GHz #CPU属于的名字及其编号、标称主频stepping : 9 # CPU属于制作更新版本microcode : 0x84cpu MHz : 2999.995 #CPU的实际使用主频cache size : 6144 KB #CPU二级缓存大小physical id : 0 #单个CPU的标号siblings : 2 #单个CPU逻辑物理核数core id : 0 #当前物理核在其所处CPU中的编号,这个编号不一定连续 cpu cores : 2 #该逻辑核所处CPU的物理核数apicid : 0 #用来区分不同逻辑核的编号,系统中每个逻辑核的此编号必然不同,此编号不一定连续initial apicid : 0fpu : yesfpu_exception : yescpuid level : 22wp : yesflags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon nopl xtopology tsc_reliable nonsop_tsc eagerfpu pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer as xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch ibrs ibpb stibp fsgsbase tsc_adjust bmi1 av2 smep bmi2 invpcid mpx rdseed adx smap clflushopt xsaveopt xsavec arat spec_ctrl intel_stibp arch_capablitiesbogomips : 5999.99 clflush size : 64cache_alignment : 64address sizes : 43 bits physical, 48 bits virtualpower management:processor : 1vendor_id : GenuineIntelcpu family : 6model : 158model name : Intel(R) Core(TM) i5-7400 CPU @ 3.00GHzstepping : 9microcode : 0x84cpu MHz : 2999.995cache size : 6144 KBphysical id : 0siblings : 2core id : 1cpu cores : 2apicid : 1initial apicid : 1fpu : yesfpu_exception : yescpuid level : 22wp : yesflags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon nopl xtopology tsc_reliable nonsop_tsc eagerfpu pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer as xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch ibrs ibpb stibp fsgsbase tsc_adjust bmi1 av2 smep bmi2 invpcid mpx rdseed adx smap clflushopt xsaveopt xsavec arat spec_ctrl intel_stibp arch_capablitiesbogomips : 5999.99clflush size : 64cache_alignment : 64address sizes : 43 bits physical, 48 bits virtualpower management:
ps -aux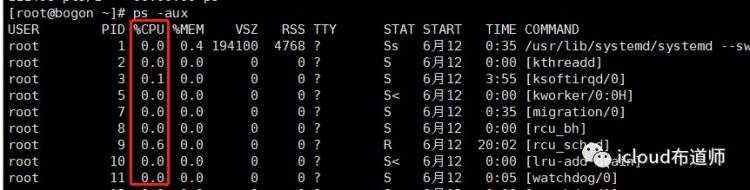
扩展:孤儿进程与僵尸进程
概念在unix/linux中,正常情况下,子进程是通过父进程创建的,子进程在创建新的进程。子进程的结束和父进程的运行是一个异步过程,即父进程永远无法预测子进程 到底什么时候结束。 当一个 进程完成它的工作终止之后,它的父进程需要调用wait()或者waitpid()系统调用取得子进程的终止状态。
孤儿进程:一个父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集工作。
僵尸进程:一个进程使用fork创建子进程,如果子进程退出,而父进程并没有调用wait或waitpid获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中。这种进程称之为僵死进程。
危害孤儿进程是没有父进程的进程,孤儿进程这个重任就落到了init进程身上,init进程就好像是一个民政局,专门负责处理孤儿进程的善后工作。每当出现一个孤儿进程的时候,内核就把孤 儿进程的父进程设置为init,而init进程会循环地wait()它的已经退出的子进程。这样,当一个孤儿进程凄凉地结束了其生命周期的时候,init进程就会代表党和政府出面处理它的一切善后工作。因此孤儿进程并不会有什么危害。
如果进程不调用wait waitpid的话, 那么保留的那段信息就不会释放,其进程号就会一直被占用,但是系统所能使用的进程号是有限的,如果大量的产生僵死进程,将因为没有可用的进程号而导致系统不能产生新的进程. 此即为僵尸进程的危害,应当避免。
查看MEMORY运行工具
查看内存使用情况
free -m
&& `注解 `-----Mem: 物理内存 -total 容量总数 -used 已使用容量 -free 空余容量 -shared buffers 缓冲,通常缓冲元数据 -cached 缓存,通常缓存数据------Swap: 交换空间 2047 容量总数 0 已使用容量 2047 空余容量 -buffers 缓存从磁盘读出的内容 -cached 缓存需要写入磁盘的内容 当物理内存不够用的时候,内核会把非活跃的数据清空。
cat proc/meminfo
[root@bogon ~]# cat proc/meminfo MemTotal: 995924 kBMemFree: 79608 kBMemAvailable: 73316 kBBuffers: 36 kBCached: 105536 kBSwapCached: 131808 kBActive: 227348 kB #活跃内存,指进程一直读写的内存空间 Inactive: 387412 kB # 非活跃内存 //注:当内存不够用时,kernel总是把不活跃的内存交换到swap空间。如果inactive内存多时,加 swap空间可以解决问题,而active多,则考虑加内存
按照内存使用大小排序进程
[root@bogon ~]# ps aux --sort rssUSER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMANDroot 2 0.0 0.0 0 0 ? S 6月12 0:00 [kthreadd]root 3 0.1 0.0 0 0 ? S 6月12 4:00 [ksoftirqd/0]root 5 0.0 0.0 0 0 ? S<6月12 0:00 [kworker/0:0H]root 7 0.0 0.0 0 0 ? S 6月12 0:35 [migration/0]root 8 0.0 0.0 0 0 ? S 6月12 0:00 [rcu_bh]root 9 0.6 0.0 0 0 ? R 6月12 20:29 [rcu_sched]root 10 0.0 0.0 0 0 ? S< 6月12 0:00 [lru-add-drain]
查看IO相关工具
IO调优相关查看工具
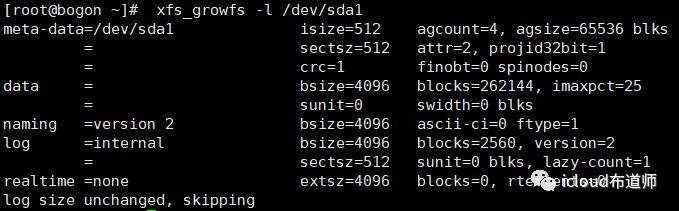
查看系统块大小
[root@bogon ~]# xfs_growfs -l /dev/sda1
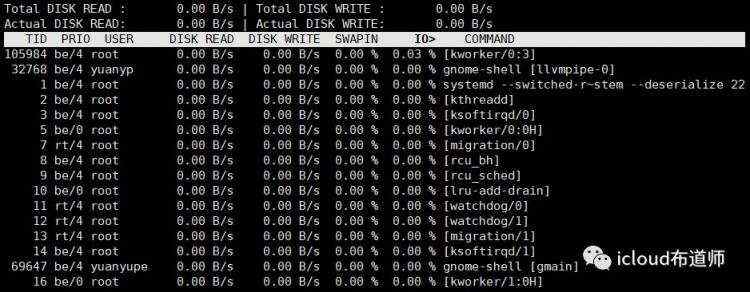
iotop
&& `查看使用过高io的进程`[root@bogon ~]# yum install iotop -y[root@bogon ~]# iotop 选项: -o:只显示有io操作的进程 -b:批量显示,无交互,主要用作记录到文件。 -n NUM:显示NUM次,主要用于非交互式模式。 -d SEC:间隔SEC秒显示一次。 -p PID:监控的进程pid。 -u USER:监控的进程用户iotop常用快捷键: <- ->:左右箭头:改变排序方式,默认是按IO排序。 r:改变排序顺序。 o:只显示有IO输出的进程。 p:进程/线程的显示方式的切换。 a:显示累积使用量。 q:退出
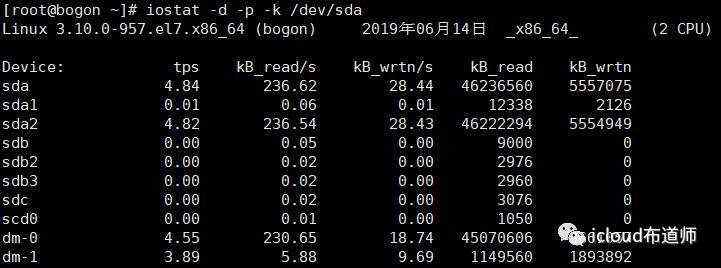
iostat
&& `常用参数`-d 仅显示磁盘统计信息 -k 以K为单位显示每秒的磁盘请求数,默认单位块. -p device | ALL 用于显示块设备及系统分区的统计信息&& `查看`[root@bogon ~]# iostat -d -p -k dev/sdaLinux 3.10.0-957.el7.x86_64 (bogon) 2019年06月14日 _x86_64_ (2 CPU)Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtnsda 4.84 236.62 28.44 46236560 5557075sda1 0.01 0.06 0.01 12338 2126sda2 4.82 236.54 28.43 46222294 5554949sdb 0.00 0.05 0.00 9000 0sdb2 0.00 0.02 0.00 2976 0sdb3 0.00 0.02 0.00 2960 0sdc 0.00 0.02 0.00 3076 0scd0 0.00 0.01 0.00 1050 0dm-0 4.55 230.65 18.74 45070606 3661057dm-1 3.89 5.88 9.69 1149560 1893892注: 每列含意:- kB_read/s 每秒从磁盘读入的数据量,单位为K.- kB_wrtn/s 每秒向磁盘写入的数据量,单位为K. - kB_read 读入的数据总量,单位为K. - kB_wrtn 写入的数据总量,单位为K.
&& `测试`[root@bogon ~]# dd if=/dev/zero of=test.xxx bs=10M count=1000;sync[root@bogon ~]# iostat -d -p -k dev/sda 然后查看变化
查看NETWORK相关工具
NETWORK相关查看工具
netstat
[root@localhost ~]# netstat -tlunpActive Internet connections (only servers)Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 127.0.0.1:9000 0.0.0.0:* LISTEN 1342/php-fpm: maste tcp 0 0 0.0.0.0:3306 0.0.0.0:* LISTEN 1861/mysqld tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN 1/systemd tcp 0 0 0.0.0.0:45043 0.0.0.0:* LISTEN 16719/rpc.statd tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1345/sshd tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 2044/master tcp6 0 0 :::111 :::* LISTEN 1/systemd tcp6 0 0 :::80 :::* LISTEN 6491/httpd tcp6 0 0 :::22 :::* LISTEN 1345/sshd tcp6 0 0 ::1:25 :::* LISTEN 2044/master tcp6 0 0 :::50304 :::* LISTEN 16719/rpc.statd udp 0 0 0.0.0.0:743 0.0.0.0:* 16680/rpcbind udp 0 0 127.0.0.1:783 0.0.0.0:* 16719/rpc.statd udp 0 0 0.0.0.0:111 0.0.0.0:* 1/systemd udp 0 0 0.0.0.0:40065 0.0.0.0:* 16719/rpc.statd udp6 0 0 :::32967 :::* 16719/rpc.statd udp6 0 0 :::743 :::* 16680/rpcbind
nload
[root@localhost ~]# yum install nload

在另一台xshell上输入安装命令,再查看[root@localhost ~]# yum install rsync
nethogs
相当于windows的360监控图[root@localhost ~]# yum install nethogs在另一端产生数据wget http://issuecdn.xxxxxxxxxxxxxxxxxxxxxxx

查看系统整体状况
VMSTAT
vmstat
:命令是最常见的Linux/Unix监控工具,可以展现给定时间间隔的服务器的状态值,包括 服务器的CPU使用率,MEM内存使用,VMSwap虚拟内存交换情况,IO读写情况。 使用vmstat可以看到整个机器的CPU,内存,IO的使用情况,而不是单单看到各个进程的CPU使 用率和内存使用率。 比top命令节省资源。
注:当机器运行比较慢时,建议大家使用vmstat查看运行状态,不需要使用top,因top使用资源 比较多。
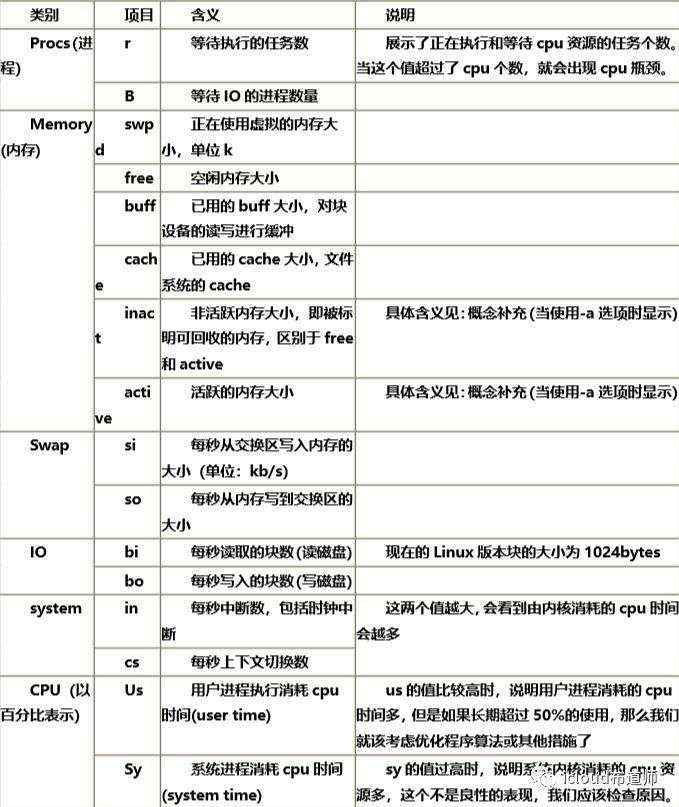
[root@localhost ~]# vmstatprocs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 2 0 95848 89344 124 424508 0 0 0 1 1 1 1 0 99 0 0

每一列参数作用: r 运行状态的进程个数 。展示了正在执行和等待cpu资源的任务个数。当这个值超过了cpu个数, 就会出现cpu瓶颈。 b 不可中断睡眠 正在进行i/o等待--阻塞状态的进程个数 进程读取外设上的数据,等待时free 剩余内存,单位是KB buffers #内存从磁盘读出的内容cached #内存需要写入磁盘的内容si swapin swap换入到内存 so swapout 内存换出到swap 换出的越多,内存越不够用bi blockin 从硬盘往内存读。 单位是块。 把磁盘中的数据读入内存 bo blockout 从内存拿出到硬盘 (周期性的有值) 写到硬盘 #判断是读多还是写多,是否有i/o瓶颈in 系统的中断次数,cpu调度的次数多 cs 每秒的上下文切换速度 CPU上下文切换--程序在运行的时候,CPU对每个程序切换的过程。
终





 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 
