作者:关圣钊 | 来源:互联网 | 2023-10-11 18:44
“ 本文分析了Linux内核连接跟踪的关键实现”
连接跟踪(也叫会话管理)是状态防火墙关键核心,也是很多网元设备必不可少的一部分。各厂商的实现原理基本雷同,只是根据各自的业务进行修改和优化。其中,还有不少厂商干脆是基于Linux内核实现的。下面,我们就来看看Linux内核中连接跟踪的几个要点。
注:本文对应的Linux源码为最新的5.9.12
00
基础知识
-
一个连接由两个tuple组成,分别代表两个方向的报文信息。
-
一个tuple一般由报文的五元组构成,分别是源地址、目的地址,源端口、目的端口和协议号(四层)。
-
连接跟踪表一般为hash表。该表可能是全局的,也可能是per cpu的,Linux内核选择的是全局表。
-
每个连接根据自己的状态,都有自己的生命周期,到期会销毁。
-
网元设备一般会在连接中增加扩展,来实现带状态的业务。
01
—
连接跟踪的匹配和创建
对于拥有连接跟踪的网元设备来说,数据报文一定是先尝试匹配已有连接,如果找到对应的连接则报文属于该连接,如果没有找到,则创建新连接。所以,连接的匹配和创建一般都是相邻的。
nf_conntrack_in是连接匹配的入口函数,其会被netfitler处理brdige(etables)、ipv4和ipv6的hook函数调用。
在nf_conntrack_in中,
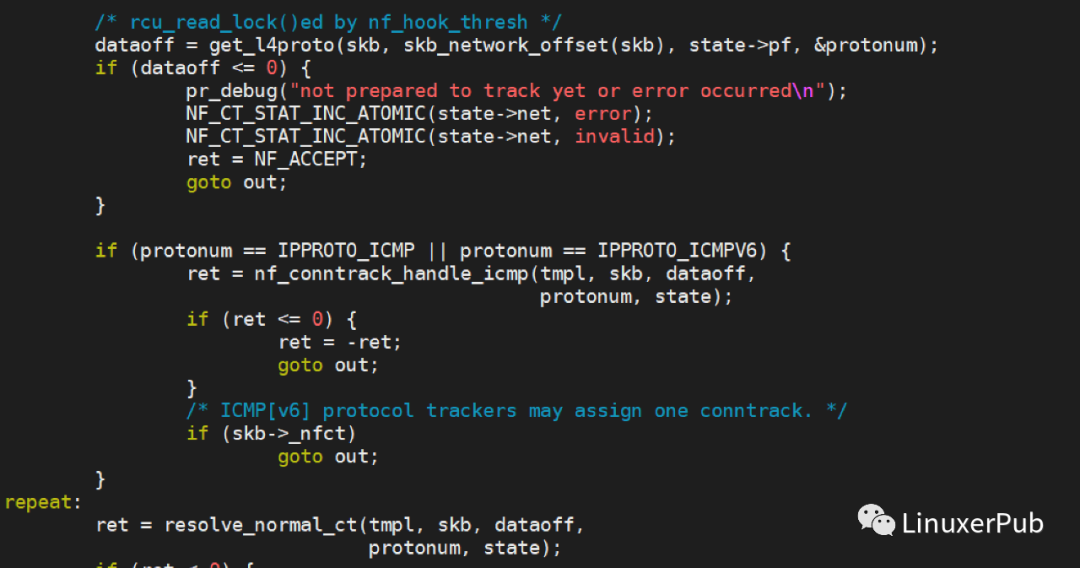
这里先调用get_l4proto,根据三层协议获取四层协议号和数据偏移。然后,调用resolve_normal_ct进行连接的匹配和创建。
在resolve_normal_ct中,

首先调用nf_ct_get_tuple根据报文生成这个方向的tuple,然后调用__nf_conntrack_find_get通过tuple进行连接的查找。如果没有找到,则调用init_conntrack生成新的连接。
也许有的同学会有疑问,在基础知识小节中,tuple是包含源端口和目的端口。那么如果报文不是UDP或者TCP,没有源端口和目的端口怎么办?答案很简单,内核会根据4层协议使用不同字段来填充tuple。在nf_ct_get_tuple中,有如下代码:

以ICMP报文为例,见icmp_pkt_to_tuple

所以tuple的五元组只是一种粗略说法,实际上内核会根据不同协议填充不同字段。因为tuple的匹配时包含4层协议号本身,所以这样做完全没有问题。
连接的查找比较简单,根据tuple确定hash桶,然后遍历桶中元素查找拥有相等tuple的连接。

连接的创建同样简单,在init_conntrack中,

首先调用__nf_conntrack_alloc申请一块conntrack的内存,然后在根据需求增加相应的扩展(extension),如这里的timeout_ext,acct_ext,tstamp_ext等等。在很多厂商的实现中,都会把自己的业务数据直接保存在conntrack结构中,这就造成了conntrack的结构越来越大,且会保存一些没有必要的数据。比如一共有三个业务功能的数据保存在conntrack中,但实际上用户只使用了功能1,结果功能2和功能3虽然没有使用,但依然占用了内存。同时,越来越大的conntrack结构也越来越难以维护。Linux内核最早也是采取的这种方式(简单直接),后来其抽象了nf_ct_ext结构用于做业务扩展。conntrack不再直接保存扩展数据,当业务扩展被启用时,会动态申请nf_ct_ext,并追加到conntrack的扩展结构中。
因为本文只讨论连接跟踪,所以在此不细述conntrack的extension了。以后有机会再和大家分享这块儿内容。
在init_conntrack中的结尾,还有一块儿代码值得大家注意:

前两个语句,增加了conntrack的引用计数,然后将conntrack添加到unconfirmed_list中。

这里的unconfirmed list是一个per cpu 变量。
02
—
连接如何插入全局连接跟踪表
前一节中,我们看到了内核创建了一个新的连接conntrack,并将其插入到unconfirmed list中。那么为什么不直接将其插入到全局连接跟踪表中呢?其原因有二:
-
在基础知识一节中,我们提到一个conntrack有两个tuple。当我们创建conntrack时,实际上只有一个方向的报文,也就只能够生成这个方向的tuple。虽然我们可以根据tuple的定义,将当前方向的tuple做个反向处理来得到反向tuple。但这里会有一个问题,当有NAT规则时,此时此刻我们并不知道后面会如何进行NAT处理,生成的反向tuple自然不正确。那么,是否可以先插入一个tuple呢?答案也是否定的。这可能会引发并发竞争的问题。试想,一个连接的两个方向的报文,有可能由两个CPU进行处理,他们都根据当前报文生成了conntrack和tuple并插入到全局表中。这就意味着同一个连接被插入表两次,自然是一个错误。如果要增加这种情况的检查,逻辑会更加复杂。
-
在创建连接的时候,属于比较早期的阶段,很有可能在后面的处理中报文会被丢弃,比如命中了防火墙drop规则等等。如果先把连接插入了全局表,到时候还要进行删除处理,这无疑是一种浪费。Linux内核会在最后阶段,才会把连接插入到全局表中。
基于以上原因,Linux内核会在最后时刻才会将新建的conntrack插入到全局表中。那么这个最后的时刻是什么时候呢?Linux内核的连接跟踪是由netfilter模块的功能,而netfilter的原理主要是通过五个阶段(prerouting、forward、postrouting、localin和localout),并在每个阶段根据优先级执行hook函数或者规则。关于这块儿的资料已经很多,在此不做重复说明。
以IPv4报文为例,

其分别在postrouting和localin两个阶段,以优先级NF_IP_PRI_CONNTRACK_CONFIRM(INT_MAX)来调用hook函数ipv4_confirm。这就保证了无论是转发的,本机发出的(最后也会走到postrouting),还是发给本机的,都会在最后阶段(也就是即将离开netfilter模块)时执行ipv4_confirm。而ipv4_confirm经过层层还是会最终调用到__nf_conntrack_confirm,其负责将conntrack插入到全局表中。
前文说过,一个连接有两个tuple,根据不同tuple计算的hash bucket自然也不同,也就是说,内核需要将conntrack插入到了两个bucket中。前面在__nf_conntrack_find_get中进行连接查找匹配时,使用的是rcu_read_lock进行保护。现在要进行插入操作(写操作),自然要使用锁了。在老版本内核中,全局连接表的写入操作使用了全局唯一一个spinlock,这无疑降低并发性能。后来内核对此做了改进,使用了CONNTRACK_LOCKS(1024)个锁,来减小锁的粒度。
对于一个连接涉及两把锁的时候,就需要注意上锁的顺序,不然就会引起死锁。比如连接1上锁顺序是lock A,lock B,而连接2上锁顺序则是lock B,lock A。当连接1持有了lock A,然后尝试获取lock B,连接2持有了lock B,然后尝试获取lock A。这时,两个CPU就陷入了死锁状态。为了避免这种问题,就需要保证上锁的顺序,即使是不同连接,也要使用同一个顺序上锁。为此,内核特意封装了一个函数解决这一问题。

上面代码中h1和h2分别对应conntrack两个tuple计算的hash值,分别与CONNTRACK_LOCKS进行模操作得到两个锁的索引。然后比较h1和h2,永远保证先对索引小的lock进行上锁,然后再锁索引大的lock。其中特殊情况是两个锁索引相同时,那么只锁一次。
然后先检查是否已经有CPU插入了相同连接,

如果两个tuple中的任何一个已经被插入,则认为已有CPU插入了相同连接,则放弃当前连接的插入。
通过一系列检查后,__nf_conntrack_confirm调用__nf_conntrack_hash_insert把conntrack两个tuple插入到全局表中。
03
—
连接跟踪的生命周期
如何处理淘汰(或者叫做删除)过期连接,最直接的做法就是为每个连接增加一个定时器,定时器过期时间即为连接的生命周期。早期内核版本也是采取的这一方式。但随着支持的并发连接数量的增多,过期timer的数量也成为了一个巨大的值。这种海量的timer,对timer机制是一个挑战,同时每个timer(struct timer_list)会占用80个字节(x86_64)。在海量的连接下,定时器内存的消耗也不容忽视。于是,内核做了一个优化,使用了一个u32 变量timeout作为conntrack的过期时间。但是,没有了定时器触发,如何判定conntrack过期呢?
首先,在nf_conntrack_in函数中调用nf_conntrack_handle_packet根据不同协议处理报文,更新连接状态。以TCP报文为例,会调用nf_conntrack_tcp_packet进行处理。

这里根据不同的TCP状态确定不同的timeout值,然后调用nf_ct_refresh_acct设置到conntrack上。
然后,在连接查找匹配时,即____nf_conntrack_find函数中。

在遍历桶中连接时,在匹配前调用nf_ct_is_expired判断连接是否过期,如果过期则调用nf_ct_gc_expired淘汰该连接。这样就保证了大部分过期连接可以得到及时淘汰。
如果在最坏的情况下,某个桶始终不会被遍历时,那个桶中的连接如何淘汰呢?为应对这种情况,内核还有一个补救措施 —— 定义了一个deferable work,gc_worker。其周期性(1s)执行,按顺序遍历全局连接表,淘汰过期连接。
以上三点是连接跟踪中比较大块和重要的部分,除此之外,还有关联连接、扩展支持等。内核基于连接跟踪又实现了很多有趣实用的功能,如NAT、ALG、SynProxy等。希望后面有机会跟大家分享更多的内核知识,争取把这个做成系列文章。









 京公网安备 11010802041100号
京公网安备 11010802041100号