什么是CMA CMA是reserved的一块内存,用于分配连续的大块内存。当设备驱动不用时,内存管理系统将该区域用于分配和管理可移动类型页面;当设备驱动使用时,此时已经分配的页面需要进行迁移,又用于连续内存分配 ;其用法与DMA子系统结合在一起充当DMA的后端,具体可参考《没有IOMMU的DMA操作》。
数据结构 struct cma {#ifdef CONFIG_CMA_DEBUGFS #endif
bitmap来管理其内存的分配,0表示free,1表示已经分配。 如果order_per_bit等于0,表示按照一个一个page来分配和释放,如果order_per_bit等于1,表示按照2个page组成的block来分配和释放,以此类推。 count说明该cma_areas 内存有多少个page。它和order_per_bit一起决定了bitmap指针指向内存的大小。 base_pfn定义了该cma_areas 的起始page frame number,base_pfn和count一起定义了该cma_areas 在内存中的范围。 from loyenwang
CMA区域 cma_areas 的创建 CMA区域的创建有两种方法,一种是通过dts的reserved memory,另外一种是通过command line参数和内核配置参数。
reserved-memory {for contiguous allocations */"shared-dma-pool" ;
device tree中可以包含reserved-memory node,系统启动的时候会打开rmem_cma_setup
RESERVEDMEM_OF_DECLARE(cma, "shared-dma-pool", rmem_cma_setup);
cma=nn[MG]@[start[MG][-end[MG]]]
static int __init early_cma(char *p)"%s(%s)\n" , __func__, p);if (*p != '@' ) {if base and limit are not assigned,set limit to high memory bondary to use low memory.return 0;if (*p != '-' ) {return 0;return 0;"cma" , early_cma);
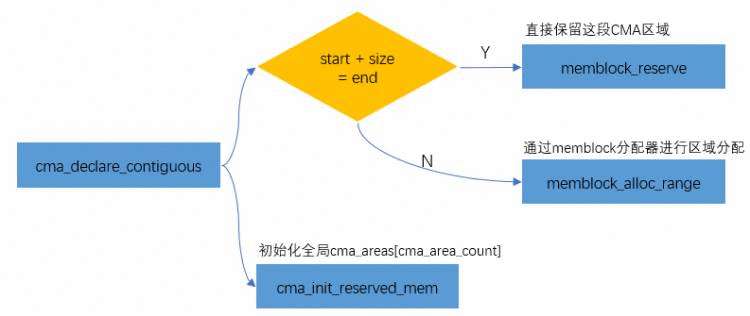
系统在启动的过程中会把cmdline里的nn, start, end传给函数dma_contiguous_reserve,流程如下:
setup_arch--->arm64_memblock_init--->dma_contiguous_reserve->dma_contiguous_reserve_area->cma_declare_contiguous
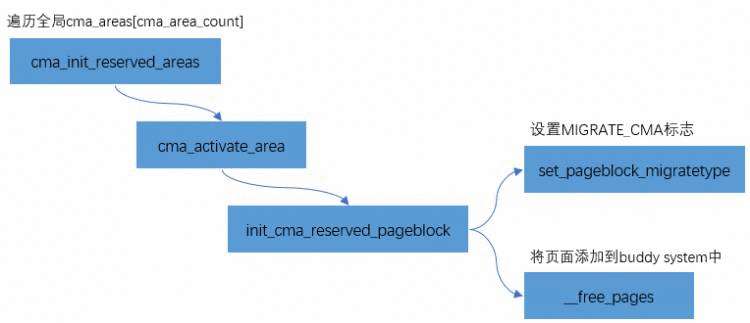
将CMA区域添加到Buddy System 为了避免这块reserved的内存在不用时候的浪费,内存管理模块会将CMA区域添加到Buddy System中,用于可移动页面的分配和管理。CMA区域是通过cma_init_reserved_areas接口来添加到Buddy System中的。
static int __init cma_init_reserved_areas(void)for (i = 0; i < cma_area_count; i++) {if (ret)return ret;return 0;
其实现比较简单,主要分为两步:
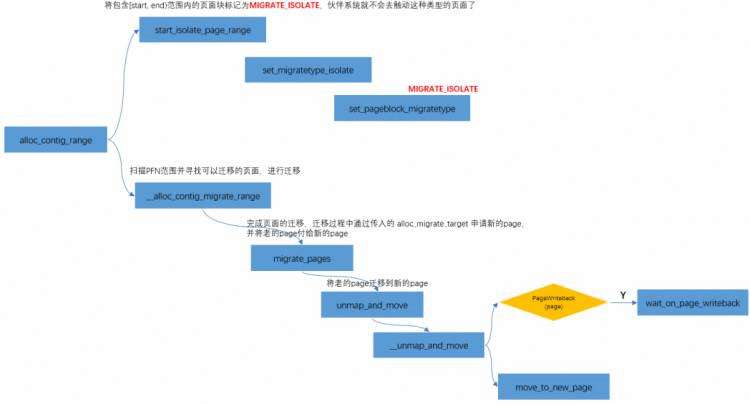
通过__free_pages将页面添加到buddy system中 CMA分配 《没有IOMMU的DMA操作》里讲过,CMA是通过cma_alloc分配的。cma_alloc->alloc_contig_range(..., MIGRATE_CMA ,...),向刚才释放给buddy system的MIGRATE_CMA类型页面,重新“收集”过来。
用CMA的时候有一点需要注意 :
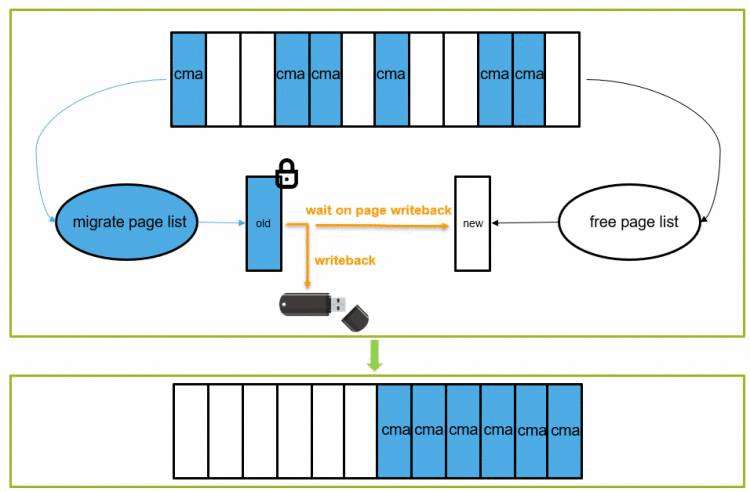
也就是上图中黄色部分的判断。CMA内存在分配过程是一个比较“重”的操作,可能涉及页面迁移、页面回收等操作,因此不适合用于atomic context。比如之前遇到过一个问题,当内存不足的情况下,向U盘写数据的同时操作界面会出现卡顿的现象,这是因为CMA在迁移的过程中需要等待当前页面中的数据回写到U盘之后,才会进一步的规整为连续内存供gpu/display使用,从而出现卡顿的现象。




![基于Linux开源VOIP系统LinPhone[四]](https://img.php1.cn/3cd4a/1eebe/cd5/ed19db63ee478b98.png)







 京公网安备 11010802041100号
京公网安备 11010802041100号