作者:Q小泓别_431 | 来源:互联网 | 2023-08-06 19:07
目录
一、编程语言部分
1、JavaSE
2、Scala
二、大数据阶段
1、Linux(基本操作)
2、Hadoop(重点中的重点)
3、Zookeeper
4、Hive(重点)
5、Flume
6、Kafka(重点)
7、HBase(重点)
8、Spark(重点中的重点)
9、Flink(重点中的重点)
三、项目阶段
四、机器学习
五、书籍
后续也会继续更新~~~~~~~~~~~
大数据学习指南
本人是按照这个学习路线来的,大数据零基础学习,已找到大数据开发工作。
要从事计算机行业的工作,不管是什么工作,开发、测试、还是算法等,都是要有一门自己比较熟练的编程语言,编程语言可以是C语言、Java、C++等,只要是和你后续工作所相关的就可以(后续用到其他语言的话,你有一门语言基础了,学起来就快了)。
大数据所使用的编程语言主要是Java、Scala、Python,使用最多的还是Java,所以从JavaSE入手是最好的选择,Scala主要是后续Spark、Flink使用,在学习Spark之前把Scala学习一波,是很nice的,因为有了JavaSE的基础,学习Scala就快了,Python可以工作中用到了再学习。
给的视频链接都是b站的,因为百度云盘链接太容易失效了,而且b站上面的视频链接下面一般都有配套的文档资料,所以就不用担心没有配套资料了。
一、编程语言部分
1、JavaSE
相信学习过Java的人基本都听过刘意和毕向东,这两个老师的课程简直就是经典,讲解细致,而且理论+实战结合的很好,初学者入门学习的一剂良药,而且b站也有免费资源,最近刘意老师也出了2019年版的JavaSE视频,也给出了链接,不过15版本已经很经典了,有需要的话也可以看看19版本的
刘意JavaSE(2015版)
刘意JavaSE(2019-IDEA版)
毕向东JavaSE
2、Scala
Scala是一门多范式 (multi-paradigm) 的编程语言,Scala支持面向对象和函数式编程,最主要的是后续Spark的内容需要用到Scala,所以前面学习了JavaSE,到Spark学习之前,再把Scala学习一波,美滋滋,而且Scala可以和Java进行无缝对接,混合使用,更是爽歪歪。后续Spark学习时基本都是用的Scala,也可能是和Java结合使用,所以Spark之前建议还是先学一波Scala,而且Scala用起来真是很舒服(wordcount一行代码搞定),适合迭代式计算,对数据处理有很大帮助,不过Scala看代码很容易看懂,但是学起来还是挺难的,比如样例类(case class)用起来真是nice,但是隐式转换学起来就相对比较难。学习Scala的建议:1. 学习scala 特有的语法,2. 搞清楚scala和java区别,3. 了解如何规范的使用scala。Scala对学习Spark是很重要的(后面Flink也是要用),虽然现在很多公司还是用Java开发比较多,而且Spark是Scala写的,如果要读源码,会Scala还是很重要的(至少要看得懂代码)。
Scala主要重点包括:隐式转换和隐式参数、模式匹配、函数式编程。这里我看的是尚硅谷韩老师的Scala视频,韩老师讲的真的很不错,五星推荐,哈哈。
也许Python也是需要的,但是学习阶段,可能用Java还是比较多,面试也基本都是问Java相关的内容,所以Python后续工作会用到的话,再看看Python的内容吧。
尚硅谷韩老师Scala
二、大数据阶段
大数据学习路线:Linux -> Hadoop -> Zookeeper -> Hive -> Flume -> Kafka -> HBase -> Scala -> Spark -> 项目 - > Flink(Flink可以后续学习的)
1、Linux(基本操作)
一般我们使用的都是虚拟机来进行操作,所以要安装VM( Virtual Machine),我使用的是CentOS,所以VM和CentOS都要跟着安装好,跟着视频操作,一定要动手实践,将一些Linux基本命令熟练掌握,一些VIM编辑器的命令也要会用,做相应的一些配置,使用SecureCRT来做远程登录操作(也可以使用其他的,自己顺手就行)。再强调一遍,基本操作命令尽量熟练一点,如果一下记不住,打印一些常用的,自己看看,多用多实践,慢慢就会用了。还有一些软件包的下载安装卸载等,跟着操作一遍,熟悉下,后续都会使用,Shell编程可以后续补。
视频:
如果想了解下shell(后面乌班图的可以选择不看)
没有shell讲解
2、Hadoop(重点中的重点)
Hadoop是一个分布式系统基础框架,用于主要解决海量数据的存储和海量数据的分析计算问题,也可以说Hadoop是后续整个集群环境的基础,很多框架的使用都是会依赖于Hadoop。主要是由HDFS、MapReduce、YARN组成。这个部分安装Hadoop,Hadoop的三个主要组成部分是重点,对他们的概念要理解出来,知道他们是做什么的,搭建集群环境,伪分布式模式和完全分布式模式的搭建,重要的是完全分布式的搭建,这些部分一定要自己动手实践,自己搭建集群,仔细仔细再仔细,Hadoop的NameNode,DataNode,YARN的启动关闭命令一定要知道,以及他们的启动关闭顺序要记住,不要搞混。后续视频会有一些案例操作,跟着写代码,做测试,把基本环境都配置好,后续这个集群(完全分布式需要三台虚拟机)要一直使用。
视频:
我开始看过的版本
第二个看过的版本
2019版本
3、Zookeeper
Zookeeper是一个开源的分布式的,为分布式应用提供协调服务的Apache项目。分布式安装ZK,对ZK有一定的了解就可以了,了解它的应用场景,以及内部原理,跟着做一些操作,基本上有一些了解即可。
视频:
我看过的版本
尚硅谷周洋版本(听说挺好)
2019版本
4、Hive(重点)
Hive是基于Hadoop的数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。Hive的安装,它的数据类型,以及它的数据定义、数据操作有较好的了解,怎么操作表(创建表、删除表,创建什么类型的表,他们有什么不同),怎么操作数据(加载数据,下载数据,对不同的表进行数据操作),对数据的查询一定要进行实践操作,以及对压缩方式和存储格式要有一些了解,用到时不懂也可以去查,最好是能理解清楚。这部分有什么面试可能会问,所以视频后续的面试讲解可以看看,理解清楚。
视频:
我开始看过的版本
第二个看过的版本
2019版本
5、Flume
Flume是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。对于Flume,对它的组成架构,以及对Flume Agent的内部原理要理解清楚,Source、Channel、Sink一定要知道它们的各种类型以及作用,有哪些拓扑结构是常见常用的,例如一对一,单Source、多Channel、多Sink等,它们有什么作用,要理解清楚。还有一个重点,就是对Flume的配置文件一定要了解清楚,不懂的可以上官网查看案例,对于不同的情况,它的配置文件要做相应的修改,才能对数据进行采集处理,视频中的实践案例一定要跟着做。
视频:
我开始看过的版本
第二个看过的版本
2019版本
6、Kafka(重点)
Kafka是一个分布式消息队列,用来缓存数据的。比如说实时计算中可以通过Flume+Kafka对数据进行采集处理之后,Spark Streaming再使用Kafka相应的Topic中的数据,用于后续的计算使用。对于Kafka,要理解Kafka的架构,什么是Kafka,为什么需要Kafka,应用场景。基本的命令行操作要掌握,比如怎么创建删除Topic,怎么通过生产者生成数据,消费者怎么消费数据等基本操作,官网也是有一些案例可以查阅的。
视频:
我看过的版本
2019版本
7、HBase(重点)
HBase是一个分布式的、基于列存储的开源数据库。HBase适合存储PB级别的海量数据,也可以说HBase是很适合大数据的存储的,它是基于列式存储数据的,列族下面可以有非常多的列,列族在创建表的时候就必须指定。所以对HBase的数据结构要有一定的理解,特别是RowKey的设计部分(因为面试被问到过,咳咳,所以点一下),对于它的原理要了解,一些基本操作也要都会,比如创建表,对表的操作,基本的API使用等。
视频:
我看过的版本
2019版本
8、Spark(重点中的重点)
Spark是快速、易用、通用的大数据分析引擎。一说到Spark,就有一种哪哪都是重点感觉,哈哈。
Spark的组成可以看下图
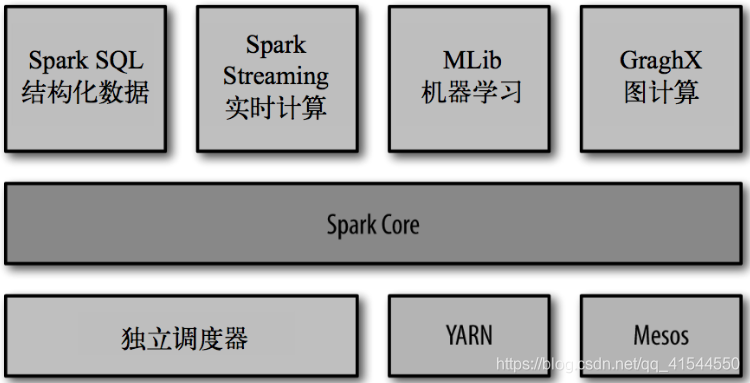
Spark是基于内存计算的,对于数据的处理速度要比MapReduce快很多很多,而且数据挖掘这些都是要对数据做迭代式计算,MapReduce对数据的处理方式也不适合,而Spark是可以进行迭代式计算,很适合数据挖掘等场景。Spark的Spark SQL能够对结构化数据进行处理,Spark SQL的DataFrame或DataSet可以作为分布式SQL查询引擎的作用,可以直接使用Hive上的表,对数据进行处理。Spark Streaming主要用于对应用场景中的实时流数据进行处理,支持多种数据源,DStream是Spark Streaming的基础抽象,由一系列RDD组成,每个RDD中存放着一定时间段的数据,再对数据进行处理,而且是基于内存计算,速度快,所以很适合实时数据的处理。Spark MLlib提供常见的机器学习(ML)功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据 导入等额外的支持功能。对Spark的核心组件、部署模式(主要是Standalone模式和YARN模式)、通讯架构、任务调度要有一定了解(面试问到了可以说一波),Spark Shuffle要好好理解,还有内存管理要知道,对Spark的内核原理一定要好好理解,不仅面试可能要用,以后工作也是有帮助的,
视频:
我最开始看过的版本
第二个看过的版本
2019版本
9、Flink(重点中的重点)
Flink是一个框架和分布式处理引擎,用于对无界(有开始无结束)和有界(有开始有结束)数据流进行有状态计算。现在主要是阿里这种大公司使用的比较多,中国很多公司使用的还是Spark居多,而且Flink基本上都是和Spark很多功能大体上一样的,但是以后Flink和Spark孰强孰弱还有待时间的考验,不过Flink近几年越来越火了这是事实,所以如果有时间有精力的话,可以学一学Flink相关的内容也是很不错的。Spark和Flink主要都是在数据处理方面应用,在数据处理方面的话,离线数据处理:Flink暂时比不上Spark,Spark SQL优点在于可以和Hive进行无缝连接,Spark SQL可以直接使用Hive中的表;Flink暂时做不到这一步,因为官方不支持这一操作,Flink只能将数据读取成自己的表,不能直接使用Hive中的表。对于实时数据的处理:Flink和Spark可以说是平分秋色吧,而且Flink是以事件为驱动对数据进行处理,而Spark是以事件为驱动对数据进行处理,在一些应用场景中,也许Flink的效果比Spark的效果还要好些,因为Flink对数据更加的敏感。比如一秒钟如果触发了成千上万个事件,那么时间驱动型就很难对数据做细致的计算,而事件驱动型可以以事件为单位,一个个事件进行处理,相比而言延迟更低,处理效果更好。还是那句话,虽然现在使用的公司较少,但是有时间接触学习下,也是没有坏处的。
视频:
我看的版本(基础+项目)
三、项目阶段
其实尚硅谷的视频里面有很多大数据相关的项目,而且都是文档配代码的,学习期间可以跟着视频做两到三个项目,自己理清思路,把项目理解透彻,还是可以学到很多东西的。
根据自己情况,选择两到三个项目重点跟着做,理解透彻一点
大数据实战项目
滴滴系统:Kafka+Storm
友盟统计项目:Hive
YouTube项目:Hive
电商数据分析平台项目:Spark
电信客服项目:Hadoop
微博项目:HBase
大数据离线平台:Hadoop+Flume+Hive+HBase
电商数仓项目:Hadoop+Zookeeper+Hive+Flume+Kafka+Spark
在线教育项目:Hadoop+Flume+Kafka+Hive+MySQL+Spark
基于阿里云搭建数据仓库(离线):ECS(日志生产服务器)+Flume+DataHub+MaxCompute/DataWorks+RDS(业务数据)+QuickBI
 基于Flink的电商用户行为数据分析:Kafka+Flink
基于Flink的电商用户行为数据分析:Kafka+Flink
四、机器学习
这部分给一个文章链接,里面有视频+资料的链接
机器学习资料
五、书籍
都是根据自己看过和准备的来的,所以你自己有更好的选择,根据自己的来就行
Java
《Java核心技术 卷Ⅰ》
Scala
《快学Scala》
Linux
《鸟叔的Linux私房菜-基础篇》
《Linux命令行与Shell脚本编程大全》
Hadoop
《Hadoop权威指南》
谷歌三大文章
Google-Bigtable中文版:http://pan.baidu.com/s/1eQxmrVc
Google-MapReduce中文版_1.0:http://pan.baidu.com/s/1hq7XBI8
Google-File-System中文版_1.0:http://pan.baidu.com/s/1i3verZJ
Google三大论文英文版:http://pan.baidu.com/s/1o6G8PGA
Hive
《Hive编程指南》
Kafka
《Kafka权威指南》
HBase
《HBase权威指南》
Spark
《Spark快速大数据分析》
《Apache Spark源码剖析》
《Spark MLlib机器学习》
大概就这些,看完就需要很久了,大部分我也是需要的时候看相应的部分,所以有时间可以好好看下,不然就需要哪一部分看哪一部分,有助于学习即可。
写这篇博客时间花的不多,但是找这些这些资料花的时间确实不少,这上面的视频资料大部分都是我自己看过的,还有一些其他看过的,不过觉得帮助不是很大,就没有再放链接,这些视频有些我看了不下两遍,一遍不懂,回头就再看一遍。
如果有笔误之处,或者不足之处,欢迎指正,不胜感激~
后续也会继续更新~~~~~~~~~~~
有帮助就点个赞吧,哈哈哈哈哈
欢迎关注我的知乎专栏,也会更新大数据的资料
大数据学习指南










 京公网安备 11010802041100号
京公网安备 11010802041100号