导读:在FlinkSQL中TableSource提供对存储在外部系统(数据库,键值存储,消息队列)或文件中的数据的访问。 在TableEnvironment中注册TableSource后,可以通过Table API或SQL查询对其进行访问。Flink 已内置了一批常用的Source & Sink,如KafkaTableSource、JDBCTableSource等。本文将基于自定义KafkaTableSource从以下四点展开讨论:
- 需要自定义KafkaTableSource场景描述
- 实现自定义KafkaTableSource的思路
- 自定义KafkaTableSource具体实现方式
- 自定义KafkaTableSourceFactory具体实现方式
场景描述
场景描述:从多个渠道采集用户行为数据(数据来自不同渠道,但是结构类型一致),并将采集到的数据传输到各个渠道在Kafka所对应的topic中,之后由Flink Job访问Kafka获取数据并进行处理。
解决方案:这里采用FlinkSQL进行Job开发,通过使用内置的KafkaTableSource的connector.topic属性可以实现从指定Kafka topic获取消息。
bsTableEnv.sqlUpdate("CREATE TABLE sourceTable (" + "name STRING," + "country STRING" + ")" + "WITH (" + "'connector.type' = 'kafka'," + "'connector.version' = '"+CONNECTOR_VERSION+"'," + "'connector.topic' = '"+SOURCE_TOPIC+"'," + "'connector.properties.zookeeper.connect' = '"+ZOOKEEPER_CONNECT+"'," + "'connector.properties.bootstrap.servers' = '"+BROKER_LIST+"'," + "'connector.properties.group.id' = '"+GROUP_ID+"'," + "'format.type' = 'json')");
美中不足之处:由于数据虽然来自不同渠道,但是结构类型一致。我们期望可以通过一个Job处理多个topic的消息,而通过分析代码发现KafkaTableSource的connector.topic只能支持单个topic Name。代码如下:
1、KafkaTableSource 通过 createKafkaConsumer 方法来创建 FlinkKafkaConsumer。
2、进入createKafkaConsumer发现其构造方法中对传入的String topic 通过Collections.singletonList(topic) 包装成了一个List。
基于以上分析发现KafkaTableSource的connector.topic并不能支持多个topic的写法。
实现自定义KafkaTableSource的思路
1、既然KafkaTableSource满足不了我们的需求,而官方支持用户自定义Sources,那么我们可以通过自定义一个KafkaTableSource来达到我们的需求,Flink自定义Sources & Sink 文档地址:
//FlinkSQL 1.10--User-defined Sources & Sinks https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/table/sourceSinks.html#define-a-tablesource
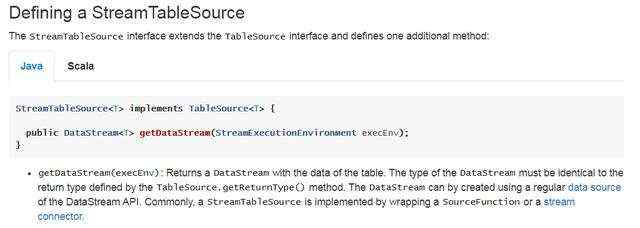
翻阅官方文档,发现可以通过实现StreamTableSource接口来构建一个自定义StreamTableSource
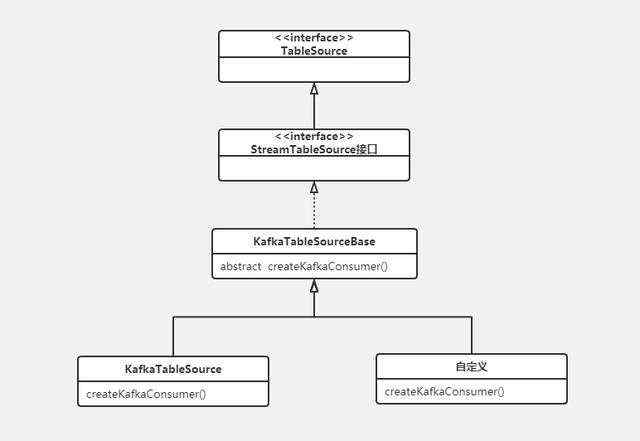
2、接下来,我们查看了StreamTableSource的层次结构,发现Flink还提供了KafkaTableSourceBase类
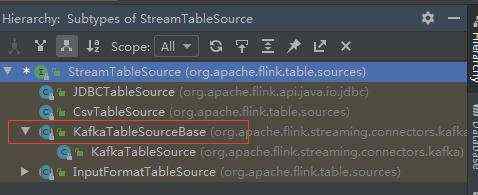
StreamTableSource层次结构
KafkaTableSourceBase类实现了StreamTableSource接口,同时也提供构建一个自定义KafkaTableSource所需的大部分基础内容(包括连接器connector的实现,这里就不深入讨论,感兴趣的朋友可以参考官方文档:
https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/connectors/kafka.html)。
这里我们要关注一个点,KafkaTableSourceBase类提供了一个createKafkaConsumer()的抽象方法,用于创建KafkaConsumer。
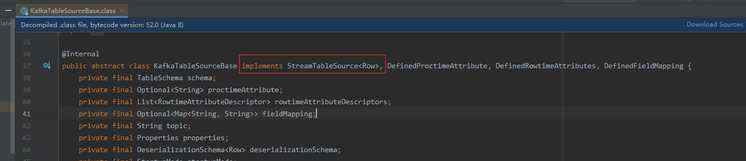
KafkaTableSourceBase类

createKafkaConsumer
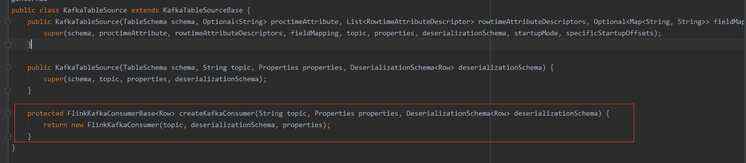
3、我们再看看KafkaTableSource类,其继承了KafkaTableSourceBase类,并实现了createKafkaConsumer()方法(这里要注意FlinkKafkaConsumer的版本问题)。
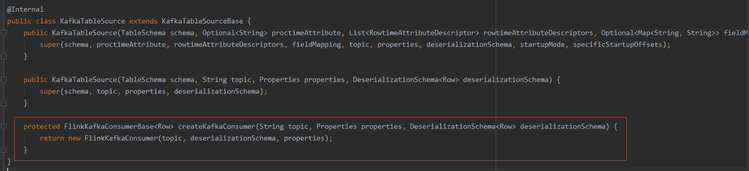
KafkaTableSource
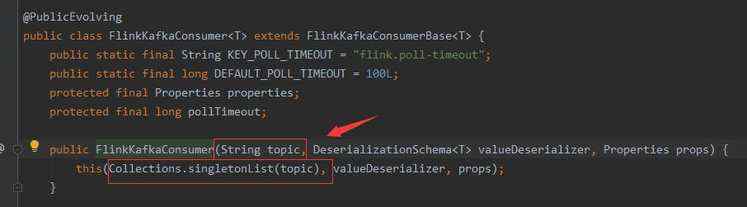
4、深入查看FlinkKafkaConsumer类,发现其提供了多个构造方法,其中包括可接收List topics。
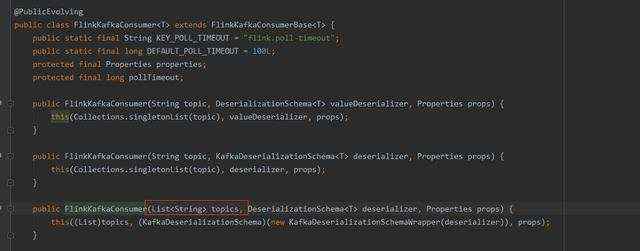
FlinkKafkaConsumer
那么到这里我们便可以参考KafkaTableSource例子,通过继承KafkaTableSourceBase并根据自身需求实现createKafkaConsumer方法。
5、这里把类图简单画出来助于理解,层次结构如下:
自定义KafkaTableSource实现方式
1、编写一个MoreTopicKafkaTableSource类并继承 KafkaTableSourceBase,然后重写createKafkaConsumer()方法。这里简单思路为将topic根据逗号进行切割并存成一个List。
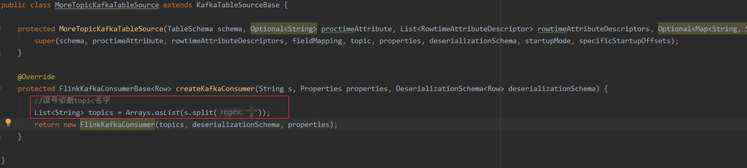
MoreTopicKafkaTableSource
2、通过FlinkKafkaConsumer的 FlinkKafkaConsumer(List topics, DeserializationSchema deserializer, Properties props) 构造方法达到可以多topic的效果。
问题:自此自定义的MoreTopicKafkaTableSource完成了,但是如何将Source在环境中注册同时又如何让程序知道我们想用的是MoreTopicKafkaTableSource而不是内置的KafkaTableSource?
自定义KafkaTableSourceFactory实现方式
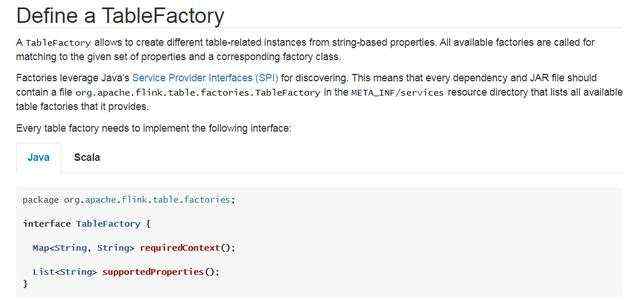
1、查阅官方文档发现,我们可以通过定义TableFactory来解决以上的问题。文档如下:
TableFactory允许从基于字符串的属性中创建与表相关的不同实例。 调用所有可用的工厂以匹配给定的属性集和相应的工厂类。工厂利用Java的服务提供商接口(SPI)进行发现。 这意味着每个依赖项和JAR文件都应在META_INF / services资源目录中包含一个文件org.apache.flink.table.factories.TableFactory,该文件列出了它提供的所有可用表工厂。
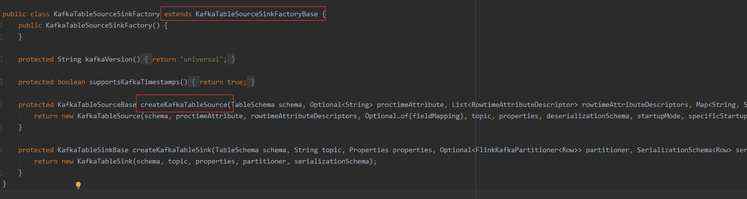
2、接下来,我们参考KafkaTableSource类所对应的KafkaTableSourceSinkFactory工厂类,该工厂类继承了KafkaTableSourceSinkFactoryBase。这里要关注的是KafkaTableSourceSinkFactory实现了createKafkaTableSource()方法,在该方法中创建了KafkaTableSource对象。
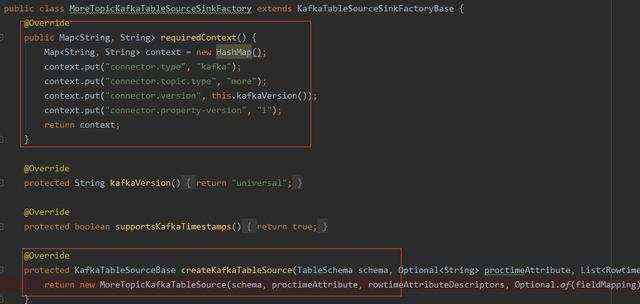
3、同样,我们也创建一个MoreTopicKafkaTableSourceSinkFactory并继承KafkaTableSourceSinkFactoryBase,实现createKafkaTableSource()方法使其创建我们的MoreTopicKafkaTableSource对象。
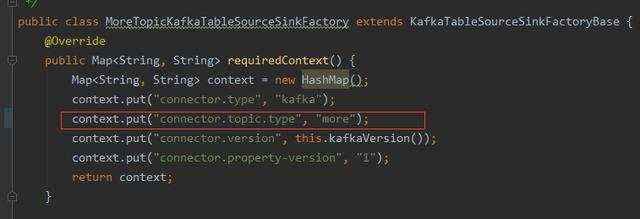
4、在这里还有一个重要的点就是requiredContext()方法,其用于匹配工厂。
指定为其实现此工厂的上下文。如果满足指定的属性和值集,则框架保证仅与此工厂匹配。典型的属性可能是连接器类型, 格式.type,或更新模式。属性键,如connector.property-version 和 format.property-version后兼容情况保留的。
由于KafkaTableSourceSinkFactory和我们的自定义MoreTopicKafkaTableSourceSinkFactory都继承了KafkaTableSourceSinkFactoryBase,而KafkaTableSourceSinkFactoryBase提供了requiredContext。这会导致框架匹配到两个工厂,出现异常。
解决办法:可以在MoreTopicKafkaTableSourceSinkFactory 自定义多一个key-value。
5、最后一个很重要的步骤是在 resource 目录下添加文件夹 META_INF/services,并创建文件 org.apache.flink.table.factories.TableFactory,在文件中写上新建的 Factory 类,自此结束。
总结- 编写一个MoreTopicKafkaTableSource 继承 KafkaTableSourceBase,并重写createKafkaConsumer方法。
- 创建一个MoreTopicKafkaTableSourceSinkFactory并继承KafkaTableSourceSinkFactoryBase,实现createKafkaTableSource()方法使其创建我们的MoreTopicKafkaTableSource。
- 在MoreTopicKafkaTableSourceSinkFactory中重写requiredContext并为工厂匹配添加多一个key-value规则使匹配更加精确。
- resource 目录下添加文件夹 META_INF/services,并创建文件 org.apache.flink.table.factories.TableFactory,在文件中写上新建的 Factory 类。
感谢您的阅读,如果喜欢本文欢迎关注和转发,本头条号将坚持持续分享IT技术知识。对于文章内容有其他想法或意见建议等,欢迎提出共同讨论共同进步。








 京公网安备 11010802041100号
京公网安备 11010802041100号