https://www.toutiao.com/a6639449370913669635/
2018-12-27 07:34:30
脸书发布全新自动语音识别的卷积方法 ,以及开源目前最先进的端到端语音识别系统wav2letter++。这个自动语音识别方法使用卷积神经网络(CNN)进行声音建模和语言建模,再加上脸书一同发布的工具,让其他开发者也能实例出相同的成果。

通常CNN架构比起循环架构(Recurrent Architecture),对于有建模长期相依性的任务更具有竞争力,能够良好执行语言建模、机器翻译和语音合成等工作,而在端到端的语音识别其中,循环架构在声音建模和语言建模上却更为普遍。
而脸书的这项研究,是在端到端语音识别中使用CNN架构,脸书表示,端到端语音识别可以轻松的扩展到多种语言,另外,直接从原始语音学习,则是解决音频品质变化大的好方法。脸书的语音团队现在发布第一个全卷积的语音识别系统,从波型到最后的单词转录为文本,系统的可学习部分,能仅由卷积层组成,而这样的性能则可以与循环架构相当。
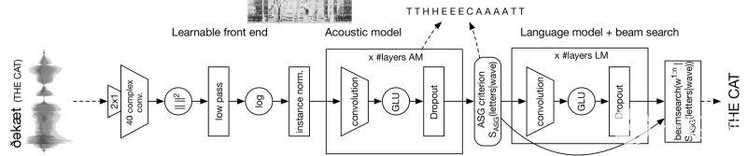
另外,脸书还发布了快速且灵活的独立机器学习函数库Flashlight,这是由脸书的语音团队以及Torch和DeepSpeech的开发者共同设计的,能为现代C++进行JIT编译,并针对CPU和GPU后端,实现性能与规模最大化,而Wav2letter++工具则创建于Flashlight之上。
由于高性能框架Wav2letter++能进行快速迭代,因此可以加速研究进展,并方便的对新数据集和任务进行模型优化。脸书发布全新自动语音识别的卷积方法的同时,也同时发布了Flashlight和Wav2letter++开发框架,以实现成果的可重复性。








 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有