前一阵利用eclipse构建spark集成开发环境,遇到了一些问题,将遇到的问题和解决方法跟大家分享下~
问题一:在用eclipse构建spark的过程中,在eclipse中创建了Map/ReduceProject,导入了spark,scala的jar包,但是出现了各种ClassNotDefError这种错误。原因是jar包依存关系比较复杂,缺少相关的jar包。
问题二:董西成的博客中说利用eclipse遇到的问题比较多,利用IntellijIDEA构建开发环境会比较顺利,按照他的博客(http://dongxicheng.org/framework-on-yarn/apache-spark-intellij-idea/)实践了,但是还是遇到和问题一同样的问题。得出的一个结论是:出过书的人说的也不一定全对。
最终是通过maven解决的。解决的方法如下:
1.用eclipse创建maven项目
2.在pom.xml中添加依存的jar包信息
3.编写代码
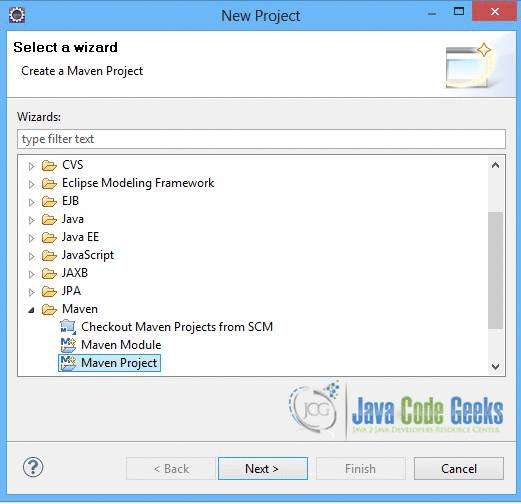
1.用eclipse创建maven项目,File/New/Project 会弹出如下图所示的窗口,选择MavenProject

然后,点next
按下图的操作,
输入groupId,artifactid,点击Finish。
通过以上步骤就创建了一个maven项目,创建成功后,在eclipse左侧会出现刚创建的项目。项目结构如下:
2.在pom.xml中添加需要的jar包的依存信息。双击上图最下方的pom.xml,打开后如下图所示
然后选择下方的pom.xml标签,在该文件中添加依存信息。spark需要的依存信息如下:
3. 之后,按需要编写java代码即可。







 京公网安备 11010802041100号
京公网安备 11010802041100号