来源:混沌巡洋舰
1 )梦让我们对世界的理解不再那么简单化
关于为什么大脑进化出夜间做梦?神经科学界提出了各种假说,诸如通过梦来调节情绪,巩固记忆,或梦可以帮助我们选择性的遗忘,对我们应对现实世界的问题有帮助。但是这些假说都与梦的稀疏性(梦中的场景不常见)、幻觉和叙事性质相矛盾,而这种性质似乎缺乏任何特定的功能相对应。
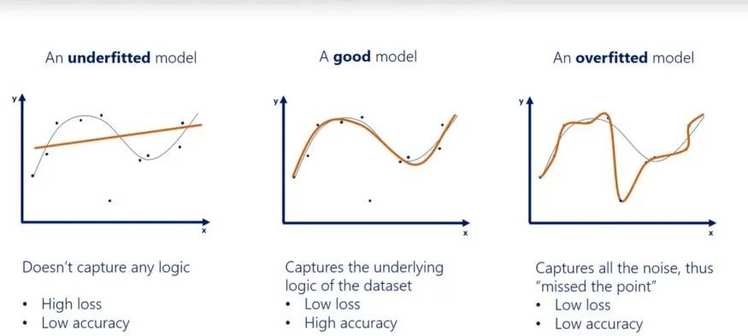
训练人工智能时,一个常见的问题是,它对所训练的数据太熟悉了ーー它开始假设训练集是它可能遇到的任何东西的完美表示。即对特定数据集的过度拟合,导致泛化失败,从而影响新数据集的性能。
数据科学家通过在训练数据中引入一些随机性,来解决这个问题; 在一种称为“dropout”的正则化方法中,一些数据被随机忽略。想象一下,如果黑点突然出现在自动驾驶汽车的内部屏幕上: 一辆即使看到屏幕上随机出现的黑点,还能够专注于周围环境的总体细节,而不是特定驾驶体验的细节的汽车,可能会更好地理解驾驶的一般体验。
考虑到这一点,他的新理论认为,梦恰好使我们对世界的理解不再那么简单化,而是更加全面ーー因为我们的大脑,就像深层神经网络一样,对我们日常生活的“训练集”也太熟悉了。这会导致过拟合和泛化能力变差。通过每天晚上产生幻觉的感官刺激(梦境),大脑能够提升其感知和认知能力的泛化能力,并提高在相对应的分类任务上的性能。
通过自下而上的,在大脑对现实的表征中插入噪音,这意味着梦境中对现实的描述,和现实既有相近之处,又不完全相同,可以看成是一种有组织但不受控的幻觉。这可以被视作大脑在执行“模拟退火”算法,通过在优化过程中,增加随机性来提升泛化能力。
对于梦境为何是千奇百怪的(梦的稀疏性),该假设认为其来自于自下而上表征处理中,随机的的“丢失”一部分,导致梦境是不可重复的,,而梦境的幻觉性来自于更高层的随机性,这意味着梦境中那些部分被腐蚀或扭曲,是有特定目地的,就是要使其不同于正常经历的日常“训练集”,梦境的叙事性来自于梦的自上而下的发生,因为大脑以事件和故事的形式理解现实。也就是说,根据大脑过拟合假说,独特的梦境这一现象之所以存在,是为了最大限度地提高梦境的概括能力,并与日常记忆形成鲜明的对比,以提升泛化能力。
Hoel写到:为了抵消现实刺激的熟悉感,大脑在梦中创造了一个奇怪的世界,就像神经网络训练时的dropout。他写道: “正是梦与清醒时的经历发生分歧的奇异之处,赋予了梦的生物学功能,从这个意义上来说,梦的经历是你做梦的原因。”
梦境的出现,源于这三种神经网络中遇到过拟合技术(dropout,数据增强,以及生成模型)的组合: 一个稀疏的,不完全的,包含随机的一组感觉输入,这可能是利用大脑作为生成模型,利用层级结构经由类似GAN的反馈机制形成的。
2)大脑过拟合假说的证据和应用
Hoel说,已经有来自神经科学研究的证据来支持大脑过拟合假说。例如,已经有研究表明,最可靠的激发梦境的方法就是在你清醒的时候重复地执行一个新奇的任务。例如白天重复玩俄罗斯方块时,你会在晚上做的梦也和俄罗斯方块有关的梦,而这是大脑试图归纳白天的经验而做的尝试。他认为,当你在一个新奇的任务上过度训练时,过拟合的状态就会被触发,你的大脑试图通过创造梦来概括这个任务。
其它支持大脑过拟合假设的事实是:睡眠,尤其是在婴儿阶段,与提高概括和抽象能力相关。且梦境和创造力之间的关系也很密切,因为增加泛化能力,将直接导致对复杂问题的更深刻的见解,或在需要创造力的认知任务上更好的表现。事实上,大脑过拟合假说,通过并不是假设做梦是新旧记忆的整合、记忆的回放或记忆的储存,而是将梦看成一种正则化方法,更好地解释了创造力和做梦之间的联系。
这一理论还能解释,为何在需要泛化能力的复杂任务上,缺少睡眠会导致事故率增加。并能根据任务所需的泛化能力多少,预测究竟在哪些任务(睡眠不足这)更容易失误,从而建立更好的故障安全机制(例如避免切尔诺贝利由于操作人员长期没有睡眠导致的操作失误)。
但是他相信还需要研究,以确定这是否是我们做梦的真正原因。他说,精心设计的行为测试可以区分泛化和记忆,以及睡眠剥夺对两者的影响。
他感兴趣的另一个领域是“人造梦”,他在思考电影或小说等小说作品的目的时,提出了大脑过拟合假说。现在,他假设像小说或电视节目这样的外部刺激可能充当梦的“替代物”ーー而且它们甚至可能被设计成通过强调梦的本质(例如,通过虚拟现实技术)来帮助延缓睡眠剥夺对认知造成的负面影响。
例如,一个飞行了很长一段时间的飞行员开始过度适应他的任务,快速而强烈的接触一种完全不同的视觉刺激(就像通过虚拟现实,为其提供梦一样的自然场景)可以避免由于飞行员长期没有睡眠,对其认知功能造成的影响。而这一基于大脑过拟合假说给出的预测,是可以在实验室中进行验证的。
最后,值得认真对待文化为人类制造的白日梦-小说或电影,是否充当了人造梦的角色,至少其承担了一些类似的功能。进化心理学试图将人类行为的某些方面建立在进化论的基础之上,长期以来,对人们为什么喜欢阅读小说,一直无法给出一个好的解释,因为从表面上来看,小说没有任何效用。毕竟,它们是明显虚假的信息。
因此,人们认为,阅读小说要么是为了影响择偶,是对自己认知能力的一种证明方式,要么可以简单地归结为“令人满足的消费,但没有什么好处。这种观点的支持者甚至将艺术描述为一种“享乐”一些研究人员提出了阅读小说的好处,比如改进心智理论或者帮助抽象社会规范。但按照大脑过拟合假说,阅读小说如同做梦,也是通过提供不同于日常生活的体验,扩展大脑在人际关系这一能力上的泛化能力。
Hoel说,虽然你可以简单地关闭人工神经网络的学习功能,但你的大脑做不到这一点。大脑总是在学习新的东西ーー这就需要梦境来避免大脑的过拟合。“生活有时很无聊,”他说。“而梦会让你不会变得太对这个世界的模式太习以为常。”
参考:
https://www.labmanager.com/news/our-dreams-weirdness-might-be-why-we-have-them-25898
https://www.cell.com/patterns/fulltext/S2666-3899(21)00064-7?_returnURL=https%3A%2F%2Flinkinghub.elsevier.com%2Fretrieve%2Fpii%2FS2666389921000647%3Fshowall%3Dtrue
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”















 京公网安备 11010802041100号
京公网安备 11010802041100号