作者:dmcm0001 | 来源:互联网 | 2023-06-18 18:01
通过几个问题来学习HashMap前提大家都知道,HashMap是由哈希表实现的,哈希表就是由数组和链表组成的。给出一个很形象的数据结构图。image.png问题1.既然HashMa
通过几个问题来学习HashMap
前提大家都知道,HashMap是由哈希表实现的,哈希表就是由数组和链表组成的。
给出一个很形象的数据结构图。
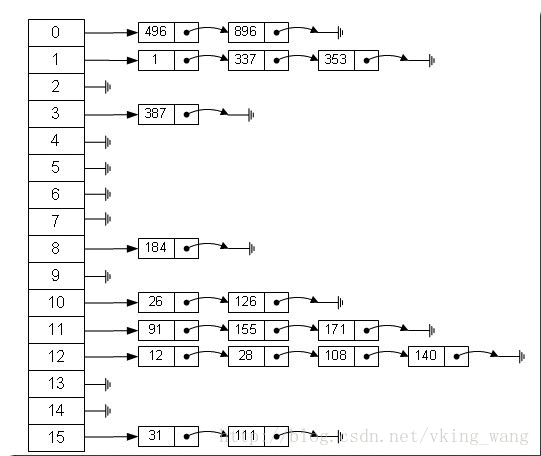 image.png
image.png
问题1.既然HashMap是数组+链表实现的,数组开始的时候一定是有一个固定长度的,那HashMap中的数组默认长度是多少呢?
默认情况下,内部数组的长度就是16,这个可以从HashMap的底层源码的构造函数中看到。下面我们就开始HashMap的源码阅读之旅。
HashMap的构造函数有三个。默认我们都是不会传这个initialCapacity的,如果不传的话,那么就会使用默认为4的DEFAULT_INITIAL_CAPACITY
 DEFAULT_INITIAL_CAPACITY
DEFAULT_INITIAL_CAPACITY
 HashMap的构造函数
HashMap的构造函数
然后将initialCapacity的值赋给了threshold,我们会在put方法中判断,如果是第一次put数据就会初始化Table,也就使用到了这个threshold。
 put
put
那么是怎么初始化的呢?就是拿到这个threshold对其做一下平方。(roundUpToPowerOf2就是对2的幂次幂)
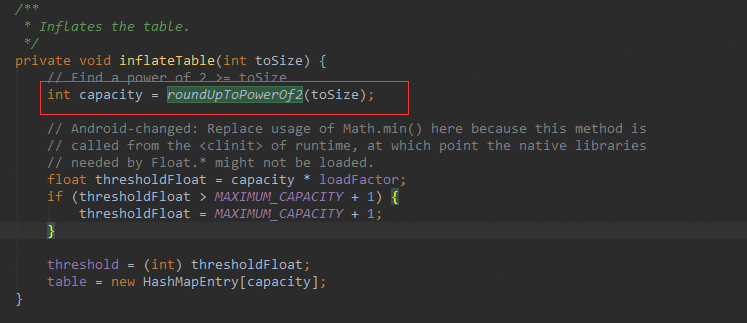 image.png
image.png
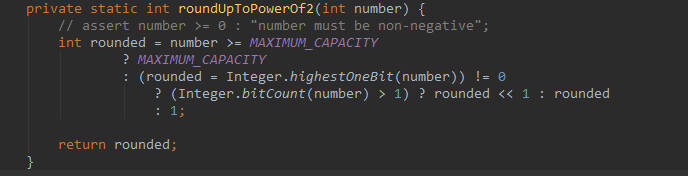 roundUpToPowerOf2就是对2的幂次幂
roundUpToPowerOf2就是对2的幂次幂
一步步追踪源代码,发现最后是返回的默认的4的平方的数组长度。
问题2.HashMap既然底层是一个线性的数组,那么是怎么实现的随机存取呢?
(因为是随机存取,所以是有些索引位置是没有元素的,会产生一些空间的浪费,但是这其实就是空间换时间,让HashMap既有数组的查询快,又有链表的增删快的优点)
// 存储时:
int hash = key.hashCode();
int index = hash % Entry[].length;
Entry[index] = value;
// 取值时:
int hash = key.hashCode();
int index = hash % Entry[].length;
return Entry[index];
存储的时候就是拿到key的hash值然后对HashMap底层数组的长度取余,取余的结果就是存储的索引。
取值的时候一样是拿到key的hash值然后对HashMap底层数组的长度取余,得到索引直接去数组里面取就行了。取出来是一个链表的封装类Entry,然后遍历一下Entry中的值取出我们要的就行了。
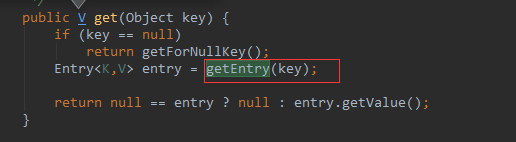 image.png
image.png
 image.png
image.png
总结:元素存储的规则 hash(key)%len, 就是key的hash值对HashMap底层数组的长度取余,这个公式一定要记住。
问题3.通过上面的问题我们了解了HashMap的存取,但是我们要知道Hash算法其实就是把任意长度的输入变换成固定长度的输出,这种转换是一种压缩映射,也就是说,Hash值的空间远小于输入的空间,不同的输入可能会Hash成相同的输出。而且我们又对HashMap默认size 16的数组长度取余,所以不同的key就更是有很大概率返回相同的索引了,那会不会就把之前存的数据给覆盖了呢?
答案当然是否定的。不然谁还敢用HashMap存数据呢。
HashMap我们知道是数组+链表实现的,前面我们是只看到了数组,链表呢就是在这使用的。这里HashMap里面用到链式数据结构的一个概念。上面我们提到过Entry类里面有一个next属性,作用是指向下一个Entry。打个比方, 第一个键值对A进来,通过计算其key的hash得到的index=0,记做:Entry[0] = A。一会后又进来一个键值对B,通过计算其index也等于0,现在怎么办?HashMap会这样做:B.next = A,Entry[0] = B,如果又进来C,index也等于0,那么C.next = B,Entry[0] = C;这样我们发现index=0的地方其实存取了A,B,C三个键值对,他们通过next这个属性链接在一起。也就是说数组中存储的是最后插入的元素。(数组中只会存一个Entry元素,这一个元素的next就会指向下一个元素,这样循环)
问题4.我们前面看到数组的默认长度是16,可以说很小,那他会不会扩容呢?
答案是肯定的。默认HashMap内部数组的长度为16,负载因子为0.75,就是在构造函数里面传的两个值。阈值就是12(16*0.75=12),这样当第十三个元素加入时,底层数组就会扩容。扩容为原数组大小的两倍。
 image.png
image.png
resize(2*table.length)就是扩容的操作。扩容为原数组的两倍。
 扩容为原数组的两倍
扩容为原数组的两倍








 京公网安备 11010802041100号
京公网安备 11010802041100号