浏览器如何工作(How browsers work)的阅读笔记
1. 整体结构
完整的浏览器整体框架的发改如下: 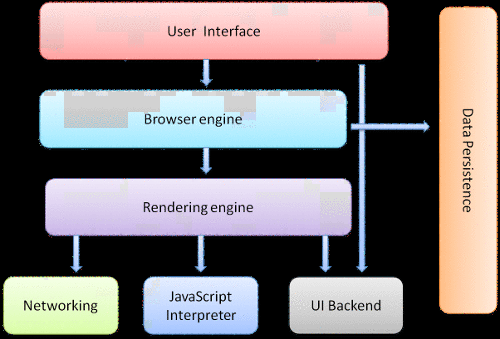
UI : 就是那些我们常常看到的浏览器的界面,现在的浏览器大概就是包含了选项卡 后退前进刷新这些按钮等等
Browser engine浏览器引擎: 查询和操作渲染引擎的接口(官方解释)。 其实就是去衔接 协调UI 和 rendering 还有UI backend 这些的
rendering engine 渲染引擎:主要是对html css进行解析的工作 并且呈现出来 这才是 整个浏览器最重要的核心
networking:肯定会进行网络操作的吧
js interpreter: 执行 js 难道是 v8
data persistence : web storage (web database)缓存 COOKIEs 这些是不是要数据持久化
UI backend: UI后端就是组件样式的
- 运行流程
主要是整个流程。 
从用户输入url按下回车开始讲起:
首先如是的url,url主要可以看成是 域名 + 资源位置构成的。
首先就要进行dns域名解析,域名解析
- 查浏览器dns缓存 系统dns 缓存
- 然后 再去看看host有没有 (如果 有代理的话,估计dns就直接请求代理服务器了)
- 如果没有的话 就要请求dns 服务器 应该是 迭代的方式请求。。
然后获取到了ip地址 这时候会有缓存的问题。
- 可能有些情况,发现缓存没有过期就直接不请求了。
- 可能会先请求看下缓存有没有和服务器的一致(http 304)也就不会请求完整的了。
总之 会有这一步,而这些都是之前请求http headers 告诉 browsers的
然后 就是 发送http 请求了。
http请求是基于tcp的。。传说中的三次握手
一般是 user-agent会随机一个端口和http80端口进行通信
这个连接请求(原始的http请求经过TCP/IP4层模型的层层封包)到达服务器端后(这中间通过各种路由设备,局域网内除外),进入到网卡,然后是进入到内核的TCP/IP协议栈(用于识别该连接请求,解封包,一层一层的剥开),还有可能要经过Netfilter防火墙(属于内核的模块)的过滤,最终到达WEB程序(本文就以Nginx为例),最终建立了TCP/IP的连接。
最后 获得了我们的html文档,我们的重点也来了。
首先是 对html进行解析 通过非上下文无关文法 生成dom树
然后就是 解析css 也是会形成一个所谓的树状结构 我们可以成为解析树拉
然后 两个数进行attach 形成 render 树
然后 在进行render树进行layout 就是确定每个结点的坐标位置
最后通过绘制 就是可以输出成我们的看到的结果啦
当然里面会涉及到很多很多的东西
比如说 关于js加载时机 layout重排的问题 当然 解析本身也是一件非常复杂的事情
值得注意的是,这个过程是逐步完成的,为了更好的用户体验,渲染引擎将会尽可能早的将内容呈现到屏幕上,并不会等到所有的html都解析完成之后再去构建和布局render树。它是解析完一部分内容就显示一部分内容,同时,可能还在通过网络下载其余内容。
参考链接:http://kb.cnblogs.com/page/129756/






 京公网安备 11010802041100号
京公网安备 11010802041100号