总结下 MIT6.824 Lab2B Log Replication 的实验笔记。Lecture 参考: lab-raft.html
Lab2B
测试用例
2A 部分完成了基础的 Leader Election 和 Heartbeat 机制,2B 部分要完成 Log Replication,同时实现论文中 5.4.1 节选举限制机制来保证选举的安全性。 本节实验目标是通过 test_test.go 中的 *2B 测试用例:
- TestBasicAgree2B:实现最简单的日志复制
对 leader 请求执行 3 个命令,五个节点均正常的情况下日志要能达成一致。
- TestFailAgree2B:处理少部分节点失效
三个节点组成的集群中,某个普通节点发生了网络分区后,剩余两个节点要能继续 commit 和 apply 命令,当该该节点的网络恢复后,要能正确处理它的 higher term
- TestFailNoAgree2B:处理大部分节点失效
在五个节点组成的集群中,若有三个节点失效,则 leader 处理的新命令都是 uncommit 的状态,也就不会 apply,但当三个节点的网络恢复后,要能根据日志新旧正确处理选举。
- TestConcurrentStarts2B:处理并发的命令请求
在多个命令并发请求时,leader 要保证每次只能完整处理一条命令,不能因为并发导致有命令漏处理。
- TestRejoin2B:处理过期 leader 提交的命令
过期 leader 本地有 uncommit 的旧日志,在 AppendEntries RPC 做日志一致性检查时进行日志的强制同步。这是最棘手的测试,其流程如下:
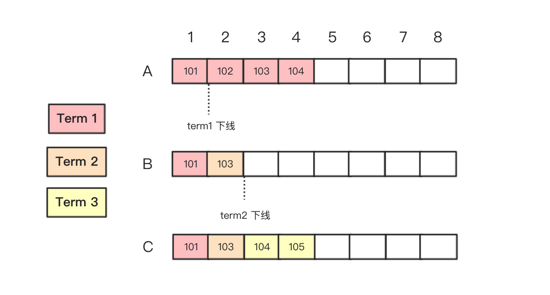
- TestBackup2B:性能测试
在少部分节点失效、多部分节点失效环境下,尽快完成两百个命令的正确处理。
- TestCount2B:检查无效通信的次数
正常情况下,超时无效的 RPC 调用不能过多。
测试均通过:
实现思路
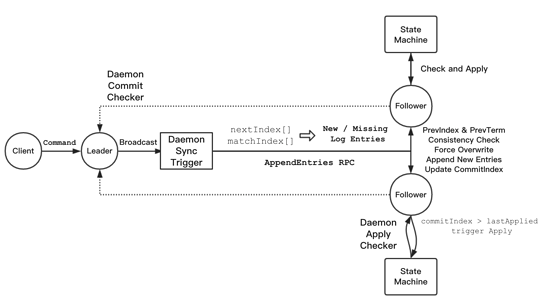
整体流程
- client 将命令发送给 leader 后,leader 先本地 append 日志后立刻响应(lab 与 paper 此处有差异),随后广播给所有其他节点的 sync trigger,主动触发日志复制。
- follower 收到日志后进行一致性检查,强制覆写冲突日志并 append 新日志,通知 leader 复制成功。
- leader 在后台统计当前任期的日志复制成功的节点数量,若达到 majority 则将日志标记为 commit 状态并通知 apply
- 在之后的心跳请求中,leader 将自己的 commitIndex 一并同步,follower 发现自己的 commitIndex 落后,随即更新,通知 apply
关键点
- 正如 lecture 的提示,实现时需要大量的同步触发机制,可选择 Go 的阻塞 channel 或 sync 包的条件变量。其中,阻塞 channel 使用不当可能会造成死锁或资源泄漏,而且触发点很多,会造成一个 channel 满天飞的情况,遂选择条件变量做同步。
- leader 要实现上图三个 daemon 机制,而 follower 只需要实现 apply checker
- leader 的 sync trigger:新日志 append 或心跳通信都会触发
- leader 的 commit checker:一直通过 matchIndex 检测日志的 commit 状态
- leader、follower 的 apply checker:当确定某条日志未 commit 状态时触发 apply 执行
- 充分理解论文的图 2:lastApplied 和 commitIndex,nextIndex[] 和 matchIndex[] 都将用于复制机制。
日志复制
日志结构
Raft 的目标是在大多数节点都可用且能相互通信的前提下,保证多个节点上日志的一致性。日志的存储结构:
type LogEntry struct {
Term int
Command interface{}
}
Term 是 Raft 协议的逻辑时钟,用于检查日志的一致性。它有三种状态:
- commit / committed:当日志被成功 replicated 到大多数节点后的状态
- apply / applied:日志已处于 commit 状态后,即可直接 apply 执行
- uncommit:日志因网络分区等原因未成功复制到大多数节点,停留在 leader 内的状态
AppendEntries RPC
leader 通过 AppendEntries RPC 与各节点进行日志的同步。请求参数和响应参数如下:
type AppendEntriesArgs struct {
Term int // leader term
LeaderID int // so follower can redirect clients
PrevLogIndex int // index of log entry immediately preceding new ones
PrevLogTerm int // term of prevLogIndex entry
Entries []LogEntry // log entries to store (empty for heartbeat;may send more than one for efficiency)
LeaderCommit int // leader’s commitIndex
}
type AppendEntriesReply struct {
Term int // currentTerm, for leader to update itself
Succ bool // true if follower contained entry matching prevLogIndex and prevLogTerm
}
被调用方(Servers)
参考论文图 2,当节点收到此调用后,依次进行五个判断:
- Reply false if term
- Reply false if log doesn’t contain an entry at prevLogIndex whose term matches prevLogTerm
- If an existing entry conflicts with a new one (same index but different terms), delete the existing entry and all that follow it
- Append any new entries not already in the log
- If leaderCommit > commitIndex, set commitIndex =min(leaderCommit, index of last new entry)
func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {
reply.Term = rf.curTerm
reply.Succ = false
if args.Term rf.curTerm {
rf.curTerm = args.Term
rf.back2Follower(args.Term, VOTE_NIL)
}
// now terms are same
rf.resetElectTimer()
// consistency check
last := len(rf.logs) - 1
if last last {
rf.logs = append(rf.logs, e) // new log, just append
committed = len(rf.logs) - 1
}
}
// if leaderCommit > commitIndex, set commitIndex =min(leaderCommit, index of last new entry)
if args.LeaderCommit > rf.commitIndex {
rf.commitIndex = min(committed, args.LeaderCommit) // need to commit
rf.applyCond.Broadcast() // trigger apply
}
rf.back2Follower(args.Term, args.LeaderID)
reply.Succ = true
}
调用方(Leader)
// leader replicate logs or send heartneat to other nodes
func (rf *Raft) sync() {
for i := range rf.peers {
if i == rf.me {
rf.resetElectTimer()
continue
}
go func(server int) {
for {
if !rf.isLeader() {
return
}
rf.mu.Lock()
rf.syncConds[server].Wait() // wait for heartbeat or Start to trigger
// sync new log or missing logs to server
next := rf.nextIndex[server]
args := AppendEntriesArgs{
Term: rf.curTerm,
LeaderID: rf.me,
Entries: nil,
LeaderCommit: rf.commitIndex,
}
if next rf.curTerm { // higher term
rf.back2Follower(reply.Term, VOTE_NIL)
return
}
continue
}
// append succeed
rf.nextIndex[server] += len(args.Entries)
rf.matchIndex[server] = rf.nextIndex[server] - 1 // replicate succeed
}
}(i)
}
}
Daemon goroutines
Apply Checker
每个节点在 Make 初始化时会启动两个后台 goroutine:
lastApplied
// apply (lastApplied, commitIndex]
func (rf *Raft) waitApply() {
for {
rf.mu.Lock()
rf.applyCond.Wait() // wait for new commit log trigger
var logs []LogEntry // un apply logs
applied := rf.lastApplied
committed := rf.commitIndex
if applied
Commit Checker
在设计实现时,leader 将日志的 replicate 和 commit 解耦,所以需要 leader 在后台循环检测本轮中哪些日志已被提交:
// leader daemon detect and commit log which has been replicated on majority successfully
func (rf *Raft) leaderCommit() {
for {
if !rf.isLeader() {
return
}
rf.mu.Lock()
majority := len(rf.peers)/2 + 1
n := len(rf.logs)
for i := n - 1; i > rf.commitIndex; i-- { // looking for newest commit index from tail to head
// in current term, if replicated on majority, commit it
replicated := 0
if rf.logs[i].Term == rf.curTerm {
for server := range rf.peers {
if rf.matchIndex[server] >= i {
replicated += 1
}
}
}
if replicated >= majority {
// all (commitIndex, newest commitIndex] logs are committed
// leader now apply them
rf.applyCond.Broadcast()
rf.commitIndex = i
break
}
}
rf.mu.Unlock()
}
}
选举限制
参考论文 5.4.1 节,为保证选举安全,在投票环节限制:若 candidate 没有前任 leaders 已提交所有日志,就不能赢得选举。限制是通过比较 candidate 和 follower 的日志新旧实现的,Raft 对日志新旧的定义是,让两个节点比较各自的最后一条日志:
- 若任期号不同,任期号大的节点日志最新
- 若任期号相同,日志更长的节点日志最新
// election restrictions
func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {
reply.Term = rf.curTerm
reply.VoteGranted = false
if args.Term rf.curTerm {
rf.back2Follower(args.Term, VOTE_NIL)
}
// now the term are same
// check up-to-date, from Paper:
// if the logs have last entries with different terms, then the log with the later term is more up-to-date.
// if the logs end with the same term, then whichever log is longer is more up-to-date.
i := len(rf.logs) - 1
lastTerm := rf.logs[i].Term
if lastTerm > args.LastLogTerm {
return
}
if lastTerm == args.LastLogTerm && i > args.LastLogIndex {
return
}
// now last index and term both matched
if rf.votedFor == VOTE_NIL || rf.votedFor == args.CandidateID {
reply.VoteGranted = true
rf.back2Follower(args.Term, args.CandidateID)
}
return
}
至此,梳理了 Lab2B 日志复制的设计流程、实现了选举限制 up-to-date。
总结
Lab2B 应该是三个部分最难的了,我前后折腾了两三个星期,从尝试到处飞的 channel 同步换到了 sync.Cond 才更易调试和实现。值得一提的是,文件结构上的解耦也是十分有必要的,比如我的:
➜ raft git:(master) tree
.
├── config.go
├── persister.go
├── raft.go # 节点初始化,超时选举机制
├── raft_entry.go # AppendEntries RPC 逻辑
├── raft_leader.go # sync 日志,心跳通信等
├── raft_peer.go # 定义超时时间
├── raft_vote.go # RequestVote RPC 逻辑
├── test_test.go
└── util.go # 自定义的调试函数等
为尊重课程的 Collaboration Policy,我把 GitHub repo 设为了 Private,由于经验有限,上述代码可能还有 bug,如您发现还望留言告知,感谢您的阅读。





 京公网安备 11010802041100号
京公网安备 11010802041100号