作者:G小麥NO1_238 | 来源:互联网 | 2023-09-09 11:19
介绍
NER时深度语言理解的第一阶段,然而,目前的NER模型极大地依赖人工标注的数据。在本次工作中,为了脱离对于有标签数据的依赖,我们提出LADA方法用于半监督NER,通过插入相近的句子生成虚拟数据。我们的方法有两种:Intra-LADA 和 Inter-LADA,Intra-LADA 插入同一个句子中的token,Inter-LADA 采样不同的句子插入。通过采样训练数据的线性添加,LADA 生成了大量的有标签数据,提升了实体和文章理解。我们通过设计一个新的一致性的 loss进一步扩展LADA到半监督。实验在两种基准下实施,证明了我们方法的有效性。
传统ner模型从字典到神经网络到迁移学习都是依赖于大量丰富的有标签数据,由于缺少有标签数据,使得这些模型很难应用于新领域。不同的NLP数据增强方法可以分为两类:① 在token层面的对抗性攻击,例如词替换和增加噪音。 ② 在句子层面的解释,例如反向翻译或者子模块优化模型。前者被广泛使用,后者由于很难维持实体token的一致性,很难应用于NER任务。
我们使用了另外一种数据增强方法mixup,原始用于文本分类。但文本分类是单标签任务,与NER不同。我们引入了LADA限制mixup方法中的样本应该相近。Intra-LADA用来自同一句子的token插入每个token的隐藏层表示。Inter-LADA用来自k近邻采样和随机采样的加权组合的其他句子token插入每个token的隐藏层,权重控制了噪声和正则化之间的精妙权衡。
论文中介绍了LADA模型以及其他三种数据增强的方法
1. LADA
在中间模型中混合两个句子的隐藏层参数
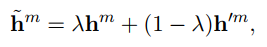

此为mixup方法混合标签的方式


 loss
loss
采用kl loss
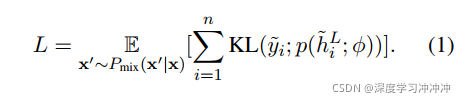
Pmix表示句子采样概率,以下为随机采样(S表示数据集)

LADA带来了更糟糕的结果。假设是因为句子之间相似度太低带来了噪声,给模型学习造成了困难。因此应该限制两个句子相近。
2. Intra-LADA
构造x’的直接方法是使用x中的相同token,但改变顺序。**优点:**一方面,顺利地实现了从句子层级到token层级的转变,有利于NER任务;另一方面,增强了模型的鲁棒性。**缺点:**它克制了生成句子的多样性。
3. Inter-LADA
两种策略的组合(knn和随机采样):

使用sentence-Bert将句子编码,计算l2距离(由于token层级的距离比句子分类距离要大)。u作为超参数调节。
KNN降低噪声分析:
- 可能与原始句子包含相同实体,但表示的意义又不同。
- 帮助检测不同实体的相同类型。
- 帮助检测同一实体的不同类型。
4. Semi-supervised LADA
使用back-translation生成x',语义相同。由此产生两个问题,① token出现的位置不一样 ② token的数量不一样
对于back-translation,一般情况下entity的个数都应该相同,引入一致性loss控制entity每个类型的个数相同
对于x和x',首先猜测token labels

在早期(后期没有用)sharpen归一化

计算每个类型的实体数量

维度为C,C表示实体类型的总数,第i个值表示第i个类型的实体的个数。
loss
consistency loss

其中yk表示由x生成的第k个x'

lamda控制了有监督和无监督的比例。







 京公网安备 11010802041100号
京公网安备 11010802041100号