1.
业务说:“…… bulabula……,这个需求很简单,怎么实现我不管?”
面对霸气侧漏的业务需求,由于没有大数据知识储备,咱心里没底,咱也不敢问,咱也不敢说,只能静下来默默储备、默默寻觅解决方案。
关注“一猿小讲”公众号的小伙伴们,今天有福啦,因为今天我们将一起跳出系统之外,共同迈入大数据之 flink 的大门。
flink 是啥?flink 干啥用的?……
我相信,你心中肯定有类似千万种这样疑问,但是你花两分钟坚持读到最后,我想想能扑灭你心中的疑问的 99.99%。
好了,请准备好小板凳,我们的故事开始。
2.
上来理论先不谈,一言不合就实践。环顾了一下四周,90% 的同事都用 Mac 本,本次演示也是基于 Mac 系统。
磨刀不误砍柴工,准备环境。确保本机安装了JDK,因为 flink 编译和运行要求 Java 版本至少是 JDK 1.8,来输入命令检查一下

如果没有安装 JDK 1.8,请按照内心的指引安装一下。我相信这步过了之后,后面将会顺风顺水,大鹏一日同风起,扶摇直上九万里(捂嘴笑)。
版本千千万,总有一款你喜欢。这里我们选择最新版本 1.8.1 进行入门学习,不要问为什么,就因为王八看绿豆,看对眼了。
http://mirrors.tuna.tsinghua.edu.cn/apache/flink/flink-1.8.1/flink-1.8.1-bin-scala_2.12.tgz
选好版本下载完,来个全局看一看。其中 bin 为启动停止脚本,conf 为配置文件目录,examples 为小样例,lib 所依赖的类库,log 为日志目录。
本次我们重点关注bin、examples、log 三个目录。
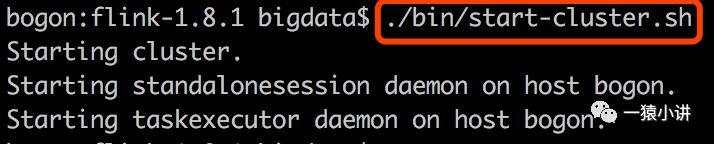
一切准备就绪,小试牛刀。单机方式运行 flink,在 flink 的主目录下,输入命令闹铃响起,呼唤 flink 要去工作啦。
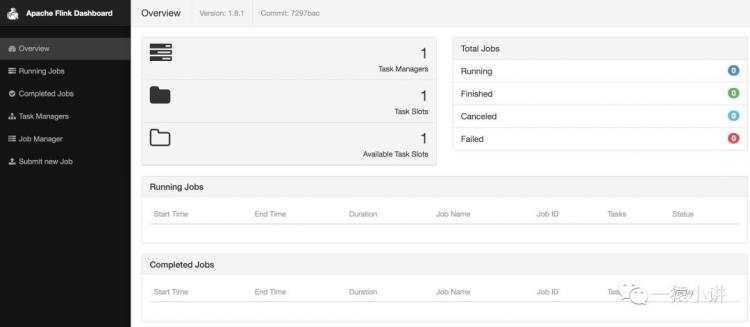
纵然他人夸你千万遍,让我看看好看不好看。输入 http://127.0.0.1:8081/ 一览容颜。
画龙画虎难画骨,知人知面不知心。看完表面,猜背后。深入了解又何妨?输入 jps 命令一探究竟。
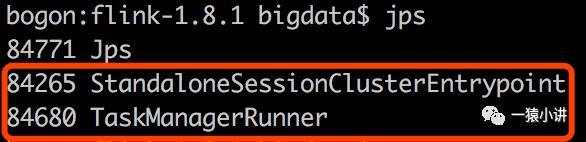
哦,原来背后主要是两个进程在默默的付出:一个是 JobManager 进程, 另一个是 TaskManager 进程。其实我最喜欢背后默默付出的人,给两位默默付出的进程打 Call,点赞。
flink 已经从睡梦中苏醒,并准备就绪,就等咱们下发任务啦。HelloWorld 跑跑看。
3.
有界的数据处理(装文艺书生了有没有)。我这定义了一些 WORDS,麻烦 flink 你帮忙统计一下每个单词出现的次数呗?
第一步:准备数据。数据来自 flink 自带的 example 源码,找个时间咱们从源码上再深入聊一次。数据贴出来,目的就是为了让大家看一下,要知道咱们要让 flink 干啥就行了,数据来源本次无需特别关注。

第二步:提交 WordCount.jar 给 flink。不得不说 flink 毫秒级处理,还未等片刻,就给咱们反馈了。
输入命令:
./bin/flink run examples/streaming/WordCount.jar
结果如下:
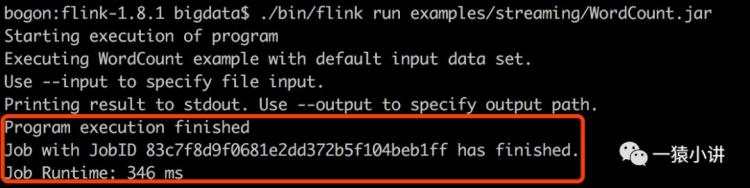
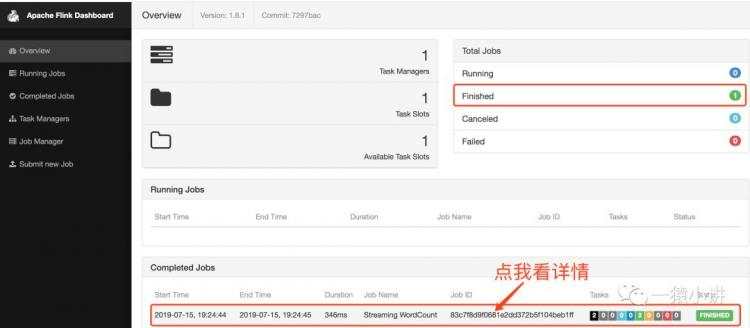
第三步:打开页面看一看 flink 留下的轨迹。
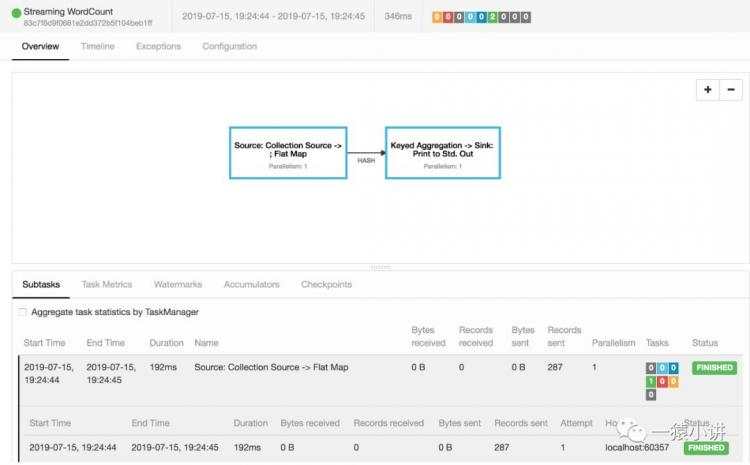
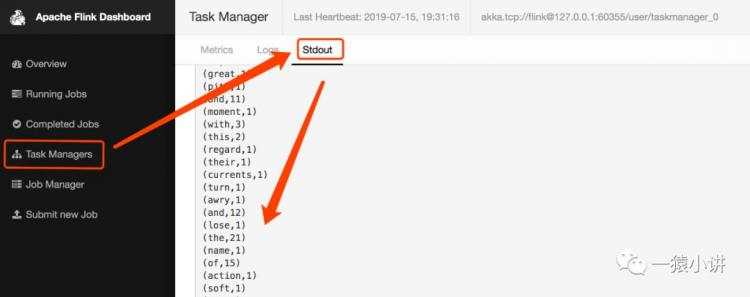
第四步:结果在哪里?关注点在哪里,结果就在哪里。
4.
无界的数据处理(再次装文艺书生有没有)。我这定义了一个端口 9000,麻烦 flink 你连上我,这样咱俩就可以秘密通讯了,我时不时会给你暗送秋波,但是你一定要每隔 5 秒统计一下,当前我给你说的每个词出现的数量,因为词词珠玑(捂嘴笑)。
第一步:启动本地服务。我们通过 netcat 命令来启动本地服务,然后就可以不停的说出对 flink 的热爱。

如果报错,根据报错进行提示安装 nc,我相信一猿小讲的粉丝肯定秒秒钟都能搞定。
第二步:提交 SocketWindowWordCount.jar 程序。其实 flink 早已按捺不住啦,尽管放马过去吧。
打开新的窗口,键入如下命令:
./bin/flink run examples/streaming/SocketWindowWordCount.jar --port 9000
看一看 flink 羞涩的反应。

第三步:看看效果,一睹芳容。
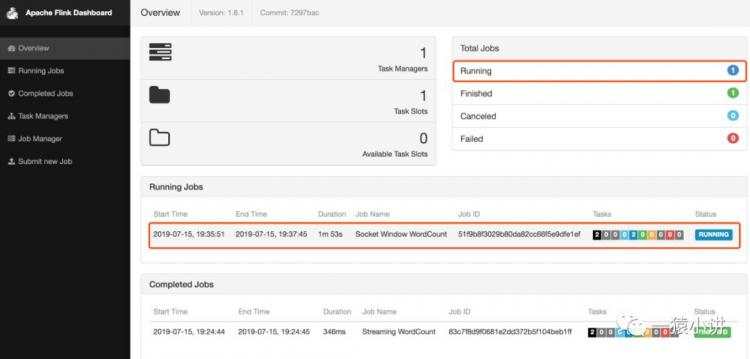
第四步:千万别矜持,说出你对 flink 的热爱,来点真情看看 flink 的反应?
在 nc 打开的窗口写一些文本,回车一行就发送一行输入给Flink。

不错不错,统计效果杠杠的。
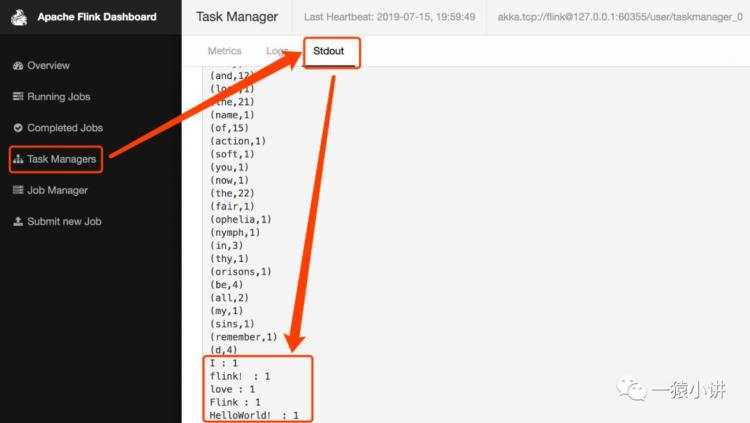
能否再浪漫一些,再多真情吐露一些。
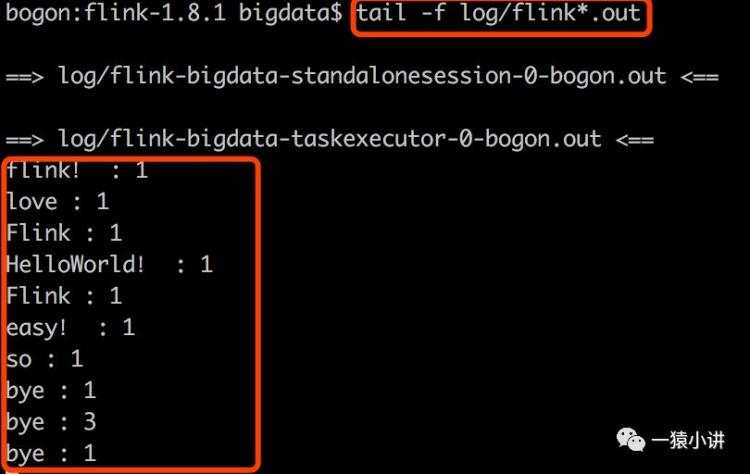
在控制台看看 flink 的娇羞的样子。新开一个窗口,执行
效果确实杠杠滴
也可以在页面一睹 flink 那羞涩的反应。
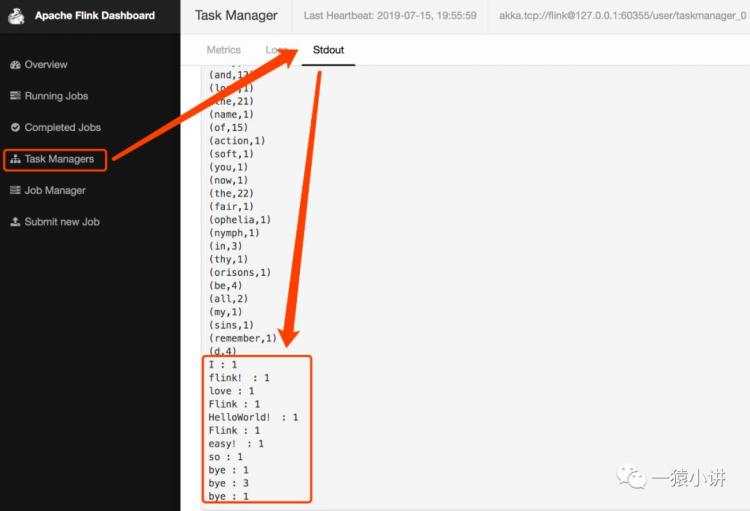
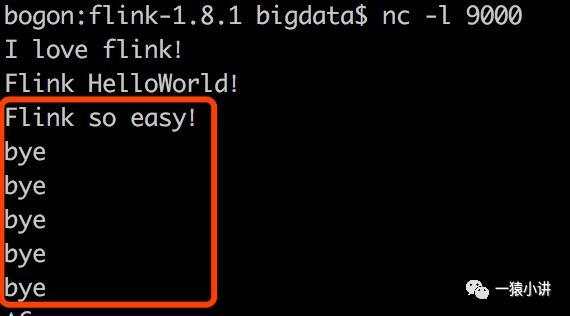
第五步:真情吐露完成,退出 nc,flink 还有点不舍。

视力不好,我们把上面的图拆开放大了看。退出 nc 的效果如下。
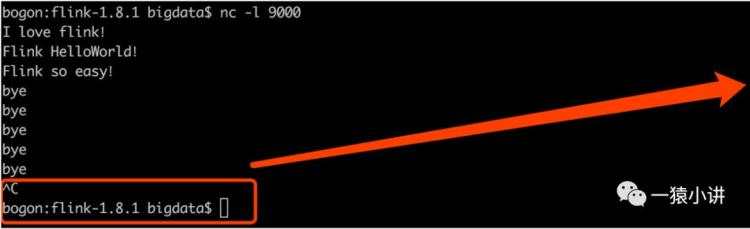
当我们断开 nc 时,flink 的反应流露出有点不舍,效果如下。

5.
好了,收工!到这两个 flink 的 HelloWorld 都完事了,我们也一起入门了。flink 你释放资源吧,你也休息一会儿吧。
输入命令:
效果如下:

6.
先实践再理论,HelloWorld 实践完,不妨抛俩概念玩一玩。
概念一:流?
注意,这里说的可不是流氓的流。咱们想指的是信用卡交易、传感器测量、机器日志、网站或移动应用程序上的用户交互记录,等等所有这些数据都形成的一种流。不过任何类型的数据,都可以形成一种事件流。
概念二:无界流 vs 有界流?
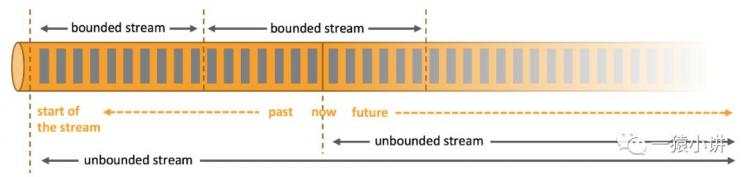
无界流有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。
有界流有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理。
概念三:那话说回来 flink 到底是啥东东?
Apache Flink 擅长处理无界和有界数据集。精确的时间控制和状态化使得 Flink 的运行时(runtime)能够运行任何处理无界流的应用。有界流则由一些专为固定大小数据集特殊设计的算法和数据结构进行内部处理,产生了出色的性能。
概念四:流式技术哪家强?
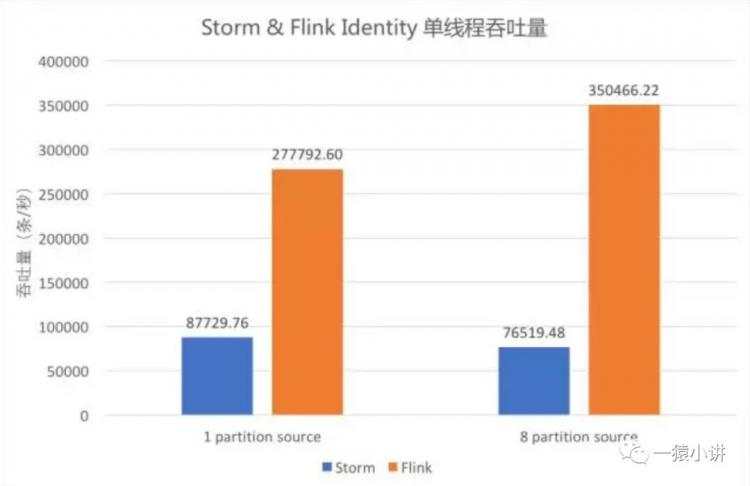
从网上邂逅到这张图(若侵、速删),并摘了个结论:如图中蓝色柱形为单线程 Storm 作业的吞吐,橙色柱形为单线程 Flink 作业的吞吐,可以看出,Flink 吞吐约为 Storm 的 3-5 倍。至于 Flink vs Spark 的事情就交给你去问度娘或者谷哥吧,搜之会一大堆。
7.好了,今天的分享就带你成功迈入大数据之 flink 的大门,希望对你有收获。
最后,还是那句话:跳出舒适区、持续不断的学习;跳出系统之外,会别有一番滋味涌上心头。

![基于Linux开源VOIP系统LinPhone[四]](https://img.php1.cn/3cd4a/1eebe/cd5/ed19db63ee478b98.png)





 京公网安备 11010802041100号
京公网安备 11010802041100号