篇首语:本文由编程笔记#小编为大家整理,主要介绍了软件测试八大典型的黑盒测试方法已来袭,快快接住!相关的知识,希望对你有一定的参考价值。
有了软件缺陷的暴露,我们就需要通过各种软件测试的方法来查找出软件的漏洞,编写出测试用例,及时修改bug。
测试路上不迷茫:关注微信公众号【程序员小濠】(主要分享软件测试的学习资源,帮助想转行、进阶、小白成为高级测试工程师…软件测试交流群:175317069)
在下面的这篇文章中,我们将谈论八大典型的黑盒测试方法,一起来学习⑧💡
一个程序可以有多个输入,等价类划分就是将这些输入数据按照输入需求进行分类,将它们划分为若干个子集,这些子集即为等价类(某个输入域的子集合),在每个等价类中选择有代表性的数据设计测试用例。
举个例子:
这种方法类似于学生站队,男生站左边,女生站右边,老师站中间,这样就把师生这整个群体划分成了三个等价类。 
(1)先从程序规格说明书中找出各个输入条件; (2)再为每个输入条件划分等价类,形成若干互不相交的子集; (3)列出等价表
| 输入条件 | 有效等价类 | 无效等价类 |
|---|---|---|
| …… | …… | …… |
等价类划分法设计测试用例要经历划分等价类(列出等价类表)和选取测试用例两步。
(1)划分等价类
等价类是指某个输入域的子集合。在该子集合中,各个输入数据对于揭露程序中的错误都是等效的。测试代表值就等价于这一类其他值的测试。
那在划分等价类的时候,会出现有效等价类和无效等价类,这个时候我们需要怎么判断呢?
有效等价类就是有效值的集合,它们是符合程序要求、合理且有意义的输入数据。
无效等价类就是无效值的集合,它们是不符合程序要求、不合理或无意义的输入数据。
因此,在设计测试用例时,要同时考虑有效等价类和无效等价类的设计。
同时,在划分等价类的时候,需要遵循一定的划分原则:
等价类划分原则:
原则1:如果输入条件规定了取值范围或值的个数的情况下,可以确定一个有效等价类和两个无效等价类。
原则2:如果输入条件规定了输入值的集合或者规定了**“必须如何”的条件**的情况下,可以确立一个有效等价类和一个无效等价类。
原则3:如果输入条件是一个布尔量的情况下,可确定一个有效等价类和一个无效等价类。
原则4:如果规定了输入数据的一组值(假定n个),并且程序要对每一个输入值分别处理的情况下,可确定n个有效等价类和一个无效等价类。
原则5:如果规定了输入数据必须遵守的规则,可确定一个有效等价类(符合规则)和若干个无效等价类(从不同角度违反规则)。
原则6:在确知已划分的等价类中,各元素在程序处理中的方式不同的情况下,则应再将该等价类进一步地划分为更小的等价类。
同一个等价类中的数据发现程序缺陷的能力是相同的,如果使用等价类中的其中一个数据不能捕获缺陷,那么使用等价类中的其他数据也不能捕获缺陷;同样,如果等价类中的其中一个数据能够捕获缺陷,那么该等价类中的其他数据也能捕获缺陷,即等价类中的所有输入数据都是等效的。
(2)设计测试用例
看到这里,不妨再做下案例分析。
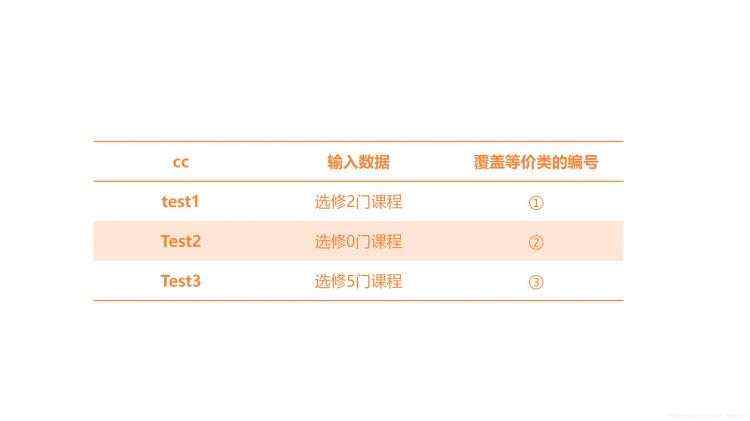
案例1:每个学生可以选修1~3门课程,要求采用等价类设计测试用例。
解题思路:首先分析有效等价类和无效等价类,然后建立等价类表。
【解析】
(1)根据题干分析有效等价类和无效等价类:
有效等价类:选修1~3门课
无效等价类:没有选修课、选修3门课以上
(2)根据分析建立等价类表:

(3)根据等价类表设计测试用例覆盖有效等价类和无效等价类:
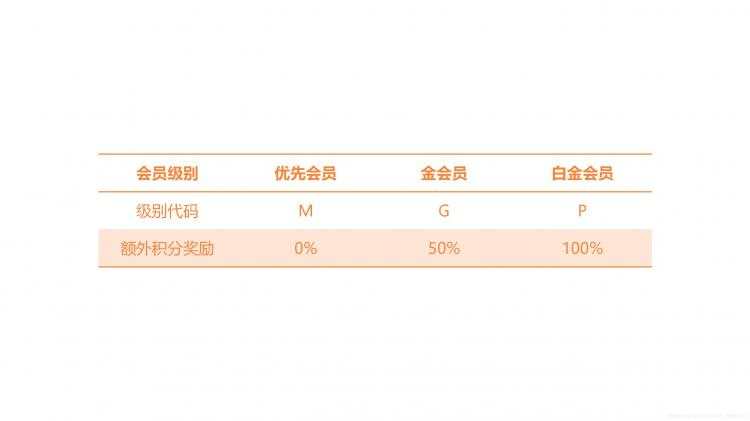
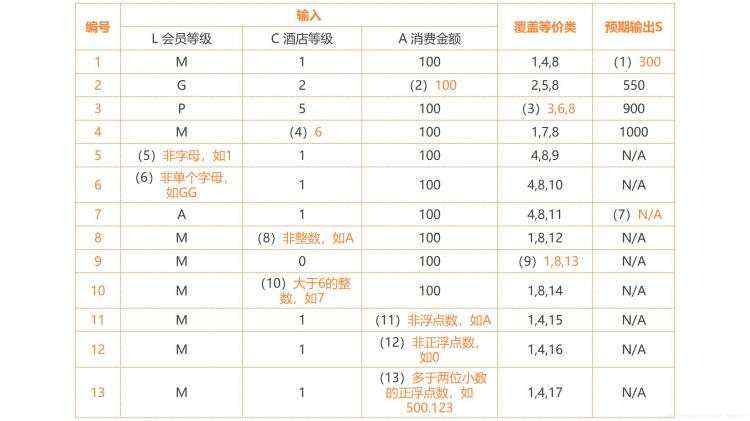
案例2:某连锁酒店集团实行积分奖励计划,会员每次入住集团旗下酒店均可以获得一定积分,积分由欢迎积分加消费积分构成。其中欢迎积分跟酒店等级有关,具体标准如表1-1所示;消费积分跟每次入住消费金额有关,具体标准为每消费1元获得2积分(不足1元的部分不给分)。此外,集团会员分为优先会员、金会员、白金会员三个级别,金会员和白金会员在入住酒店时可获得消费积分的额外奖励,奖励规则如表1-2所示。
表1-1 集团不同等级酒店的欢迎积分标准
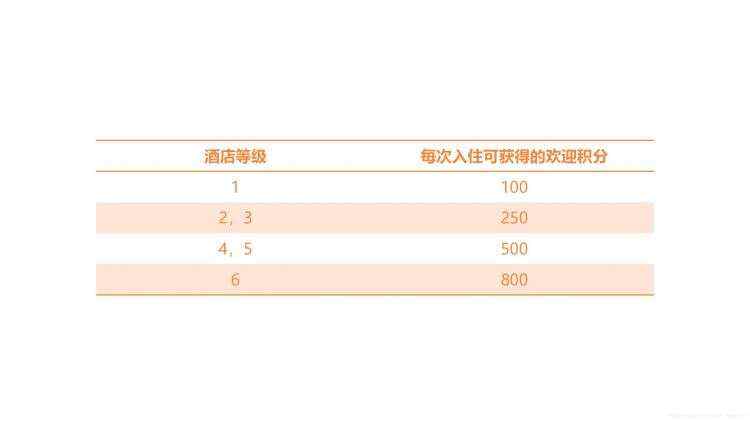
表1-2 额外积分奖励规则
该酒店集团开发了一个程序来计算会员每次入住后所累积的积分,程序的输入包括会员级别L、酒店等级C和消费金额A(单位:元),程序的输出为本次积分S。其中,L为单个字母且大小写不敏感,C为取值1到6的整数,A为正浮点数且最多保留两位小数,S为整数。
【问题一】采用等价类划分法对该程序进行测试,等价类表如表1-3所示,请补充表中空(1)-(7)。 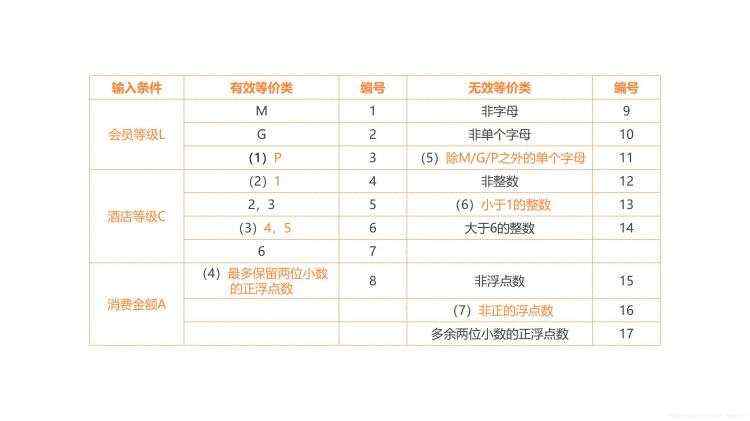
【问题二】根据以上等价类表设计的测试用例如下表所示,请补充表2-4中空(1)-(13)。
(1)边界值分析法是对软件的输入或输出边界进行测试的一种方法,它通常作为等价类划分法的一种补充测试。
(2)在等价类划分法中,无论是输入等价类还是输出等价类,都会有多个边界,而边界值分析法就是在这些边界附近寻找某些点作为测试数据,而不是在等价类内部选择测试数据。
设计测试用例步骤:
(1)首先划分等价类,根据等价类划分情况确定边界情况。
(2)选取正好等于、刚刚大于、刚刚小于边界的值作为测试数据,而不是选取等价类中的典型值或任意值。
原则1:如果输入条件规定了值的范围,则应取刚达到这个范围的边界的值,以及刚刚超越这个范围边界的值作为测试输入数据
原则2:如果输入条件规定了值的个数,则用最大个数、最小个数、比最小个数少1、比最大个数多1的数作为测试数据
原则3:根据规格说明的每个输出条件,使用前面的原则1。
原则4:根据规格说明的每个输出条件,使用前面的原则2。
原则5:如果程序的规格说明给出的输入域或输出域是有序集合,则应选取集合的第一个元素和最后一个元素作为测试用例。
原则6:如果程序中使用了一个内部数据结构,则应该选择这个内部数据结构边界上的值作为测试用例。
原则7:分析规格说明,找出其他可能的边界条件。
错误推测法就是人们可以靠经验和直觉推测程序中可能存在的各种错误,从而有针对性地编写检查这些错误的例子。
(1)列举出程序中所有可能有的错误和容易发生错误的特殊情况(比如,程序只能输入数字,测试时可以输入字母进行测试)。 (2)根据它们选择测试用例。
如果在测试时必须考虑输入条件的各种组合以及各种输出情况,那么可以使用一种适用于描述对于多种条件的组合,相应产生多个动作的形式来设计测试用例,这就需要利用因果图。
因果图使用一些简单的逻辑符号和直线将程序的因(输入)与果(输出)连接起来,一般原因用ci表示,结果用ei表示,各结点表示状态,可以取值“0”或“1”,其中“0”表示状态不出现,“1”表示状态出现。
如下图所示:
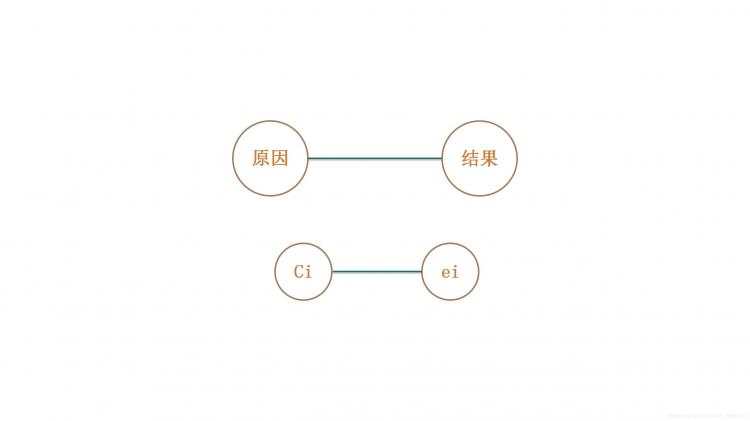
ci与ei之间有恒等、非(~)、或(∨)、与(∧)4种关系,分别为:
恒等:在恒等关系中,要求程序有一个输入和一个输出,输出与输入保持一致。若c1为1,则e1也为1,若c1为0,则e1也为0。
非:非使用符号“~”表示,在这种关系中,要求程序有一个输入和一个输出,输出是输入的取反。若c1为1,则e1为0,若c1为0,则e1为1。
或:使用符号“∨”表示,或关系可以有任意个输入,只要这些输入中有一个为1,则输出为1,否则输出为0。
与:使用符号“∧”表示,与关系也可以有任意个输入,但只有这些输入全部为1,输出才能为1,否则输出为0。
以下用一张图展示这4种关系: 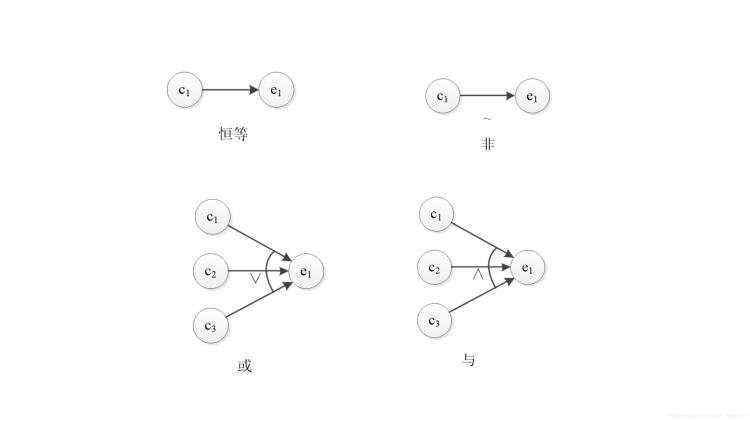
总结:
- 在软件测试中,如果程序有多个输入,那么除了输入与输出之间的作用关系之外,这些输入之间往往也会存在某些依赖关系,某些输入条件本身不能同时出现,某一种输入可能会影响其他输入。
- 例如,某一软件用于统计体检信息,在输入个人信息时,性别只能输入男或女,这两种输入不能同时存在,而且如果输入性别为女,那么体检项就会受到限制。
为了表示原因与原因之间,原因与结果之间可能存在的约束条件,在因果图中可以附加一些表示约束条件的符号。
(1)输入条件的约束类别可分为四种:
E(Exclusive,这些依赖关系在软件测试中称为“约束”,异)、I(at least one,或)、O(one and only one,唯一)、R(Requires,要求),在因果图中,用特定的符号表明这些约束关系。
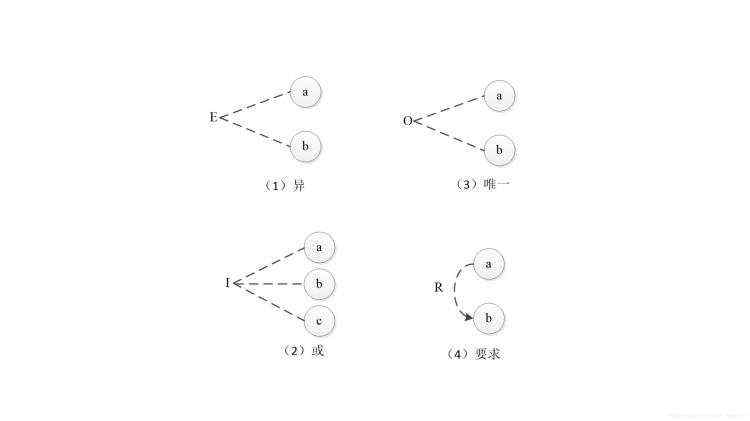
(2)输出条件的约束类别只有一种:
(1)因果图设计测试用例思想:
从程序规格说明书的描述中,找出因(输入条件)和果(输出结果或者程序状态的改变);
通过因果图转换为判定表;
为判定表中的每一列设计一个测试用例;
(2)使用因果图设计测试用例的步骤:
分析程序规格说明书描述内容,确定程序的输入与输出,即确定“原因”和“结果” 。
分析得出输入与输入之间、输入与输出之间的对应关系,将这些输入与输出之间的关系使用因果图表示出来。
由于语法与环境的限制,有些输入与输入之间、输入与输出之间的组合情况是不可能出现的,对于这种情况,使用符号标记它们之间的限制或约束关系。
将因果图转换为决策表,根据决策表设计测试用例。(决策表将在标题五判定表驱动法中提到)
因果图法的优点:
考虑到了输入情况的各种组合以及各个输入情况之间的相互制约关系。
因果图的约束关系可以有效简化决策表,帮助测试人员高效率的开发测试用例。
因果图法是将自然语言规格说明转化成形式语言规格说明的一种严格的方法,可以指出规格说明存在的不完整性和二义性。
程序的规格说明要求:输入的第一个字符必须是#或*,第二个字符必须是一个数字,在此情况下进行文件的修改;如果第一个字符不是#或*,则给出信息N,如果第二个字符不是数字,则给出信息M。采用因果图法设计该软件的测试用例。
具体解析如下: (1)分析程序规格说明中的原因和结果:
原因 结果 C1:第一个字符是# e1:给出信息N C2:第一个字符是* e2:修改文件 C3:第二个字符是一个数字 e3:给出信息M
(2)画出因果图:
(3)将因果图转换成判定表,3个条件一般可以有2³种组合
1 2 3 4 5 6 7 8 原因 c1 1 1 1 1 0 0 0 0 c2 1 1 0 0 1 1 0 0 c3 1 0 1 0 1 0 1 0 结果 e1 ✔ ✔ e2 ✔ ✔ e3 ✔ ✔ (4)简化判定表,第7列和第8列合并 1 2 3 4 5 6 7 :--: :--: :--: :--: :--: :--: :--: :--: :--: 原因 c1 1 1 1 1 0 0 0 c2 1 1 0 0 1 1 0 c3 1 0 1 0 1 0 - 结果 e1 ✔ e2 ✔ ✔ e3 ✔ ✔ (5)根据判定表生成测试用例 测试用例ID 输入数据 输出结果 :--------: :------: :-------: 1 #3 修改文件 2 #M 给出信息M 3 *5 修改文件 4 *A 给出信息M 5 MM 给出信息N
判定表也称为决策表,其实质就是一种逻辑表。在程序设计发展初期,判定表就已经被当作程序开发的辅助工具了,帮助开发人员整理开发模式和流程,因为它可以把复杂的逻辑关系和多种条件组合的情况表达的既具体又明确,利用判定表可以设计出完整的测试用例集合。
为了让大家明白什么是判定表,下面通过一个“图书阅读指南”来制作一个判定表,图书阅读指南指明了图书阅读过程中可能出现的状况,以及针对各种情况给读者的建议。
(1)在图书阅读过程中可能会出现3种情况:
如果回答是肯定的,则使用“Y”标记;
如果回答是否定的,则使用“N”标记。
那么这3种情况可以有2³=8种组合,针对这8种组合。
(2)阅读指南给读者提供了4条建议:
(3)针对以上分析,得出以下图书阅读指南判定表。
| 问题与建议 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|---|
| 问题 | 是否疲倦 | Y | Y | Y | Y | N | N | N | N |
| 是否对内容感兴趣 | Y | Y | N | N | N | Y | Y | N | |
| 对书中内容是否感到糊涂 | Y | N | N | Y | Y | Y | N | N | |
| 建议 | 回到本章开头重读 | ✔ | |||||||
| 继续读下去 | ✔ | ||||||||
| 跳到下一章去读 | ✔ | ✔ | |||||||
| 停止阅读并休息 | ✔ | ✔ | ✔ | ✔ |
(4)在实际测试中,条件桩往往很多,而且每个条件桩都有真假两个条件项,有n个条件桩的判定表就会有2n种条件规则,如果每条规则都设计一个测试用例,不仅工作量大,而且有些工作量可能是重复的无意义的。例如在“图书阅读指南”中,第1、2条规则,第1条规则取值为:Y、Y、Y,执行结果为“停止阅读并休息”;第2条规则取值为:Y、Y、N,执行结果也是为“停止阅读并休息”;对于这两条规则来说,前两个问题的取值相同,执行结果一样。
这些不影响结果取值的问题称为无关条件项,用“-”表示。忽略无关条件项,可以将两条规则合并。
合并规则需要满足如下两个条件:①两条规则采取的动作相同;②两条规则的条件项取值相似。
(5)根据合并规则,可以将“图书阅读指南”判定表合并。
| 问题与建议 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| 问题 | 是否疲倦 | Y | Y | N | N | N |
| 是否对内容感兴趣 | Y | N | N | Y | Y | |
| 对书中内容是否感到糊涂 | - | - | - | Y | N | |
| 建议 | 回到本章开头重读 | ✔ | ||||
| 继续读下去 | ✔ | |||||
| 跳到下一章去读 | ✔ | |||||
| 停止阅读并休息 | ✔ | ✔ |
判定表是把作为条件的所有输入的各种组合值以及对应的输出值都罗列出来而形成的表格,判定表由4个部分组成,判定表结构如下:
| 条件桩 | 条件项 |
|---|---|
| 动作桩 | 动作项 |
其中每一列称为一个规则。判定表的4个部分分别为:
在判定表中,任何一个条件组合的特定取值及其相应要执行的操作称为一条规则,即判定表中的每一列就是一条规则,每一列都可以设计一个测试用例,根据判定表设计测试用例就不会有所遗漏。
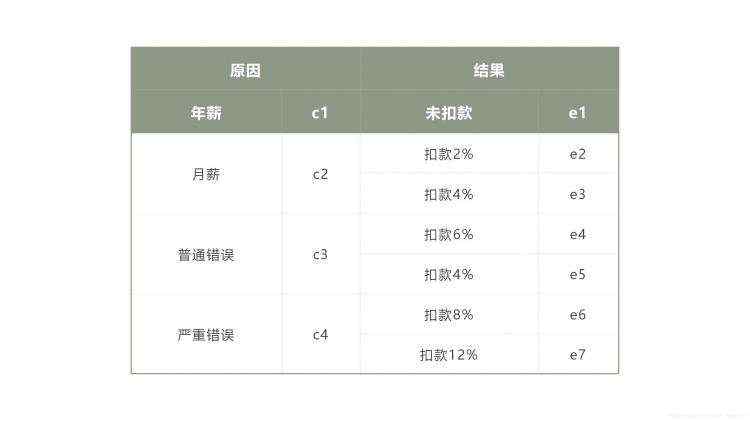
某公司的薪资管理制度如下:员工工资分为年薪制与月薪制两种,员工的错误定位包括普通错误与严重错误两种,如果是年薪制的员工,犯普通错误扣款2%,犯严重错误扣款4%;如果是月薪制的员工,犯普通错误扣款4%,犯严重错误扣款8%。该公司编写了一款软件用于员工工资计算发放,现在要对该软件进行测试。
对公司员工工资管理进行分析,可得出员工工资由4个因素决定:年薪、月薪、普通错误、严重错误。其中,年薪与月薪不可能同时并存,但普通错误与严重错误可以并存。
员工最终扣款结果有7种:未扣款、扣款2%、扣款4%、扣款6%(2%+4%)、扣款4%、扣款8%、扣款12%(4%+8%)。
采用判定表驱动法设计该软件的测试用例。
具体解析如下:
(1)分析员工工资的原因和结果:
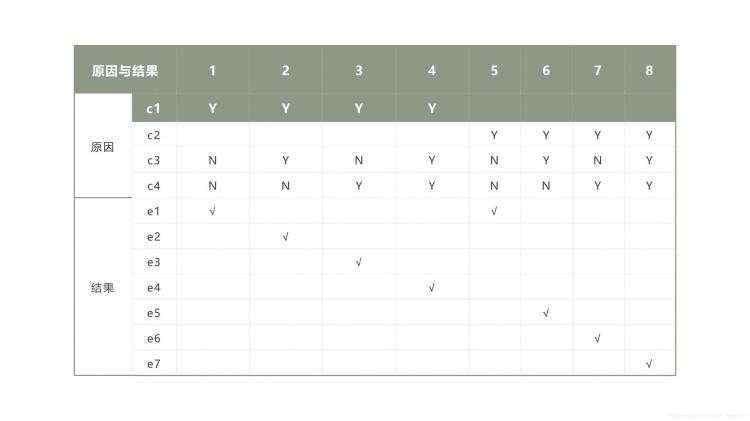
(2)有4个原因,每个原因有“Y”和“N”两个取值,理论上可以组成24=16种规则,但是c1与c2不能同时并存,因此有23=8种规则。得出员工工资判定表如下:
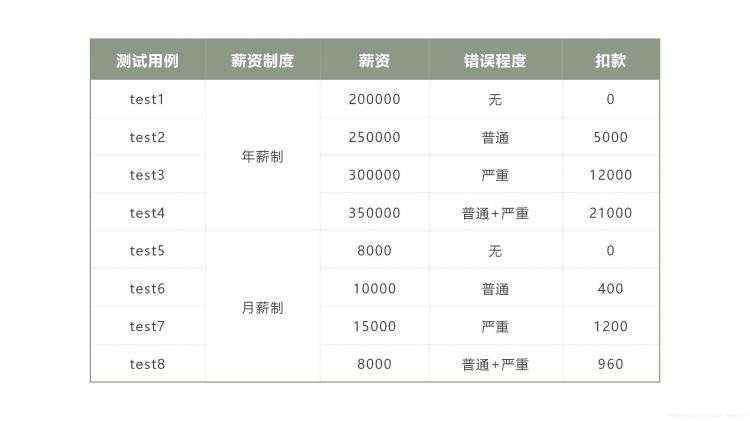
(3)最终得出员工工资测试用例表:
正交实验设计法(Orthogonal experimental design)是指从大量的实验点中挑选出适量的、有代表性的点,依据Glois理论导出“正交表”,从而合理的安排实验的一种实验设计方法。
接下来对这三个步骤进行一一解析。
(1)举个栗子(步骤一):
提取因子,构造因子状态表—— 即分析软件的规格需求说明得到影响软件功能的因子,确定因子可以有哪些取值,即确定因子的状态。
例如,某一软件的运行受到操作系统和数据库的影响,因此影响其运行是否成功的因子有操作系统和数据库两个,而操作系统有Windows、Linux、Mac三个取值,数据库有mysql、MongoDB、Oracle三个取值,因此操作系统的因子状态为3,数据库因子状态为3。得到如下因子-状态表:
| 因子 | 因子的状态 | ||
|---|---|---|---|
| 操作系统 | Windows | Linux | Mac |
| 数据库 | MySQL | MongoDB | Oracle |
(2)举个栗子(步骤二):
加权筛选,简化因子状态表 —— 在实际软件测试中,软件的因子及因子的状态会有很多,每个因子及其状态对软件的作用也大不相同,如果把这些因子及状态都划分到因子-状态表中,最后生成的测试用例会相当庞大,从而影响软件测试的效率。因此需要根据因子及状态的重要程度进行加权筛选,选出重要的因子与状态,简化因子-状态表。
(3)举个栗子(步骤三):
构建正交表,设计测试用例 —— 正交表的表示形式为 Ln(tc) 来表示。
下面举出两个例子辅助理解: 例1: L4(23) 是最简单的正交表,它表示该实验有3个因子,每个因子有两个状态,可以做4次实验,如果用0和1表示每个因子的两种状态,则该正交表就是一个4行3列的表。 正交表如下图所示: 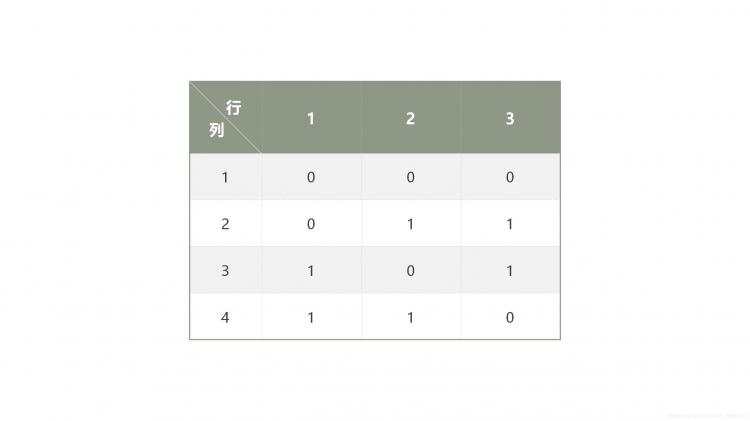 例2: 在实际软件测试中,大多数情况下,软件有多个因子,每个因子的状态数目都不相同,即各列的水平数不等,这样的正交表称为混合正交表,如L8(24 + 41) ,这个正交表表示有4个因子有2种状态,有1个因子有4种状态。 那么正交表的行数为
例2: 在实际软件测试中,大多数情况下,软件有多个因子,每个因子的状态数目都不相同,即各列的水平数不等,这样的正交表称为混合正交表,如L8(24 + 41) ,这个正交表表示有4个因子有2种状态,有1个因子有4种状态。 那么正交表的行数为 n= ∑(每列水平数t-1)+ 1 = (2-1)×4 + (4-1)×1 + 1 = 8,这个n值的计算如果发生在大型项目时往往是很难计算的。 所以,混合正交表往往难以确定测试用例的数目,即n的值。因此,在这种情况下,可以登录正交表的一些权威网站,查询n值,下面给大家提供一个正交表查询网站, 在这里,可以查询到不同因子数、不同水平数的正交表的n值。 最终得出,该混合正交表如下图所示: 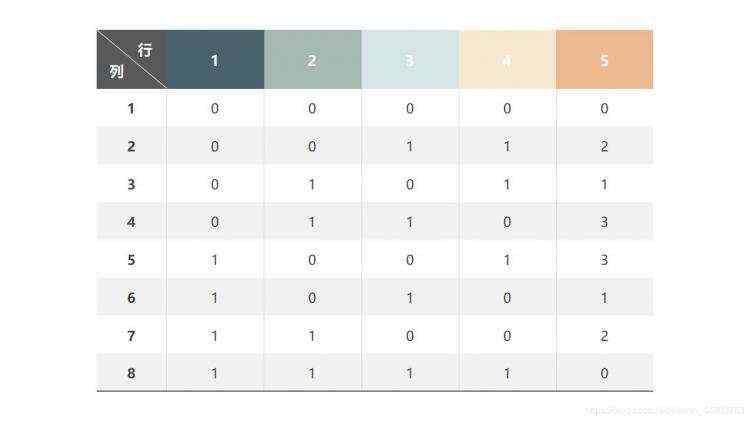
正交表最大的特点是取点均匀分散、齐整可比,每一列中每种数字出现的次数都相等,即每种状态的取值次数相等。
写到这里,对正交实验设计法做个小结:
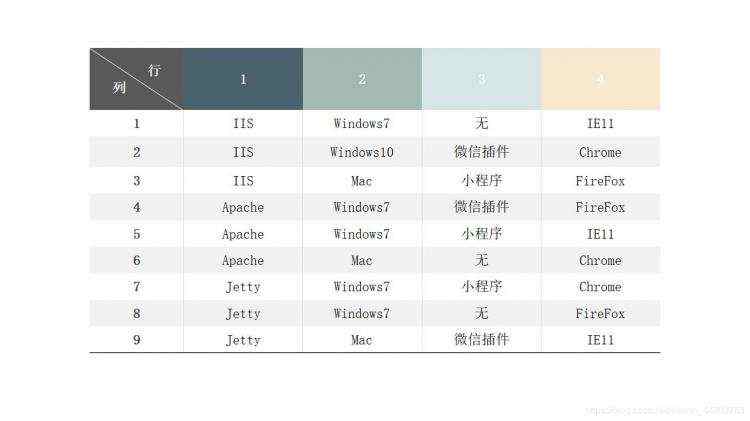
微信是一款手机App软件,但它也有web版微信可以登录,如果要测试微信web页面运行环境,需要考虑多种因素,在众多的因素中,我们可以选出几个影响比较大的因素,如服务器、操作系统,插件和浏览器。利用正交实验设计法设计该软件的测试用例。
具体解析如下: (1)提取因子,构造因子状态表
对于选取出的4个影响因素,每个因素又有不同的取值,同样,在每个因素的多个值中,可以选出几个比较重要的值。如:
服务器:IIS、Apache、Jetty;
操作系统:Windows7、Windows10、Mac;
插件:无、小程序、微信插件;
浏览器:IE11、Chrome、FireFox;
构造的因子状态表如下:
因子 因子的状态 操作系统 IIS Apache Jetty 数据库 Windows7 Windows10 Mac 插件 无 小程序 微信插件 浏览器 IE11 Chrome FireFox
(2)加权筛选,简化因子状态表
- 微信web版运行环境正交实验中有4个因子:服务器、操作系统、插件、浏览器,每个因子又有3个水平,因此该正交表是一个4因子3水平正交表。
- 所以正交表的行数为 `n= ∑(每列水平数t-1)+ 1 = (3-1)×4 + 1 =
9`,因此正交表的表示形式为L9(34)。
- 得出n=9后,查表可得,简化后的因子状态表如下:
(3)构建正交表,设计测试用例
- 将因子、状态映射到正交表,可生成具体的测试用例,具体如下表:
现在的软件几乎都是由事件来触发的,事情触发便形成了场景,而同一事件不同的触发顺序和处理结果就形成了事件流。
场景可以看成是基本流与备选流的集合。用例的场景用来描述流经用例的路径,从用例的开始到结束遍历这条路径上所有的基本流和备选流。
基本事件流,从系统某个初始状态开始,经一系列状态后,到达最终状态的一个业务流程,并且是最主要、最基本的一个业务流程(无任何差错,程序从开始直接到执行结束)。
备选事件流,以基本流为基础,在基本流所经过的每个判定节点处满足不同的触发条件而导致的其他事件流。
先用一张图来描述基本流和备选流的流程。 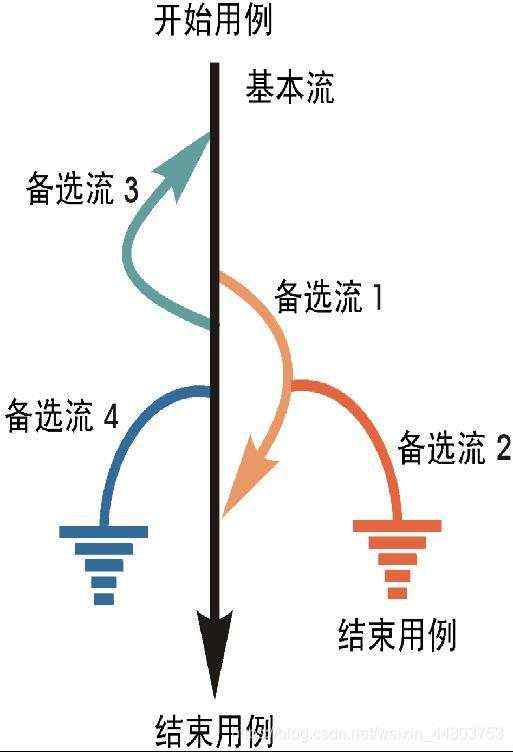
从上图可以看出,图中经过用例的每条路径都用基本流和备选流来表示。
基本流:采用直黑线表示,是经过用例的最简单的路径。
备选流:采用不同色彩表示,一个备选流可能从基本流开始,在某个特定条件下执行,然后重新加入基本流中(如备选流1和3);也可能起源于另一个备选流(如备选流2),或者终止用例而不再重新加入到某个流(如备选流2和4)。
根据图中每条经过的可能路径,从基本流开始,再经过基本流、备选流的综合,可以确定不同的用例场景,如下: 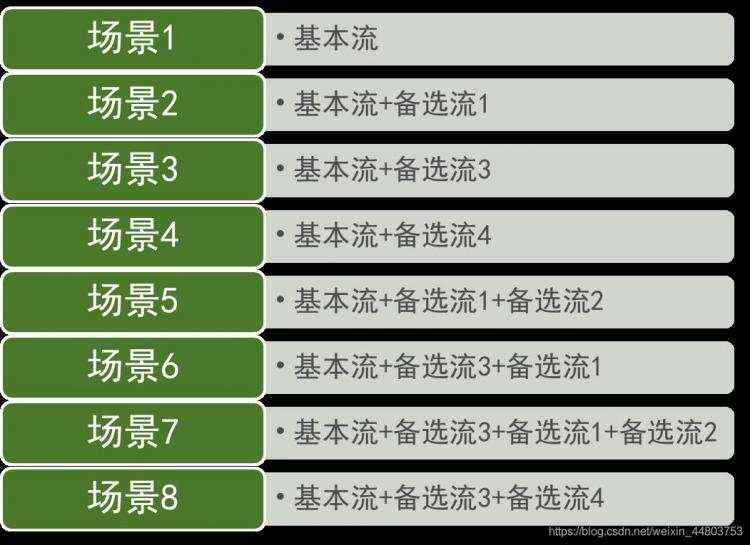 基于以上例子,可以得出以下结论:基本流只有一个,而备选流的数目则取决于基本流上判定节点的数目与事务分析的颗粒度,颗粒度越细,考虑越周全,得到的备选流数目就越多,相应的测试工作量就越大。
基于以上例子,可以得出以下结论:基本流只有一个,而备选流的数目则取决于基本流上判定节点的数目与事务分析的颗粒度,颗粒度越细,考虑越周全,得到的备选流数目就越多,相应的测试工作量就越大。
场景法设计测试用例的基本步骤如下:
(1) 根据需求规格说明,描述出程序的基本流及各项备选流。
(2) 根据基本流和各项备选流生成不同的场景。
(3) 对每一个场景生成相应的测试用例。
(4) 对生成的所有测试用例重新复审,去掉多余的测试用例。测试用例确定后,对每一个测试用例确定测试数据值。
写到这里,对场景法做个小结:
有一个在线购物的实例:用户进入一个在线购物网站进行购物,选购物品后,进行在线购买,这时需要使用账号登录;登录成功后,进行付钱交易;交易成功后,生成订购单;完成整个购物过程。请使用场景法设计测试用例。
案例解析如下:
(1)确定基本流和备选流
- 基本流:登录在线购物网站,选择物品,登录账号,付钱交易,生成订购单。
- 备选流1:账号不存在。
- 备选流2:密码错误。
- 备选流3:货物库存不足。
- 备选流4:账号余额不足。
(2)根据基本流和备选流来确定场景,如下表:
表 购物系统场景表
场景1:成功购物 基本流 场景2:账号不存在 备选流1 场景3:密码错误 备选流2 场景4:货物库存不足 备选流3 场景5:用户账号余额不足 备选流4
(3)根据每一个场景,设计需要的测试用例
【解析】
可以采用矩阵或判定表来确定和管理测试用例,下面介绍一种通用的格式,其中各行代表各个测试用例,而各列则代表测试用例的信息。 在矩阵中,
- V(有效)用于表明这个条件必须是VALID(有效的)才可执行基本流;
- I(无效)用于表明这种条件下将激活所需备选流;
- N/A(不适用)表明这个条件不适用于测试用例。
购物系统场景矩阵见下表:
表 购物系统场景矩阵
测试用例ID 场景 账号 密码 购买商品数量 商品库存数量 用户账号余额 预期结果 1 场景1:成功购物 V V V V V 成功购物 2 场景2:账号不存在 I N/A N/A N/A N/A 提示账号不存在 3 场景3:密码错误 V I N/A N/A N/A 提示密码输入有误 4 场景4:购买商品库存不足 V V V I N/A 提示库存不足 5 场景5:用户账号余额不足 V V V V I 提示账号余额不足
(4)设计具体的测试用例数据(假设所购物品单价为30元)
表 购物系统具体测试用例
场景 测试用例ID 账号 密码 购买商品数量 商品库存数量 用户账号余额 预期结果 场景1:成功购物 1 admin123 test123 10件 50件 2000元 成功购物 场景2:账号不存在 2 admin N/A N/A N/A N/A 提示账号不存在 场景3:密码错误 3 admin123 test N/A N/A N/A 提示密码输入有误 场景4:购买商品库存不足 4 admin123 test123 60件 50件 N/A 提示库存不足 场景5:用户账号余额不足 5 admin123 test123 10件 50件 200元 提示账号余额不足
功能图法目前的使用频率较低,此处不做细讲……
写到这里,对上面八大黑盒测试方法做个小结。
(1) 首先进行等价类划分,包括输入条件和输出条件的等价划分,将无限测试变成有限测试,这是减少工作量和提高测试效率最有效的方法。
(2) 在任何情况下都必须使用边界值分析方法。经验表明,用这种方法设计出的测试用例发现程序错误的能力最强。
(3) 可以用错误推测法追加一些测试用例,这需要依靠测试工程师的智慧和经验。
(4) 对照程序逻辑,检查已设计出的测试用例的逻辑覆盖程度。如果没有达到要求的覆盖标准,应当再补充足够的测试用例。
(5) 如果程序的功能说明中含有输入条件的组合情况,则一开始就可选用因果图法和判定表。
(6)对于参数配置类的软件,要用正交试验法选择较少的组合方式达到最佳效果。
(7) 对于业务流清晰的软件,可以使用场景贯穿测试,再综合使用各种测试方法。
(1)优点:①对较大的代码单元来说,黑盒测试比白盒测试的效率高 ,测试人员不需要了解实现的细节,包括特定的编程语言;②测试人员和编程人员是相互独立的,从用户的角度进行测试,很容易被接受和理解,有助于暴露任何与规格不一致或者歧异的地方,测试用例可以在规格完成后马上进行。
(2)缺点:不能测试程序内部特定部位,比如程序未执行的代码,这些代码得不到测试,则无法发现错误。若没有清晰的和简明的规格,测试用例很难被设计,不易进行充分性测试。
黑盒测试相较于白盒测试来说比较简单,不需要了解程序内部的代码,与软件的内部实现无关;从用户角度出发,能很容易的知道用户会使用到哪些功能,会遇到哪些问题;并且是基于软件开发文档做的相关测试,能较清楚地了解软件实现了文档中的哪些功能。
八大典型的黑盒测试方法讲解到这里就结束啦!如有不理解或者有误的地方欢迎评论区或私聊我交流~
下一篇文章将讲解白盒测试。
- 关注公众号 程序员小濠,不定期分享学习干货,学习路上不迷路~
- 如果这篇文章对你有用,记得点个赞加个关注再走哦~






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有