作者:龙love猫 | 来源:互联网 | 2023-08-28 14:08
篇首语:本文由编程笔记#小编为大家整理,主要介绍了面试突击Redis,一篇就够了相关的知识,希望对你有一定的参考价值。
如何快速从海量数据中查询某一固定前缀的key?
keys指令一次性返回出所有符合条件的key,当有很多key时则会造成阻塞。(如果如此回答就糟糕了!)
正确的用法是scan指令,它是基于游标的迭代器,可以一次取一点,不会造成过大压力。用法为:SCAN cursor [MATCH pattern] [COUNT count],每次会返回cursor,我们把cursor作为下一次的cursor输入。
如何通过Redis实现分布式锁?
需要解决四个问题:互斥性、安全性、死锁、容错
使用SETNX指令,当该指令成功的时候返回1,失败的时候返回0。SETNX表示如果该key不存在才设置,如果存在则无法成功,因此如果设置成功就表示我们占有了这把分布式锁。我们就可以访问独占资源了。但是要怎么释放锁呢?我们通过EXPIRE key SECONDS来设置过期时间。但是有两个问题,假如setnx成功之后,但是在设置expire之间宕机了,就会一直持有锁,没有到期时间。另外,假如到期了但是还没有做完手头的临界资源访问怎么办?可以将到期时间设置得长一点,设置到期时间主要是为了防止持有锁时宕机而其他线程根本无法运行。
第一个问题我们通过指令 SET key value [EX seconds] [PX milliseconds] [NX|XX]来实现,这样setnx和expire就成了一个原子操作。
如何释放锁呢?首先检查当前key的value是否为requestId(即我们线程的标识符),若是则删除key即可。但是要注意,一定要在一个原子操作里面完成,因此我们使用lua脚本的形式来实现。通过eval命令。
如何处理大量key同时过期的问题?
集中过期,由于清除大量的key很耗时,可能会出现短暂的卡顿现象。解决方案:在设置key过期时间的时候,给每个key加上随机值。
如何实现异步队列?
先从List考虑,我们可以用rpush来发布消息,lpop来消费消息,但是有一个问题,lpop当我们没有消息的时候调用也会消费然后返回nil,这就要求我们的消费者在应用端需要sleep然后轮询。不太符合我们的要求。这时候我们可以使用一个blpop的命令(blocking pop),当没有消息可以消费时,就阻塞在那里,当可以消费后再返回。不过这种也有一个问题,就是它只能供一个消费者使用。所以最后我们使用pub/sub模式,消费者通过subscribe myTopic来对某个主题进行订阅,发布者通过publish myTopic hello来对某个主题进行消息的发送。但是它也有一些问题,不保证消息的接收,当某个subscriber下线一段时间后,这段时间所错过的消息就完全丢失了,因此我们还是更推荐使用专业的消息队列比如Kafka等等。
Redis如何做持久化?
redis有两种持久化方式:
使用RDB(快照 Snapshot)
该种方式是全量备份,每个时间点进行的RDB会生成一个dump.rdb的二进制文件。我们可以通过redis.conf配置是否开启rdb和自动保存的间隔:
save 900 1
save 300 10
save 60 10000 # 60s之内有10000条为写入指令就自动bgsave
save "" #关闭rdb
有两条指令可以手动备份:save和bgsave。save是使用当前的线程进行备份(非常不建议),bgsave首先检查有没有在aof或者rdb进程在进行保存操作。如无则当前线程fork一个子进程,由于Linux的Copy-On-Write机制,子进程刚开始与主进程是共享物理空间的,在主进程写入新的内容时会将新内容(专用副本)复制到主进程空间。子进程将内存内容写到磁盘临时文件,完成后用临时文件替换原来的快照文件。
rdb的文件的载入一般是在redis启动时自动载入的。
缺点:内存数据时全量同步的,如果比较频繁地话会由于I/O比较严重地影响性能。同时由于其存储有一定的时间间隔,可能会有部分数据丢失。
使用AOF(Append Only File)
会记录下除了查询以外的所有数据库的变更,是增量模式的记录。通过在配置中打开appendonly yes来实现,并且可以通过修改appendfsync everysec来修改多久写入一次aof文件。该种方式的保存同样是fork一个子进程来实现的。在重新载入时,如果有aof文件则载入aof,如果没有aof文件则考虑rdb文件重新载入。在Redis 4.0之后引入了一种混合模式,可以使用rdb进行全量复制,aof进行增量复制,恢复时首先恢复rdb文件,再用aof文件增量恢复。
AOF文件会遇到一个问题是由于记录所有对数据库的变动情况,因此文件会越来越大,所以我们可以使用bgrewriteaof来对aof日志文件进行重写,将多条语句进行合并,比如多个incr key合并成一个incrby,重写思路同样是fork一个子进程,然后子进程不断重写,主进程在此期间照常追加原来的aof文件,在子进程rewrite完成后追加新的内容到新文件中并替换原来的aof文件。
AOF文件的内容其实采用了和redis远程调用数据传输同样的协议,即resp协议,该协议格式比较简单,大概如下:
为什么要使用pipeline?
redis是请求响应模型,而如果有大量的请求但是每次都提交到redis服务器然后获得响应,一来一回往返开销非常大,尤其是异地机房的情况。pipeline就是将很多命令打包起来,然后一次性提交到redis服务器统一执行。(怎么打包呢,还是通过resp协议)
Redis的同步机制了解吗?
redis部署一般都是一主多从, 通过sentinel来实现高可用。主从之间的复制(或叫同步)分为全复制和增量复制。 Master和Slave之间只是有最终一致性,可以使用主从同步,从从同步。首先同步全量数据rdb同步,再将这期间的增量数据同步。
Sentinel主要有三个作用:监控:redis节点运行状态、提醒:出现问题时及时通知、自动故障迁移:若redis节点挂掉之后重新选举新的Master。
Redis集群原理了解吗?
Redis集群实际上和mysql的分库分表很像,由于Redis数据量大到一定程度以后,我们需要将Redis数据库扩展,将以前一个Redis的实例放到多个Redis实例上,但是这样就存在一个数据路由的问题。比如我存储的一个点赞数的缓存,有postId --> likeNum的对应关系,这时由于数据量太大我想将其拆分到多个redis实例上,这时我们用hash(postId) % 服务器数来确定某个id应该存放到哪个位置上。看似美好,但是在服务器数目变动的情况下,大量的数据的位置就不对了。这时候我们可以按2的次方进行扩展,即一开始用2台,然后用4台,8台...这样每次求模时只需要&(n - 1)即可,并且每次扩展大概50%的位置不需要变动。
但是我们还有更好地解法:一致性hash算法。即我们将某个hash函数所能够输出的值做一个圈,每个服务器的id或者序号通过hash后在该hash环上成为一个点,同时我们将postId同样hash后在环上也成为一个点,每个点顺时针去环上寻找离自己最近的服务器。
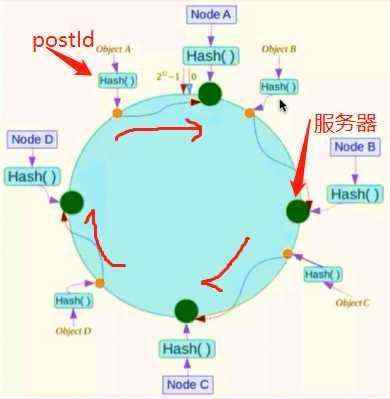
顺时针寻找就近服务器。当加入一个节点或者某个节点宕机时,其所影响的数据只有从变动服务器起,逆时针方向上到另一服务器这一段距离的数据。这样已经很不错了,但是当节点比较少时,可能会出现hash环的数据倾斜问题,即服务器的数据不均衡。
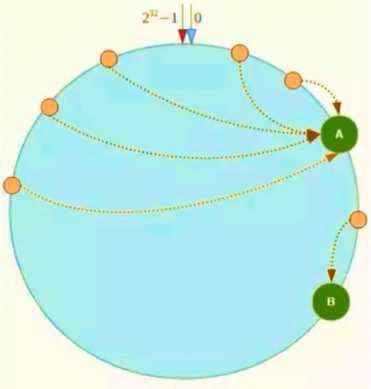
解决这个办法的一个手段是使用“虚拟节点”,即将A节点分为A#1,A#2,A#3,其实他们都对应A服务器,但是这样多个id进行hash后在环上的分布就更为均匀了。












 京公网安备 11010802041100号
京公网安备 11010802041100号