进程
一、基本概念
进程是系统资源分配的最小单位, 系统由一个个进程(程序)组成,一般情况下,包括文本区域(text region)、数据区域(data region)和堆栈(stack region)
因此进程的创建和销毁都是相对于系统资源,所以是一种比较昂贵的操作。 进程有三个状态:
进程的出现是为了更好的利用CPU资源,使得并发成为可能。现假设有A、B两个I/O任务并且CPU为单核,如果没有多进程的实现,CPU在执行时只能等待A任务读取-写入操作全部执行完毕后,才能去执行B任务,但因为是/O操作十分的耗时,这对于CPU来说是极大的浪费,所以多进程就是让CPU执行某个耗时任务时,切换到另一个任务执行,等待前一个任务耗时操作完成,再切换回来。注意,因为涉及到切换那么就需要有一个东西来记录当前这个进程的状态,比如进程运行时所需的系统资源:内存,硬盘,键盘等(地址空间,全局变量,文件描述符,各种硬件等等),所以进程的意义就在于通过进程来分配系统资源&标识任务。进程状态的记录、恢复、切换称之为上下文切换,但由于CPU执行速度飞快,因此使得看上去就像是多个进程在同时进行.
进程是系统进行资源分配和调度的一个独立单位,拥有自己独立的堆和栈,但既不共享堆,亦不共享栈,每个进程都是独立的,各自持有一份数据无法共享,所以为了能够让进程之间实现数据共享:
1.Queue是多进程中安全的队列,可以使用Queue实现多进程之间的数据传递。
其中put方法用于插入数据到队列中,有两个可选参数:blocked和timeout。如果blocked为True(默认值),并且timeout为正值,该方法会阻塞timeout指定的时间,直到该队列有剩余的空间。
如果超时,会抛出Queue.Full异常。如果blocked为False,但该Queue已满,会立即抛出Queue.Full异常
get方法可以从队列读取并且删除一个元素。同样,get方法有两个可选参数:blocked和timeout。如果blocked为True(默认值),并且timeout为正值,那么在等待时间内没有取到任何元素,
会抛出Queue.Empty异常。如果blocked为False,有两种情况存在,如果Queue有一个值可用,则立即返回该值,否则,如果队列为空,则立即抛出Queue.Empty异常
2.pp = multiprocessing.Pipe() Pipe方法返回(conn1, conn2)代表一个管道的两个端。
Pipe方法有duplex参数,如果duplex参数为True(默认值),那么这个管道是全双工模式,也就是说conn1和conn2均可收发。duplex为False,conn1只负责接受消息,conn2只负责发送消息
管道的两个端还有send方法负责发送消息,和recv方法负责接受消息。例如,在全双工模式下,可以调用conn1.send发送消息,conn1.recv接收消息。如果没有消息可接收,recv方法会一直阻塞。
如果管道已经被关闭,那么recv方法会抛出EOFError
三、进程池
目的:重复利用进程池中原先建立好的的进程,简化进程的创建、销毁、任务分配.使用完后的进程由进程池管理
地球语言:进程池是事先划分一块系统资源区域,这组资源区域在服务器启动时就已经创建和初始化,用户如果想创建新的进程,可以直接取得资源,从而避免了动态分配资源(这是很耗时的)。
进程池中的所有子进程都运行着相同的代码,并具有相同的属性,比如优先级、 PGID 等。当有新的任务来到时,主进程将通过某种方式选择进程池中的某一个子进程来为之服务。相比于动态创建子进程,选择一个已经存在的子进程的代价显得小得多。进程池内子进程的个数可通过maxsize参数指定。
。主进程选择子进程的两种方式:
当选择好子进程后,需要在主进程和子进程之间预先建立好一条管道,然后通过管道或者Queue队列来实现所有的进程间通信。注 : 进程池创建的进程 默认都是守护进程,只要主进程结束,子进程就结束。
提交进程池的方式有同步提交&异步提交,同步提交的方式必须是一个子进程执行完才会执行下一个,所以主进程是最后结束的,会等待进程池中所有进程结束; 但是异步方式(子进程同时执行)必须结合close&join使用,pool.close() 必须先关闭进程池,表示不允许再添加新的任务,再使用pool.join()表示等待进程池中所有进程结束,主进程再继续执行。
线程
一、基本概念
线程是程序执行最小单元。线程拥有自己独立的栈和共享的堆,共享堆,但不共享栈。一个进程内可以有多个线程(至少一个主线程),多个线程共享该进程的所有变量。
线程的出现是为了降低上下文切换的消耗,提高系统的并发性,解决一个进程只能执行一个任务的缺陷,使得进程内并发成为可能。假设,一个文本程序,需要接受键盘输入,将内容显示在屏幕上,还需要保存信息到硬盘中。但只有一个进程执行此任务,那么势必造成同一时间只能执行其中一个任务的局面(当保存时,就不能通过键盘输入内容)。如果使用多进程来实现的话:每个进程只负责其中一个任务,例如,进程A负责接收键盘输入的任务,进程B负责将内容显示在屏幕上的任务,进程C负责保存内容到硬盘中的任务。但此时进程A,B,C间的协作涉及到了进程通信问题,而且都有共同需要的东西 --- 文本内容,但进程之间原本是不支持数据共享的,即使可以通过队列实现数据共享,但不停的切换会造成性能上的损失,而且因为一个简单的任务而要额外的创建子进程,还得给它分配主进程所有的资源(诸如系统资源,地址空间,全局变量等),对于CPU来说太小题大做了。若有一种机制,可以使任务A,B,C共享资源,这样上下文切换所需要保存和恢复的内容就少了,同时又可以减少通信所带来的性能损耗,所以线程就是这种机制,线程共享进程的大部分资源,并参与CPU的调度, 当然线程自己也是拥有自己的资源的,例如,栈,寄存器等等。 此时进程同时也是线程的容器。但线程也有着自己的缺陷的,若一个线程挂掉了,一整个进程也挂掉了,这意味着其它线程也挂掉了,进程却没有这个问题,一个进程挂掉,另外的进程还是活着,因为进程之间都是拥有独立的资源,互不干扰的。
进程切换:
线程切换仅需第2、3步,因此进程的切换代价比较大,但相比进程不够稳定容易丢失数据。
class Mythread(threading.Thread):
2.自定义线程类中重写 run方法,再根据业务需求在run方法中添加逻辑代码。
def run(self):
3.通过 自定义线程类的实例化对象调用start() 方法,启动自定义线程
mythread.start()
注:使用实例化对象调用start方法,start会自动调用 run方法,若在创建实例对象需要进行传参,要重写 __init__ 方法,但是必须初始化父类的 __init__ 方法,不然无法调用自定义线程类中重写的 run方法
方法一:
def __init__(self, num):
super().__init__()
self.num = num
方法二:
def __init__(self, num):
super(当前类名, self).__init__()
self.num = num
解决机制:1.同步解决,按照顺序依次执行每个线程。先等待线程A执行完毕,再执行线程B。缺陷:原本能使用多个线程实现多任务操作,如此的话,多线程就没有存在的意义了,程序又变成了单任务。
2. 异步解决,互斥锁用于防止两条线程同时对同一公共资源(比如全局变量)进行读写的机制,通过将代码切片成一个一个的临界区域而达成的。
地球语言:当线程A对某个全局变量进行操作之前,将其上锁,此时就算CPU切换到线程B它也无法解锁无法操作,只有当线程A真正操作完毕解锁之后,线程B才能够执行它的操作
互斥锁底层:
互斥锁实质是一种变量,上锁解锁其实是给它置0、置1的操作。现假设mutex=1时表示锁是空闲的,如果此时某个线程调用acquire( )函数【上锁】就可以获得锁资源,并且mutex此时被置为0。
当mutex=0时表示锁正在被其他线程占用,如果此时有其他线程也调用acquire( )函数来获得锁时会被挂起等待。
流程:
mutex = threading.Lock # 创建互斥锁,默认锁是开启状态
mutex.acquire( ) # 上锁
mutex.release( ) # 解锁
互斥锁可能导致的死锁问题:
死锁:线程间共享多个资源的时候,如果两个线程分别占有?部分资源并且同时等待对?的资源,而处于的一种永久等待状态,就会造成死锁。
地球语言:假设A线程持有锁a,B线程持有锁b,而主线程访问临界区的条件是需要同时具有锁a和锁b,那么A就会等待B释放锁b,B会等待A释放锁a,如果没有一种措施,他两会一直等待,这样就产生了死锁。
如何产生的死锁:
1、系统资源不足:如果系统资源足够,每个申请锁的线程都能后获得锁,那么产生死锁的情况就会大大降低;
2、申请锁的顺序不当:当两个线程按照不同的顺序申请、释放锁资源时也会产生死锁。
死锁产生的条件:
1、互斥属性:即每次只能有一个线程占用资源。
2、请求与保持:即已经申请到锁资源的线程可以继续申请。在这种情况下,一个线程也可以产生死锁情况,即抱着锁找锁。
3、不可剥夺:线程已经得到锁资源,在没有自己主动释放之前,不能被强行剥夺。
4、循环等待:多个线程形成环路等待,每个线程都在等待相邻线程的锁资源。
死锁的避免:
1、既然死锁的产生是由于使用了锁,那么如果可以在不使用锁的情况下完成任务,就尽量不使用互斥锁机制。如果有多种方案都能实现,那么尽量不选用带锁的这种方案
2、尽量避免同时获得多把锁,如果有必要,就要保证获得锁的顺序相同。
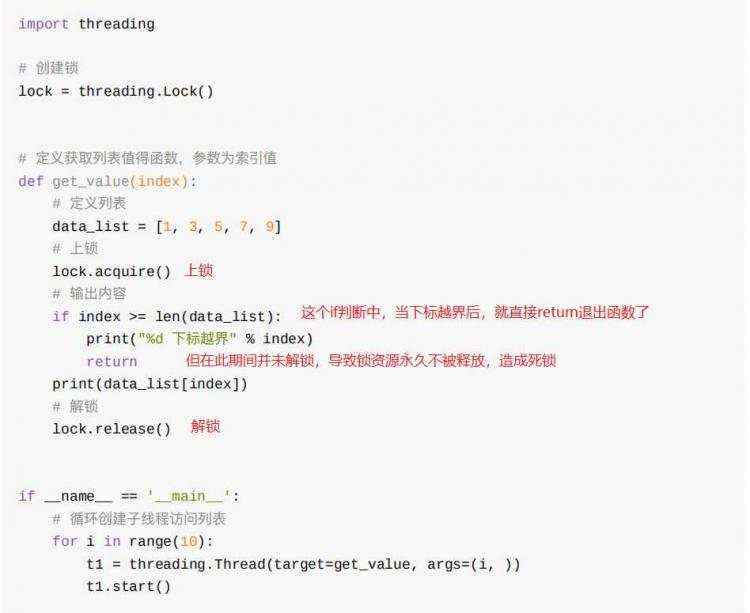
3、只有一把互斥锁存在时,尤其注意互斥锁使用完毕且代码即将终止前,必须解锁
4、尽量将越少的代码放入互斥锁中
四、GIL锁
GIL锁:Global Interpreter Lock 全局解释器锁,互斥锁保证的是线程间公共数据资源的安全。GIL也是一种特殊的互斥锁,它所约束的是多线程执行时在任何时刻仅有一个线程在执行:同一时间内只能有一个线程使用到CPU(伪并发),GIL锁的解释器有CPython与Ruby MRI。
任何Python线程执行前,必须先获得GIL锁,然后每执行100条字节码,解释器就自动释放GIL锁,让别的线程有机会执行。这个GIL全局锁实际上把所有线程的执行代码都给上了锁,所以多线程在Python中只能交替执行,即使100个线程跑在100核CPU上,也只能用到1个核。
地球语言:每个线程执行之前必须先获得GIL锁,当此线程开始执行后,在此期间别的线程无法使用CPU,只有等待当前上锁的线程执行完毕解锁后才会切换到下一个线程,所以此时就算有多个线程也只能交替执行,
并且也只能使用到一个核。 即:一个CPU只能执行一个线程 ,伪并发的多线程,一个解释器只有一把GIL锁
协程
一、基本概念
可以暂停执行的函数,协程通过在线程中实现调度,避免了陷入内核级别的上下文切换造成的性能损失,进而突破了线程在IO上的性能瓶颈。 当涉及到大规模的并发连接时,例如10K连接。以线程作为处理单元,系统调度的开销还是过大。在实现多任务时, 线程切换从系统层面远不止保存和恢复 CPU上下文这么简单。 操作系统为了程序运行的高效性,每个线程都有自己缓存Cache等等数据,操作系统还会帮你做这些数据的恢复操作。所以线程的切换非常耗性能。但是协程的切换只是单纯的操作CPU的上下文,所以?秒钟切换个上百万次系统都抗的住。
当连接数很多 —> 需要大量的线程来干活 —> 可能大部分的线程处于ready状态 —> 系统会不断地进行上下文切换。既然性能瓶颈在上下文切换,那干脆就在线程中自己实现调度,不陷入内核级别的上下文切换,协程切换只涉及到CPU的上下文,所以在线程内实现协程可大大提升性能。
- 协程属于线程。协程运行在线程里面,因此协程又称微线程和纤程等
- 协程没有线程的上下文切换消耗。协程的调度切换是用户(程序员)手动切换的,因此更加灵活,因此又叫用户空间线程.
- 原子操作性。由于协程是用户调度的,所以不会出现执行一半的代码片段被强制中断了,因此无需原子操作锁。
通俗的理解:在?个线程中的某个函数,可以在任何地方保存当前函数的?些临时变量等信息,然后切换到另外?个函数中执?,注意不是通过调用函数的方式做到的,并且切换的次数以及什么时候再切换到原来的函数都由开发者自己确定。
Python中,使用了yield的函数为生成器,生成器一次只返回一个数据,并且可以多次返回值。中途可以暂停一下,转而执行其他代码,再回来继续执行函数往下的代码。
可迭代对象:可通过 for ... in... 迭代读取数据的叫做可迭代对象
可迭代的类型 : Python中的字符串,元组,字典,列表,集合,range 。 不可迭代类型 : 数字类型,整型,浮点型,自定义的普通类。
可迭代对象本质 : 一个对象所属的类中 实现了__iter__方法,它的实例化对象就是一个可迭代对象,自定义可迭代对象时, 必须实现 __iter__ 方法, 其返回一个迭代器
迭代器: 实现可迭代对象进行遍历的工具,帮助可迭代对象记录当前的迭代位置,并返回下一个数据的结果。迭代器规定了对象可以通过next方法可以返回下一个值
而不是像列表一样所有数据一次性返回。
生成器: 是?类特殊的迭代器。Python中有两种创建生成器的方式
- 使用 yield 关键字的函数,可以多次返回值,生成器实际上也算是实现了迭代器接口(协议)。即生成器也可通过next返回下一个值。
- 把列表推导式的中括号换成小括号(存储的是生成列表的方式,不占空间,再通过for循环就可取出)
yield关键字:
- yield 关键字会返回跟在后面的结果
- 暂停程序,保存程序状态,直到下次调用next/send,再次回到上次暂停的位置
- 调用next()/send() , 得到生成器中yield返回的结果,并且程序继续运行。
- yield关键字需要一个变量来接收它后面的结果
注:第一次启动生成器时,最好使用next方法,若执意使用send,给定参数为None。生成器中使用return会终止生成器,并抛出异常。
三、协程的实现
只使用一个线程(单线程),在一个线程中规定某个代码块的执行顺序。 可理解为单线程上的多任务(可控制某个代码块的只需顺序)
协程 - yield : 创建两个生成器 , 在主程序中使用死循环切换执行两个任务
def work1()
print(“w1”)
yield
def work2
print(“w2”)
yield
w1 = worl1()
w2 = work2()
while True:
next(w1)
next(w2)
协程 - greenlent:
sudo pip3 install greenlet # 0.安装模块
from greenlet import greenlet # 1. 导入模块
gre1 = greenlet(work1) # 2. 创建协程
gre1.switch(*args, **kwargs) # 3. 启动协程
协程 - gevent
sudo pip3 install gevent # 0.安装模块
import gevent # 1. 导入模块
g1 = gevent.spawn(work1, args, kwds) # 2. 创建并运行
# 3. gevent会根据耗时操作自动切换
# 例如 : gevent.sleep()
# 4. 等待协程执行结束
g1.join()
# 需要打补丁:gevent默认不识别其余耗时操作 : read,recv,accept,sleep...
# 5. 导入模块
from gevent import monkey
# 6. 破解
monkey.patch_all()
# 7.获取当前协程的信息:
gevent.getcurrent() --> 返回一个greenlet对象
三者区别
应用场景:
进程:CPU密集型(使用多核)
线程:io密集型(网络io,文件io,数据库io)
协程:io密集型(网络io),非阻塞异步并发
多核CPU,CPU密集型应用:多进程
多核CPU,IO密集型应用:多线程 // 多协程
单核CPU,CPU密集型应用:单进程
单核CPU,IO密集型应用:多协程
性能比较:
消耗大小:进程>线程>协程
切换速度:协程>线程>进程
三者区别:
进程:资源分配的最小单位,是线程的容器。进程间数据不共享 ,每个进程各自有独立运行空间,杀死其中一个进程不会影响其他的进程 , 稳定安全,创建销毁切换耗时长。
一个程序至少一个进程,一个进程至少一个线程 ; 线程不能独立运行,必须依存于进程中。需充分使用多核性能的使用进程。 multiprocessing.Process
线程:CPU真正调度的单位,必须依赖于进程,线程之间共享进程的运行空间,共享数据资源,杀死其中一个线程死 ,可能会影响到别的线程 ,创建销毁切换耗时更短,稳定和安全差些(死锁)
互斥锁保证的是让当前的线程把事情做完再解锁给下一个线程 , GIL锁保证的是同一时间只能有一个线程在执行,但GIL不能保证这个线程全部执行完了再让cpu去调度下一个,可能线程1只执行了20%就被cpu切换到线程2 ,
所以就算有GIL锁也必1须同时存在互斥锁 . 互斥锁:逻辑上只有一个线程执行 , GIL:调度上只有一个线程执行。 threading.Thread
协程: 用户级,轻量级线程。用户控制,单线程中的多任务,创建销毁切换耗时最短。 yield、next、greenlet、switch、gevent、spwan
1、协程多与线程进行比较
2、协程多与线程进行比较
并行就是指同一时刻有两个或两个以上的“工作单位”在同时执行,从硬件的角度上来看就是同一时刻有两条或两条以上的指令处于执行阶段。所以,多核是并行的前提,单线程永远无法达到并行状态。可以利用多线程和度进程到达并行状态。另外的,Python的多线程由于GIL的存在,对于Python来说无法通过多线程到达并行状态。
对于并发的理解,要从两方面去理解,1.并发设计 2.并发执行。先说并发设计,当说一个程序是并发的,更多的是指这个程序采取了并发设计。
并发设计的标准:使多个操作可以在重叠的时间段内进行 ,这里的重点在于重叠的时间内, 重叠时间可以理解为一段时间内。例如:在时间1s秒内, 具有IO操作的task1和task2都完成,这就可以说是并发执行。所以呢,单线程也是可以做到并发运行的。当然啦,并行肯定是并发的。一个程序能否并发执行,取决于设计,也取决于部署方式。例如, 当给程序开一个线程(协程是不开的),它不可能是并发的,因为在重叠时间内根本就没有两个task在运行。当一个程序被设计成完成一个任务再去完成下一个任务的时候,即便部署是多线程多协程的也是无法达到并发运行的。
并行与并发的关系: 并发的设计使到并发执行成为可能,而并行是并发执行的其中一种模式。







 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有