作者:手机用户2502905845 | 来源:互联网 | 2024-11-30 11:27
前言:本篇文章旨在分享一个具体的SQL应用场景——当数据库中存在重复的记录时,如何高效地将其中某列的值更新为0.000。这对于数据清理和维护数据一致性具有重要意义。
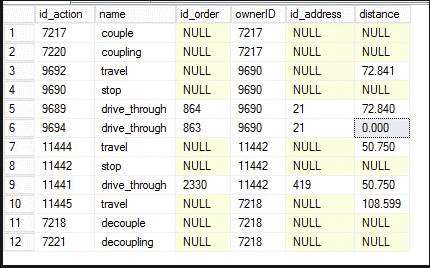
问题描述:我的目标是更新表中的‘距离’字段,首先根据每个ownerID累加距离,然后如果发现有相同ID地址的记录,第一个记录保留其距离值,而后续的记录则应将距离设为0.000。
期望结果如下图所示:
目前,我已经完成了距离的累加部分,使用的SQL语句如下:
UPDATE Action_Distance
SET [distance] = (SELECT SUM([distance])
FROM Action a2
WHERE [name] = 'travel' AND a2.ownerID = Action_Distance.ownerId)
WHERE [name] = 'drive_through'
然而,对于如何进一步处理重复记录以达到上述要求,我感到困惑。
解决方案
为了实现这一目标,我们可以利用SQL中的CASE表达式结合NOT EXISTS子查询来完成任务。具体来说,我们假设每行记录的id_action字段是唯一的,则可以构造如下的更新语句:
UPDATE Action_Distance A
SET [distance] = CASE
WHEN NOT EXISTS (SELECT 1
FROM Action_Distance B
WHERE B.[name] = 'drive_through'
AND a.ownerId = b.ownerId
AND a.id_action > b.id_action)
THEN (SELECT SUM([distance])
FROM Action a2
WHERE [name] = 'travel'
AND a2.ownerID = a.ownerId)
ELSE 0.000
END
WHERE [name] = 'drive_through'
这段代码首先检查是否存在比当前记录id_action值小但拥有相同ownerId的记录。如果没有找到这样的记录(即该记录是所有相同ownerId记录中的第一条),则更新其距离值;反之,则将其距离值设置为0.000。








 京公网安备 11010802041100号
京公网安备 11010802041100号