作者:mobiledu2502902041 | 来源:互联网 | 2023-10-11 15:53
篇首语:本文由编程笔记#小编为大家整理,主要介绍了Mybatis-04 懒加载&缓存&注解开发相关的知识,希望对你有一定的参考价值。
1.Mybatis延迟加载策略
1.1 什么是延迟加载(懒加载)?
简单的说,就是要用到数据时才加载,否则不加载。
好处:先单表查询,要用时才去关联查询,提高数据库性能。
坏处:大批量数据查询的时候,查询可能消耗时间,影响用户体验。
1.2 Mybatis的延迟加载
上一个文章说要,association、collection实现了一对一及一对多的映射,他们时具有延迟加载功能的。
一般一对一用立即加载,一对多用延迟加载。
1.2.1 使用assocation实现延迟加载
需求如:查询账户(Account)信息并且关联查询用户(User)信息。如果先查询账户(Account)信息即可满足要求,当我们需要查询用户(User)信息时再查询用(User)信息。把对用户(User)信息的按需去查询就是延迟加载。
1.映射文件的配置
在association标签添加select属性,指定查找的方法唯一表示。
column属性,传递的参数
2.主配置文件的配置
1.2.2 使用collection实现延迟加载
结点中也有select属性,column属性。
和上类似:
1.配置主配置文件
2.配置映射文件
2.Mybatis缓存
2.1 一级缓存
一级缓存时sqlSession级别的缓存,只要sqlSession没有flush或close,就存在。

可以发现,查询了2次,但最后一次执行并没有向数据库查询,这就是一级缓存的作用了,而是从一级缓存中查询。
2.1.1 一级缓存分析
1. 是SqlSession范围的缓存,当条用了SqlSession的修改,添加,删除,commit(),close()等方法,缓存就会清空。
很好理解,是为了防止数据库的数据和缓存的数据不一致。
流程,如查询id为1的用户信息,先去缓存查找id为1的信息,如果有就读取,如果没有,从数据库中查询,得到用户信息,存入缓存。
如果sqlSession去执行了commit操作(增删改),清空一级缓存,避免脏读。
PS: sqlSession.clearCache();这个方法也可清除缓存。
2.2 二级缓存
二级缓存是mapper映射级别的缓存,多个sqlSession去操作同一个Mapper映射的sql语句,多个sqlSession共用二级缓存,是跨越sqlSession的。
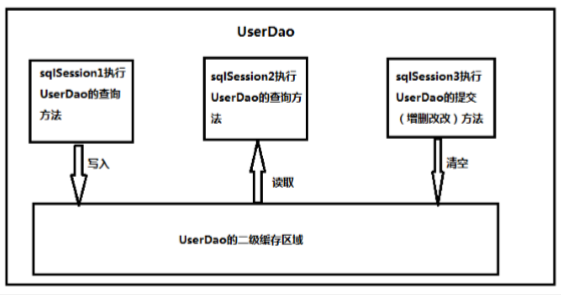
2.2.1 流程分析
sqlSession1查询信息,存入二级缓存。
sqlSession2如果执行相同mapper映射下的sql,执行commit,会清空缓存。
sqlSession2如果查询sqlSession1相同的信息,会看缓存是否存在数据,有就从缓存中去数据。
2.2.2 二级缓存的使用
1. 在全局配置文件开启二级缓存 默认值为true 这一步可省略不写

2. 相关的映射文件
标签表示当前这个mapper映射将使用二级缓存,区分的标准就看 mapper的namespace值。
3. 添加useCache属性
将UserDao.xml映射文件中的
2.2.3 注意事项
使用二级缓存的实体类一定要实现 java.io.Serializable 接口。
3.Mybatis注解开发
3.1 常用注解
@Insert 新增
@Update 更新
@Delete 删除
@Select 查询
@Result 封装结果集
@Results 和@Result一起使用,封装多个结果集
@ResultMap 引用封装
@One 一对一结果集封装
@Many 一对多结果集封装
@SelectProvider 动态SQL映射
@CacheNamespace 二级缓存使用
3.2 注解
SqlMapConfig.xml还是用xml配置的。
或者用package标签..
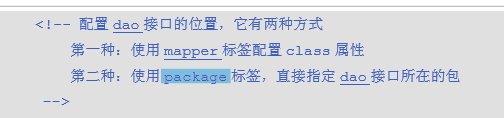
xml和注解的mapper属性不一样,如下:

在接口中配置使用@Insert 新增 @Update 更新 @Delete 删除 @Select 查询配置相应的方法。
属性里面写sql语句。
如 @Select("select * from user")
注意:如果使用注解开发,就不能有对应的xml配置文件,不管mapper中用的是class还是什么,否则就会报错。
3.2.1 注解建立实体类和数据库表的对应关系即 ResultMap

@Results 注解: 代替的是
使用:Results({@Result(),@Result()})
@Result 注解:
带起的是 中的和标签
id是否是主键字段
column 数据库的列名
property 需要装配的属性名
one 需要使用的@One注解
select 指定用来查询的sqlmapper:使用的全限定类名,包类名+方法名
fetchType 会覆盖全局的配置参数lazyLoadingEnabled
使用格式:@Result(column="",property="",One=@One(select="" ))
many 需要使用的@Many注解
@One注解:(一对一)
代替的是标签,是多表查询的关键,在注解中用来指定子查询返回单一对象。
@Many注解:(多对一)
代替了标签,在注解中用来指定子查询返回的对象集合。
注解:聚集元素用来处理一对多的关系,需要指定映射的java实体类属性,属性的JavaType(一般为ArrayList)但注解中可以不定义。
格式:@Result(property="",column="",many=@Many(select=""))
案例:


注解的关系如下:


3.3 注解开启缓存
在接口上使用@CacheNamespace注解就可以了
有一个blocking属性,改为true








 京公网安备 11010802041100号
京公网安备 11010802041100号