作者:再度重相逢jc_866 | 来源:互联网 | 2023-06-29 17:38
本文由编程笔记#小编为大家整理,主要介绍了Lucene学习总结相关的知识,希望对你有一定的参考价值。
Lucene是什么?
Lucene在维基百科的定义
Lucene是一套用于全文检索和搜索的开放源代码程序库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程序接口,能够做全文索引和搜索,在Java开发环境里Lucene是一个成熟的免费开放源代码工具;就其本身而论,Lucene是现在并且是这几年,最受欢迎的免费Java信息检索程序库。
Lucene和solr
我想提到Lucene,不得不提solr了。
很多刚接触Lucene和Solr的人都会问这个明显的问题:我应该使用Lucene还是Solr?
答案很简单:如果你问自己这个问题,在99%的情况下,你想使用的是Solr. 形象的来说Solr和Lucene之间关系的方式是汽车及其引擎。 你不能驾驶一台发动机,但可以开一辆汽车。 同样,Lucene是一个程序化库,您不能按原样使用,而Solr是一个完整的应用程序,您可以立即使用它。
全文检索是什么?
全文检索在百度百科的定义
全文数据库是全文检索系统的主要构成部分。所谓全文数据库是将一个完整的信息源的全部内容转化为计算机可以识别、处理的信息单元而形成的数据集合。全文数据库不仅存储了信息,而且还有对全文数据进行词、字、段落等更深层次的编辑、加工的功能,而且所有全文数据库无一不是海量信息数据库。
全文检索首先将要查询的目标文档中的词提取出来,组成索引,通过查询索引达到搜索目标文档的目的。这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。
全文检索(Full-Text Retrieval)是指以文本作为检索对象,找出含有指定词汇的文本。
全面、准确和快速是衡量全文检索系统的关键指标。
关于全文检索,我们要知道:
只处理文本。
不处理语义。
搜索时英文不区分大小写。
结果列表有相关度排序。
(查出的结果如果没有相关度排序,那么系统不知道我想要的结果在哪一页。我们在使用百度搜索时,一般不需要翻页,为什么?因为百度做了相关度排序:为每一条结果打一个分数,这条结果越符合搜索条件,得分就越高,叫做相关度得分,结果列表会按照这个分数由高到低排列,所以第1页的结果就是我们最想要的结果。) 在信息检索工具中,全文检索是最具通用性和实用性的。
全文检索和数据库搜索的区别
简单来说,这两者解决的问题是不一样。数据库搜索在匹配效果、速度、效率等方面都逊色于全文检索。
Lucene实现全文检索流程是什么?
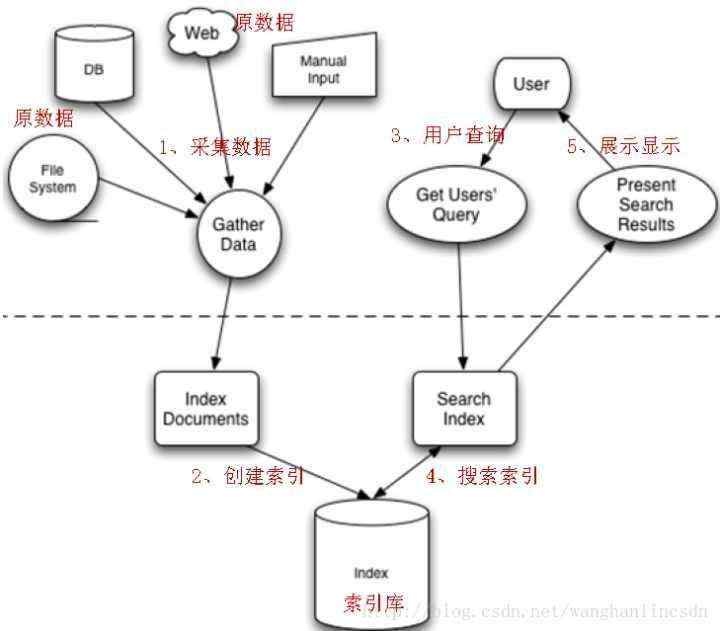
全文检索的流程分为两大部分:索引流程、搜索流程。
索引流程:即采集数据构建文档对象分析文档(分词)创建索引。
搜索流程:即用户通过搜索界面创建查询执行搜索,搜索器从索引库搜索渲染搜索结果
简单案例
1.Lucene实现向文档写索引并读取文档
org.apache.lucene
lucene-core
7.2.1
org.apache.lucene
lucene-queryparser
7.2.1
org.apache.lucene
lucene-analyzers-common
7.2.1
package com.xiaobai.lucene;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.nio.file.Paths;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
/**
*
*TODO 索引文件
* @author Snaiclimb
* @date 2018年3月30日
* @version 1.8
*/
public class Indexer {
// 写索引实例
private IndexWriter writer;
/**
* 构造方法 实例化IndexWriter
*
* @param indexDir
* @throws IOException
*/
public Indexer(String indexDir) throws IOException {
//得到索引所在目录的路径
Directory directory = FSDirectory.open(Paths.get(indexDir));
// 标准分词器
Analyzer analyzer = new StandardAnalyzer();
//保存用于创建IndexWriter的所有配置。
IndexWriterConfig iwCOnfig= new IndexWriterConfig(analyzer);
//实例化IndexWriter
writer = new IndexWriter(directory, iwConfig);
}
/**
* 关闭写索引
*
* @throws Exception
* @return 索引了多少个文件
*/
public void close() throws IOException {
writer.close();
}
public int index(String dataDir) throws Exception {
File[] files = new File(dataDir).listFiles();
for (File file : files) {
//索引指定文件
indexFile(file);
}
//返回索引了多少个文件
return writer.numDocs();
}
/**
* 索引指定文件
*
* @param f
*/
private void indexFile(File f) throws Exception {
//输出索引文件的路径
System.out.println("索引文件:" + f.getCanonicalPath());
//获取文档,文档里再设置每个字段
Document doc = getDocument(f);
//开始写入,就是把文档写进了索引文件里去了;
writer.addDocument(doc);
}
/**
* 获取文档,文档里再设置每个字段
*
* @param f
* @return document
*/
private Document getDocument(File f) throws Exception {
Document doc = new Document();
//把设置好的索引加到Document里,以便在确定被索引文档
doc.add(new TextField("contents", new FileReader(f)));
//Field.Store.YES:把文件名存索引文件里,为NO就说明不需要加到索引文件里去
doc.add(new TextField("fileName", f.getName(), Field.Store.YES));
//把完整路径存在索引文件里
doc.add(new TextField("fullPath", f.getCanonicalPath(), Field.Store.YES));
return doc;
}
public static void main(String[] args) {
//索引指定的文档路径
String indexDir = "D:\\lucene\\dataindex";
////被索引数据的路径
String dataDir = "D:\\lucene\\data";
Indexer indexer = null;
int numIndexed = 0;
//索引开始时间
long start = System.currentTimeMillis();
try {
indexer = new Indexer(indexDir);
numIndexed = indexer.index(dataDir);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
try {
indexer.close();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
//索引结束时间
long end = System.currentTimeMillis();
System.out.println("索引:" + numIndexed + " 个文件 花费了" + (end - start) + " 毫秒");
}
}
运行结果:

索引目录多出的文件:
2.根据索引搜索
package com.xiaobai.lucene;
import java.nio.file.Paths;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
/**
* 根据索引搜索
*TODO
* @author Snaiclimb
* @date 2018年3月25日
* @version 1.8
*/
public class Searcher {
public static void search(String indexDir, String q) throws Exception {
// 得到读取索引文件的路径
Directory dir = FSDirectory.open(Paths.get(indexDir));
// 通过dir得到的路径下的所有的文件
IndexReader reader = DirectoryReader.open(dir);
// 建立索引查询器
IndexSearcher is = new IndexSearcher(reader);
// 实例化分析器
Analyzer analyzer = new StandardAnalyzer();
// 建立查询解析器
/**
* 第一个参数是要查询的字段; 第二个参数是分析器Analyzer
*/
QueryParser parser = new QueryParser("contents", analyzer);//带分词器的查询解析
// 根据传进来的p查找
Query query = parser.parse(q);//这里进行了分词,Spring Cloud被分成Spring和Cloud两个词
// 计算索引开始时间
long start = System.currentTimeMillis();
// 开始查询
/**
* 第一个参数是通过传过来的参数来查找得到的query; 第二个参数是要出查询的行数
*/
TopDocs hits = is.search(query, 10);//将分词后的关键字封装为查询条件,从索引库查询
// 计算索引结束时间
long end = System.currentTimeMillis();
System.out.println("匹配 " + q + " ,总共花费" + (end - start) + "毫秒" + "查询到" + hits.totalHits + "个记录");
// 遍历hits.scoreDocs,得到scoreDoc
/**
* ScoreDoc:得分文档,即得到文档 scoreDocs:代表的是topDocs这个文档数组
*
* @throws Exception
*/
for (ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = is.doc(scoreDoc.doc);
System.out.println(doc.get("fullPath"));
}
// 关闭reader
reader.close();
}
public static void main(String[] args) {
String indexDir = "D:\\lucene\\dataindex";
//我们要搜索的内容
String q = "Spring Cloud";//目前这个分词器,无法搜索中文内容,或缺少中文分词器jar包和其他中文编码支持
try {
search(indexDir, q);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
执行结果:

Lucene全文检索组件分析
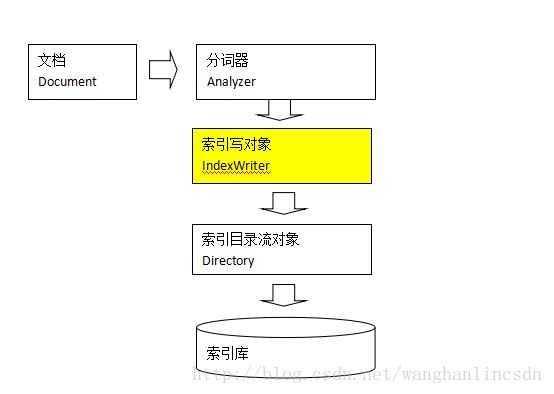
在Lucene中,采集数据(从网站爬取或连接数据库)就是为了创建索引,创建索引需要先将采集的原始数据加工为文档,再由文档分词产生索引。文档(Document) 中包含若干个Field域。
IndexWriter是索引过程的核心组件,通过IndexWriter可以创建新索引、更新索引、删除索引操作。IndexWriter需要通过Directory对索引进行存储操作。
Directory描述了索引的存储位置,底层封装了I/O操作,负责对索引进行存储。它是一个抽象类,它的子类常用的包括FSDirectory(在文件系统存储索引)、RAMDirectory(在内存存储索引)。
在对Docuemnt中的内容索引之前需要使用分词器进行分词 ,分词的主要过程就是分词、过滤两步。 分词就是将采集到的文档内容切分成一个一个的词,具体应该说是将Document中Field的value值切分成一个一个的词。
过滤包括去除标点符号、去除停用词(的、是、a、an、the等)、大写转小写、词的形还原(复数形式转成单数形参、过去式转成现在式等)。
停用词是为节省存储空间和提高搜索效率,搜索引擎在索引页面或处理搜索请求时会自动忽略某些字或词,这些字或词即被称为Stop Words(停用词)。比如语气助词、副词、介词、连接词等,通常自身并无明确的意义,只有将其放入一个完整的句子中才有一定作用,如常见的“的”、“在”、“是”、“啊”等。
Lucene中自带了StandardAnalyzer,它可以对英文进行分词。







 京公网安备 11010802041100号
京公网安备 11010802041100号