1>./bin/zkServer.sh start 2 3>./bin/zkServer.sh status
先启动,系统会默认加载zoo.cfg配置,然后使用 zkServer.sh status 查看服务状态
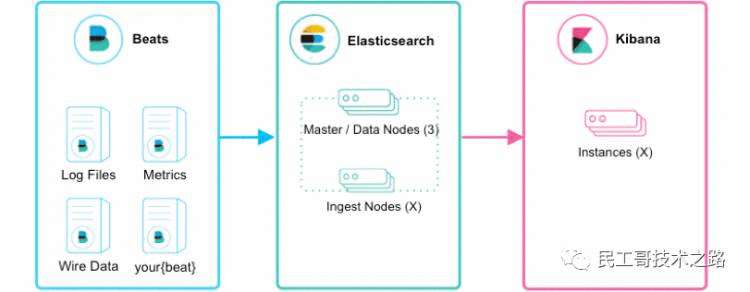
kafka安装配置:
根据官网教程开始安装(复制的官网教程):
Step 1: Download the code
1 > wget http://mirror.apache-kr.org/kafka/2.1.0/kafka_2.11-2.1.0.tgz 2 > tar -xzf kafka_2.11-2.1.0.tgz 3 > cd kafka_2.11-2.1.0/
Step 2: Start the server
Kafka uses ZooKeeper so you need to first start a ZooKeeper server if you don‘t already have one. You can use the convenience script packaged with kafka to get a quick-and-dirty single-node ZooKeeper instance.(由于我自己安装的Zookeeper,所以这一步可以省略)
Alternatively, instead of manually creating topics you can also configure your brokers to auto-create topics when a non-existent topic is published to.
1 [email protected]:~$ cd /home/tools/elk/elasticsearch-6.5.4/ 2 [email protected]:/home/tools/elk/elasticsearch-6.5.4$ vim config/elasticsearch.yml




























 京公网安备 11010802041100号
京公网安备 11010802041100号