RDD 持久化
在实际开发中某些RDD的计算或转换可能会比较耗费时间,如果这些RDD后续还会频繁的被使用到,那么可以将这些RDD进行持久化/缓存,这样下次再使用到的时候就不用再重新计算了,提高了程序运行的效率。
将RDD数据进行缓存时,本质上就是将RDD各个分区数据进行缓存
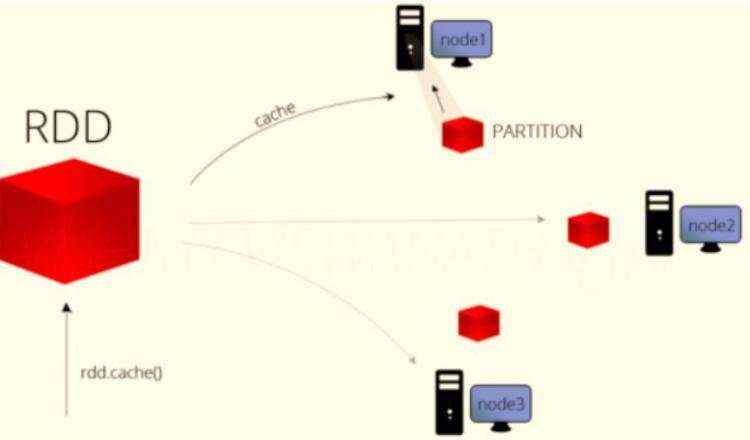
缓存函数
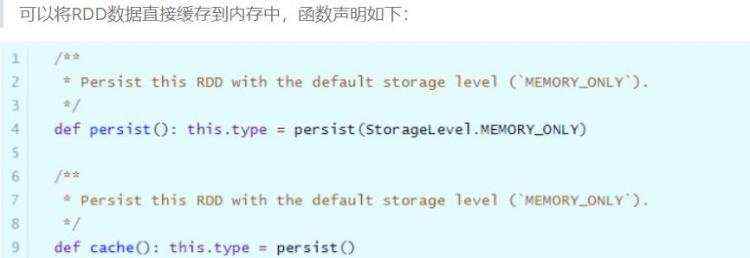
但是实际项目中,不会直接使用上述的缓存函数,RDD数据量往往很多,内存放不下的。在实际的项目中缓存RDD数据时,往往使用如下函数,依据具体的业务和数据量,指定缓存的级别:

在Spark框架中对数据缓存可以指定不同的级别,对于开发来说至关重要,如下所示:
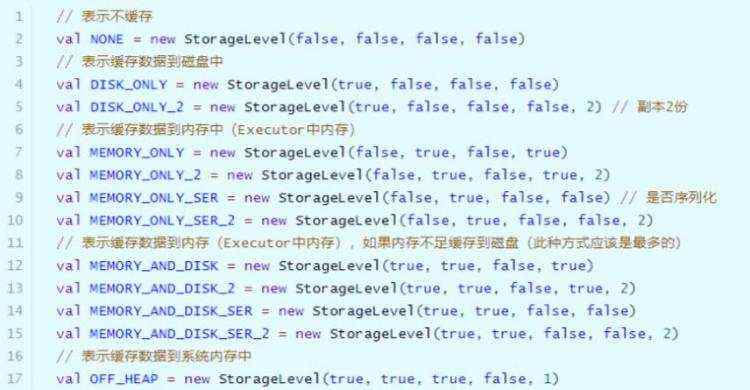
际项目中缓存数据时,往往选择如下两种级别:

缓存函数与Transformation函数一样,都是Lazy操作,需要Action函数触发,通常使用count函数触发。

缓存的RDD数据,不再被使用时,考虑释资源,使用如下函数:

此函数属于eager,立即执行。
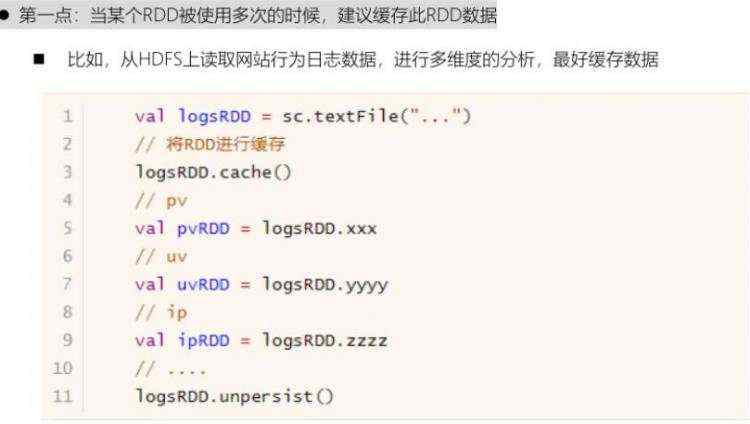
在实际项目开发中,什么时候缓存RDD数据,最好呢???









 京公网安备 11010802041100号
京公网安备 11010802041100号