作者:蓝瑟 | 来源:互联网 | 2023-07-31 06:57
篇首语:本文由编程笔记#小编为大家整理,主要介绍了#yyds干货盘点#数据分析从零开始实战,PythonPandas与各类数据库相关的知识,希望对你有一定的参考价值。
篇首语:本文由编程笔记#小编为大家整理,主要介绍了#yyds干货盘点#数据分析从零开始实战,PythonPandas与各类数据库相关的知识,希望对你有一定的参考价值。
这是我参与11月更文挑战的第18天。
零、写在前面
本系列学习笔记参考书籍: 《数据分析实战》托马兹·卓巴斯,会将自己学习本书的笔记分享给大家,同样开成一个系列『数据分析从零开始实战』。
点击查看第一篇文章: # 数据分析从零开始实战,Pandas读写CSV数据
点击查看第二篇文章: # 数据分析从零开始实战,Pandas读写TSV/Json数据
点击查看第三篇文章: # 数据分析从零开始实战,Pandas读写Excel/XML数据
点击查看第四篇文章: # 数据分析从零开始实战,Pandas读取HTML页面+数据处理解析
前面四篇文章讲了数据分析虚拟环境创建和pandas读写CSV、TSV、JSON、Excel、XML格式的数据,html页面读取,今天我们继续探索pandas。
一、基本知识概要
- SQLAlchemy模块安装
- 数据库PostgreSQL下载安装
- PostgreSQL基本介绍使用
- Pandas+SQLAlchemy将数据导入PostgreSQL
- Python与各种数据库的交互代码实现
二、开始动手动脑
1、SQLAlchemy模块安装
安装SQLAlchemy模块(下面操作都是在虚拟环境下): 方法一:直接pip安装(最简单,安装慢,可能出错)
pip install SQLAlchemy
方法二:轮子(wheel)安装(比较简单,安装速度还可以,基本不出错) 点击这里下载SQLAlchemy的.whl文件,然后移动到你的开发环境目录下。
pip install xxxxx.whl
方法三:豆瓣源安装(比较简单,安装速度快,方便,推荐)
pip install -i https://pypi.douban.com/simple/ SQLAlchemy

2、数据库PostgreSQL下载安装
(1) 下载地址:https://www.enterprisedb.com/software-downloads-postgres

(2) 下载完成后,点击安装文件,基本上就是Next。

First ,安装目录,建议自己选择,不要安装在C盘。
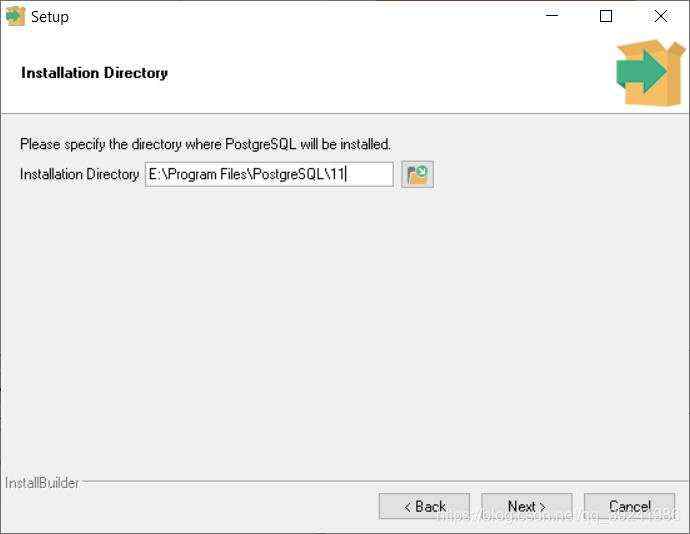
Second ,Password,可以设置简单点,毕竟只是用来自己学习。
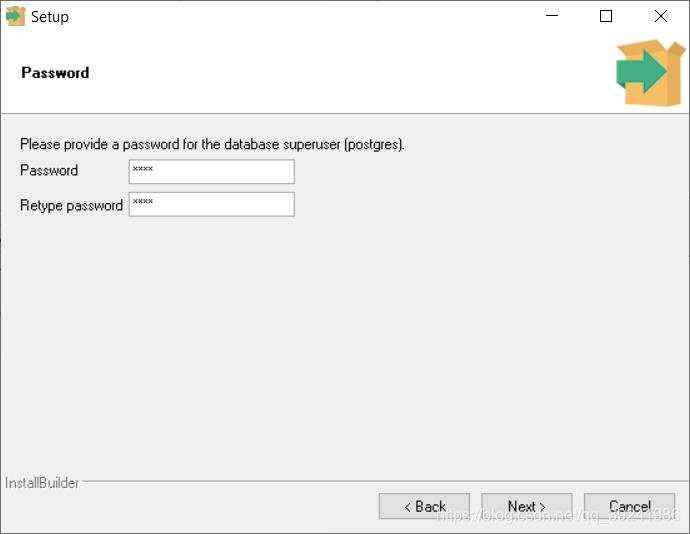
Third ,端口号,建议不要改,就用5432,改了容易和其他端口冲突,到时候自己又不知道怎么解决,麻烦。
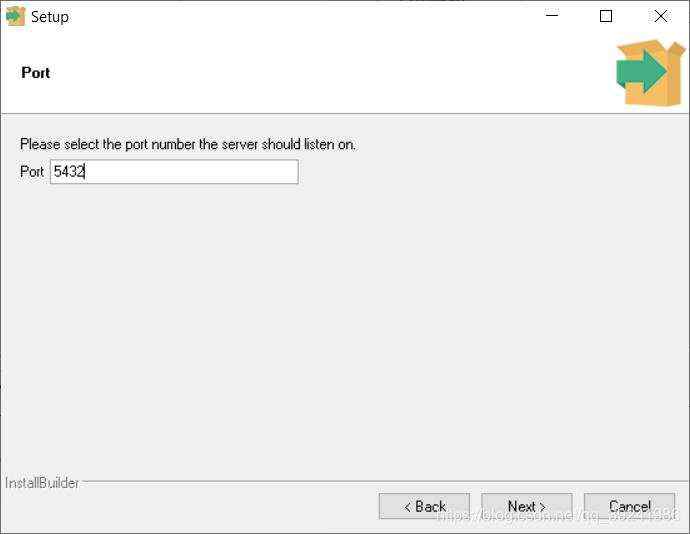
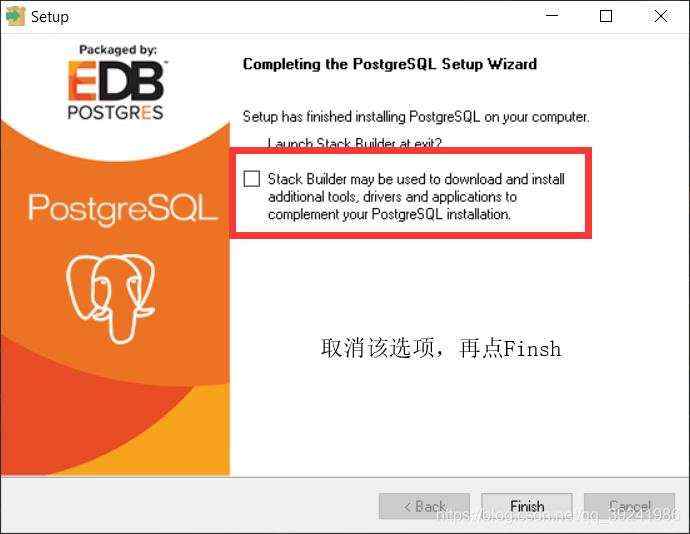
其他没有说到的就默认设置,Next,Next,Next~安装过程一般10分钟左右,不要急。 Finally ,安装完成后,取消图上的选项框,图上的意思是在后台启动Stack Builder(堆栈生成器),没有必要。
最后推荐几个相关学习网站 Postgre 社区:https://www.postgresql.org/community/ Postgre官方文档: https://www.postgresql.org/docs/ 易百 Postgre 学习教程:https://www.yiibai.com/postgresql
3、PostgreSQL基本介绍使用
(1) PostgreSQL特点


以上内容截取自 易百 Postgre 学习教程。 (2) 利用PostgreSQL创建一个数据库 a .打开pgADmin4,发现这个图形化操作界面是一个Web端的,先会要求输入Password,就是安装时候设置的Password。 点击Servers->PostgreSQL 11->Databases->右键->Create->Database。
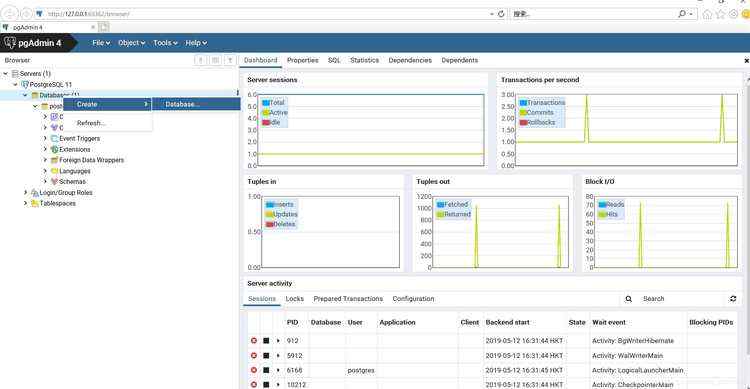
b .输入数据库名称,其他默认,注释自己随便写,我写的first database,表示我的第一个数据库。
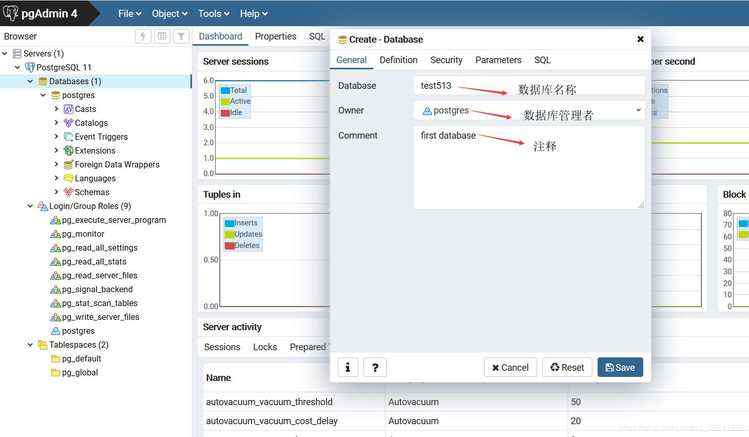
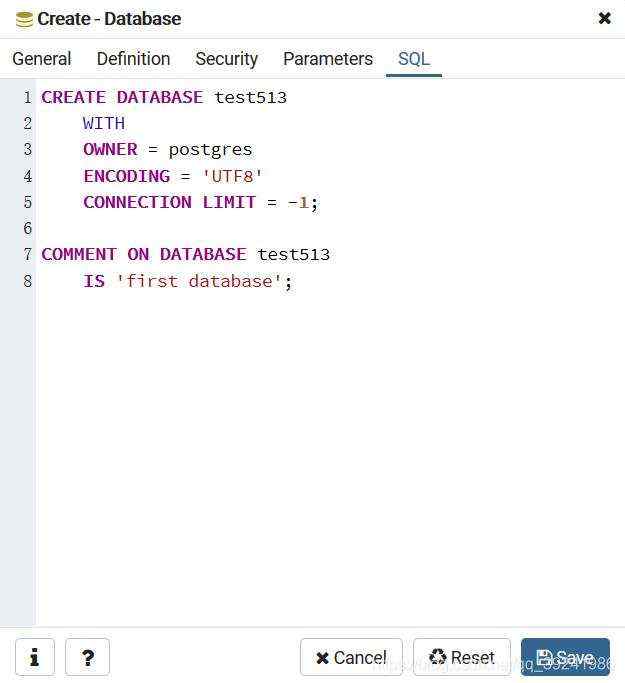
我们还可以看一下数据库创建的语句,点击弹框中的SQL即可。
4、Pandas+SQLAlchemy将数据导入Postgre
(1) Python操作代码
import pandas as pd
import sqlalchemy as sa
r_filepath = r"H:\\PyCoding\\Data_analysis\\day01\\data01\\realEstate_trans.csv"
user = "postgres"
password = "root"
db_name = "test513"
engine = sa.create_engine(postgresql://{0}:{1}@localhost:5432/{2}.format(user, password, db_name))
print(engine)
csv_read = pd.read_csv(r_filepath)
csv_read[sale_date] = pd.to_datetime(csv_read[sale_date])
csv_read.to_sql(real_estate, engine, if_exists=replace)
print("完成")
(2) 代码解析
engine = sa.create_engine(postgresql://{0}:{1}@localhost:5432/{2}.format(user, password, db_name))
sqlalchemy的create_engine函数,创建一个数据库连接,参数为一个字符串,字符串的格式是:
://:@:/
数据库类型://数据库用户名:数据库password@服务器IP(如:127.0.0.1)或者服务器的名称(如:localhost):端口号/数据库名称
其中可以是:postgresql,mysql等。
csv_read.to_sql(real_estate, engine, if_exists=replace)
pandas的to_sql函数,将数据(csv_read中的)直接存入postgresql,第一个参数指定了存储到数据库后的表名,第二个参数指定了数据库引擎,第三个参数表示,如果表real_estate已经存在,则替换掉。 (3) 运行结果
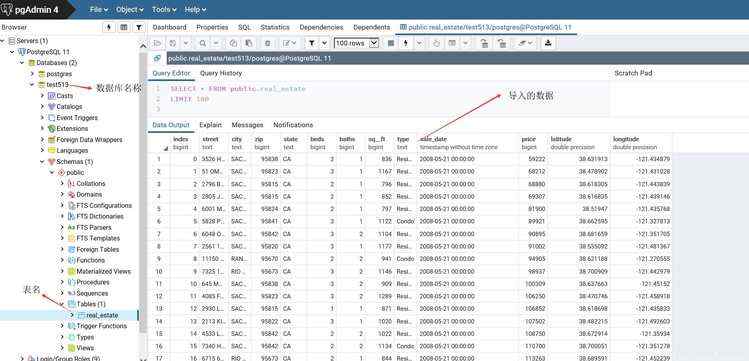
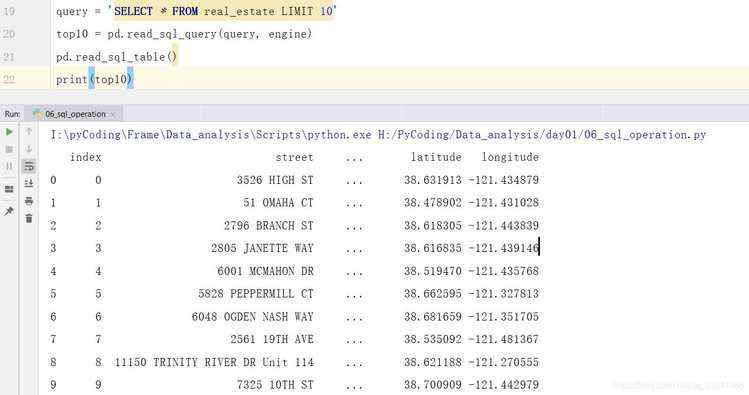
此外,pandas库还提供了数据库查询操作函数read_sql_query,只需传入查询语句和数据库连接引擎即可,源码注释为Read SQL query into a DataFrame.,意思是:把数据库查询的内容变成一个DataFrame对象返回。
query = SELECT * FROM real_estate LIMIT 10
top10 = pd.read_sql_query(query, engine)
print(top10)
5、Python与各个数据库的交互代码
a . Python 与 MySql
import pymysql
db = pymysql.connect("localhost","root","root","db_test")
cursor = db.cursor()
cursor.execute("SELECT * FROM test_table")
data = cursor.fetchall()
cursor.close()
db.close()
b . Python 与 MongoDB
import pymongo
my_client = pymongo.MongoClient(host="127.0.0.1",port=27017)
my_db = my_client["db_name"]
my_collection = my_client["collection_name"]
datas = my_collection.find()
for x in datas :
print(x)
c . Python 与 Sqlite
sqlite数据库和前面两种数据库不一样,它是一个本地数据库
也就是说数据直接存在本地,不依赖服务器
import sqlite3
conn = sqlite3.connect(test.db)
c = conn.cursor()
cursor = c.execute("SELECT * from test_table")
for row in cursor:
print(row)
c.close()
conn.close()
三、送你的话
坚持 and 努力 : 终有所获。
思想很复杂,
实现很有趣,
只要不放弃,
终有成名日。
—《老表打油诗》
下期见,我是爱猫爱技术的老表,如果觉得本文对你学习有所帮助,欢迎点赞、评论、关注我!







 京公网安备 11010802041100号
京公网安备 11010802041100号