作者:桦7231227 | 来源:互联网 | 2023-07-29 09:52
篇首语:本文由编程笔记#小编为大家整理,主要介绍了[lucene系列笔记2]在eclipse里初步使用lucene的索引和查询功能相关的知识,希望对你有一定的参考价值。
篇首语:本文由编程笔记#小编为大家整理,主要介绍了[lucene系列笔记2]在eclipse里初步使用lucene的索引和查询功能相关的知识,希望对你有一定的参考价值。
首先,new一个java project,名字叫做LuceneTools。
然后,在project里new一个class,名字叫做IndexFiles。这个类用来给文件建索引(建好索引以后就可以高效检索了)。
在写代码之前,我们要先引入一下lucene包,就类似于C语言里的include。如图:
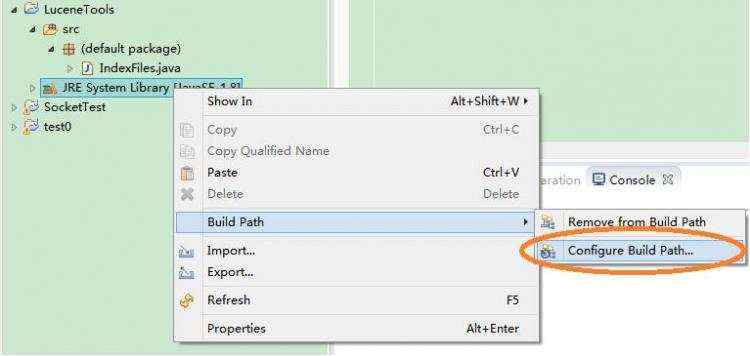
点击之后看到如下窗口,选择“Add External JARs”
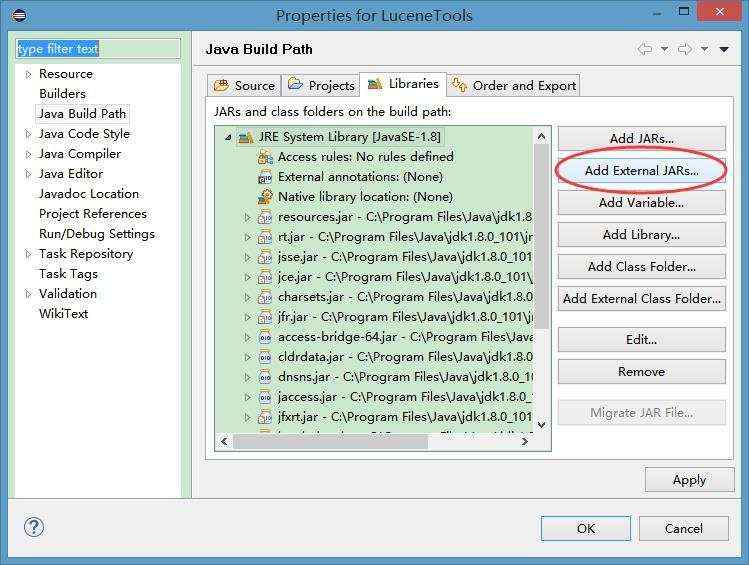
然后找到C:\\Lucene-6.2.1目录下(如果是按上一篇文章配置的话应该是在这个目录里)的三个包(这里我们暂时只用到这三个包)引入工程里。之后工程大概是这个模样:
对于中文来说analyzer用smartcn那一个更好,就是除了导入analyzers-common,再导入一个analyzers-smartcn,然后代码里的StandardAnalyzer()都换成SmartChineseAnalyzer()就可以了。

下面我们就可以来写代码了。
打开IndexFiles.java文件,这里我们假设要对D:\\lucenetest\\files文件夹建立索引,而且,而且我们假设这个目录下只有文件而没有文件夹(为了让代码更简单),然后建立好的索引保存在D:\\lucenetest\\index目录下。
那么我们写入如下代码:
import java.nio.charset.StandardCharsets;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.io.*;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
/**
* @author song
* @description:
* 依赖jar:Lucene-core,lucene-analyzers-common,lucene-queryparser
* 作用:简单的索引建立
*/
public class IndexFiles {
public static Version luceneVersion = Version.LATEST;
/**
* 建立索引
*/
public static void createIndex(){
IndexWriter writer = null;
try{
//1、创建Directory
//Directory directory = new RAMDirectory();//创建内存directory
Directory directory = FSDirectory.open(Paths.get("D:/lucenetest/index"));//在硬盘上生成Directory00
//2、创建IndexWriter
IndexWriterConfig iwCOnfig= new IndexWriterConfig( new StandardAnalyzer());
writer = new IndexWriter(directory, iwConfig);
//3、创建document对象
Document document = null;
//4、为document添加field对象
File f = new File("D:/lucenetest/files");//索引源文件位置
for (File file:f.listFiles()){
document = new Document();
document.add(new StringField("path", f.getName(),Field.Store.YES));
System.out.println(file.getName());
document.add(new StringField("name", file.getName(),Field.Store.YES));
InputStream stream = Files.newInputStream(Paths.get(file.toString()));
document.add(new TextField("content", new BufferedReader(new InputStreamReader(stream, StandardCharsets.UTF_8))));//textField内容会进行分词
//document.add(new TextField("content", new FileReader(file))); 如果不用utf-8编码的话直接用这个就可以了
writer.addDocument(document);
}
}catch(Exception e){
e.printStackTrace();
}finally{
//6、使用完成后需要将writer进行关闭
try {
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws IOException
{
createIndex();
}
}
在运行之前我们先在D:\\lucenetest\\files文件夹下创建几个txt,比如第一个文件命名为hello.txt,第二个文件命名为test.txt。然后在里面随便写点什么内容。这里要注意的是,上面的代码是针对中文搜索的问题使用了utf-8编码,所以要求文件也是utf-8的编码。如图:
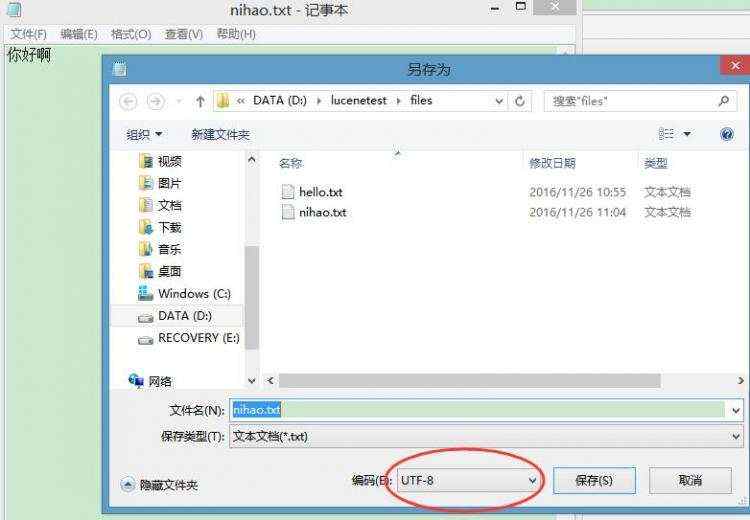
然后运行IndexFiles.java。会看到索引建立完成。D:\\lucenetest目录下多了一个index文件夹。
下面我们就要用这个index来检索了。
new一个class,命名为SearchFiles。然后在里面写入如下代码:
import java.nio.file.Paths;
import java.io.*;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
/**
* @author song
* @description:
* 依赖jar:Lucene-core,lucene-analyzers-common,lucene-queryparser
* 作用:使用索引搜索文件
*/
public class SearchFiles {
public static Version luceneVersion = Version.LATEST;
/**
* 查询内容
*/
public static String indexSearch(String keywords){
String res = "";
DirectoryReader reader = null;
try{
// 1、创建Directory
Directory directory = FSDirectory.open(Paths.get("D:/lucenetest/index"));//在硬盘上生成Directory
// 2、创建IndexReader
reader = DirectoryReader.open(directory);
// 3、根据IndexWriter创建IndexSearcher
IndexSearcher searcher = new IndexSearcher(reader);
// 4、创建搜索的query
// 创建parse用来确定搜索的内容,第二个参数表示搜索的域
QueryParser parser = new QueryParser("content",new StandardAnalyzer());//content表示搜索的域或者说字段
Query query = parser.parse(keywords);//被搜索的内容
// 5、根据Searcher返回TopDocs
TopDocs tds = searcher.search(query, 20);//查询20条记录
// 6、根据TopDocs获取ScoreDoc
ScoreDoc[] sds = tds.scoreDocs;
// 7、根据Searcher和ScoreDoc获取搜索到的document对象
int cou=0;
for(ScoreDoc sd:sds){
cou++;
Document d = searcher.doc(sd.doc);
// 8、根据document对象获取查询的字段值
/** 查询结果中content为空,是因为索引中没有存储content的内容,需要根据索引path和name从原文件中获取content**/
res+=cou+". "+d.get("path")+" "+d.get("name")+" "+d.get("content")+"\\n";
}
}catch(Exception e){
e.printStackTrace();
}finally{
//9、关闭reader
try {
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return res;
}
public static void main(String[] args) throws IOException
{
System.out.println(indexSearch("你好")); //搜索的内容可以修改
}
}
运行就会看到,搜索出了nihao.txt这个文件
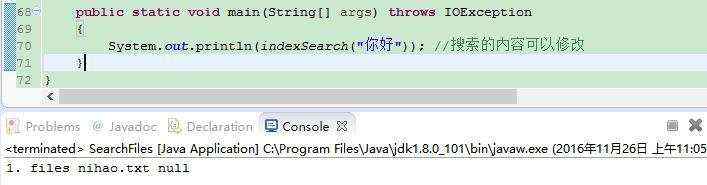
至此,我们已经学会了简单的建立索引和搜索了~~~




![基于Linux开源VOIP系统LinPhone[四]](https://img.php1.cn/3cd4a/1eebe/cd5/ed19db63ee478b98.png)

 京公网安备 11010802041100号
京公网安备 11010802041100号