作者:上帝认我做干爹 | 来源:互联网 | 2024-12-11 19:55
本文将详细介绍Kafka的内部工作机制,包括其工作流程、文件存储机制、生产者与消费者的具体实现,以及如何通过高效读写技术和Zookeeper支持来确保系统的高性能和稳定性。
在完成了Kafka学习环境的搭建、配置文件的理解、生产者与消费者的控制台测试及基础API的学习后,接下来我们将深入探讨Kafka的内部运行机制。
1. Kafka的工作流程
Kafka的工作流程涉及生产者、消费者、主题、分区和副本等核心组件。生产者将消息发送到指定的主题,消息被分配到不同的分区中,每个分区有一个领导者(Leader)和多个跟随者(Follower)。生产者将消息发送给Leader,Leader将消息写入日志文件,随后Follower从Leader同步数据。消费者订阅主题并从Leader读取消息,通过偏移量(Offset)跟踪消费进度。
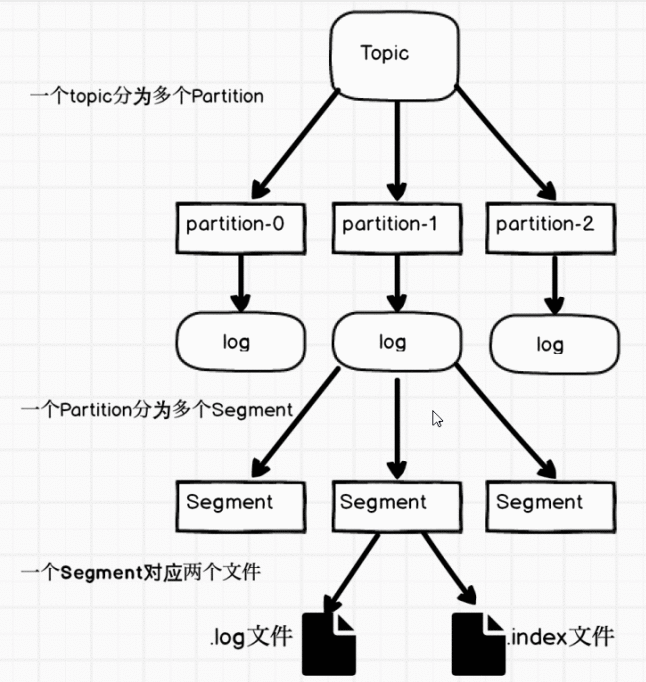
2. Kafka的文件存储机制
Kafka采用分段和索引机制来存储数据,每个主题下的每个分区对应一个日志文件夹,日志文件夹内包含多个段文件(Segment),每个段文件有相应的索引文件。这种机制确保了即使日志文件非常大,也能高效地定位和检索消息。
2.1 Partition 结构
每个分区在物理上表现为一个文件夹,包含多个段文件,每个段文件包含消息数据和索引信息。通过这种方式,Kafka能够高效地管理和访问大量数据。
2.2 Message 结构
每个消息包含偏移量(Offset)、消息大小和消息体等字段。偏移量是一个唯一的ID,用于确定消息在分区中的位置;消息大小用于描述消息的实际长度;消息体则存储实际的数据内容。
2.3 存储策略
Kafka提供了基于时间和大小的数据保留策略,确保数据不会无限增长。默认情况下,数据保留时间为7天,存储大小限制为1GB。这些策略有助于管理存储资源,同时保证数据的可用性。
3. Kafka的生产者
3.1 分区策略
分区策略是Kafka实现高并发和负载均衡的关键。生产者根据特定的算法(如哈希算法)将消息分配到不同的分区,确保数据均匀分布。这种设计不仅提高了系统的吞吐量,还增强了系统的可扩展性。
3.2 数据可靠性保证
Kafka通过ACK机制确保消息的可靠传输。生产者发送消息后,等待Broker的确认响应(ACK)。根据配置的不同,生产者可以选择等待所有副本确认、仅等待Leader确认或不等待任何确认。这种灵活的ACK机制使得用户可以根据需求平衡可靠性和性能。
3.3 Exactly Once 语义
Kafka 0.11版本引入了幂等性支持,结合At Least Once语义,实现了Exactly Once语义。这意味着生产者无论发送多少次重复消息,Broker端只会持久化一条消息。这一特性对于需要高度数据一致性的应用场景尤为重要。
4. Kafka消费者
4.1 消费方式
消费者采用Pull模式从Broker拉取数据,这种方式能够根据消费者的处理能力动态调整数据消费速率,避免了Push模式可能导致的消费者过载问题。此外,Kafka允许消费者设置超时时间,以防止在没有数据时的空循环。
4.2 分区分配策略
消费者组内的消费者通过RoundRobin或Range策略分配分区,确保每个消费者处理不同的分区。这种分配机制保证了数据的均匀分布和高效处理。
4.3 Offset的维护
消费者需要定期提交Offset,以记录当前的消费进度。如果消费者发生故障,可以从上次提交的Offset处恢复消费,确保数据不丢失。从Kafka 0.9版本开始,Offset默认存储在Kafka的内部主题__consumer_offsets中。
5. Kafka高效读写数据
5.1 顺序读写
Kafka通过顺序写入日志文件,显著提高了写入性能。与随机写入相比,顺序写入减少了磁头寻址时间,提高了I/O效率。
5.2 零拷贝技术
零拷贝技术减少了数据在操作系统和应用程序之间的拷贝次数,降低了CPU和内存的消耗,进一步提升了系统的性能。
5.3 Page Cache
Kafka利用操作系统的Page Cache,将数据直接存储在内存中,避免了频繁的磁盘I/O操作,从而大幅提高了读写速度。
6. Zookeeper在Kafka中的作用
Zookeeper在Kafka中扮演着协调者的角色,负责管理集群状态、主题和分区的元数据、Leader选举等关键任务。通过Zookeeper,Kafka能够实现高可用性和动态伸缩,确保系统的稳定运行。











 京公网安备 11010802041100号
京公网安备 11010802041100号