consumer是读取kafka集群某些topic消息的应用程序。
消费者用一个消费者组名来标记自己,topic的每条消息都只会被发送到每个订阅它的消费者组的一个消费者实例上。
我们知道kafka同时支持基于队列和基于发布/订阅两种消息引擎模型。事实上kafka就是通过consumer group实现对这两种模型的支持。
这里指的是consumer端的offset,与分区日志中的offset是不同的含义。每个consumer实例都会为它消费的分区维护属于自己的位置信息来记录当前消费了多少条消息。
kafka使用consumer group保存offset,那么只需要简单的保存一个长整型数据就可以了,同时kafka consumer还引入了检查点机制定期对offset进行持久化,从而简化了应答机制的实现。
consumer客户端需要定期的向kafka集群汇报自己消费数据的进度,这一过程被称为位移提交。
新版本和旧版本的consumer提交位移的方式截然不同:旧版本consumer会定期将位移信息提交到zk下的固定节点。但是zk只是一个协调服务的组件,他并不适合作为位移信息的存储组件。所以新版本的consumer把位移提交到kafka的一个内部topic(__consumer_offsets)上。
Rebalance只对consumer group有效。什么是Rebalance?它本质上是一种协议,规定了一个consumer group下所有consumer如何达成一致来分配topic的所有分区。举个例子,假设我们有一个consumer group,它有20个consumer实例。该group订阅了一个具有100个分区的topic。那么正常情况下,consumer group平均会为每个consumer分配5个分区,即每个consumer负责读取5个分区的数据。这个分配过程就被称作Rebalance。
以下是springboot集成kafka相关的代码以及配置,我们这边springboot选用的版本是2.3.5.RELEASE,对应的org.springframework.kafka版本是2.5.7。
我这边是直接在项目中用的,所以我这边的代码只是与kafka相关的,不是很完整。
导入kafka依赖
<!-- 引入kafka依赖 -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
在配置文件中配置我们需要用到的参数,我们这边用的是yaml文件格式。
spring:
kafka:
bootstrap-servers: localhost:9092,localhost:9093,localhost:9094
consumer:
# 用于表示该consumer想要加入到哪个group中。默认值是 “”。
group-id: training-platform-consumer
# 当consumer向一个broker发起fetch请求时,broker返回的records的大小最小值。如果broker中数据量不够的话会wait,直到数据大小满足这个条件。
fetch-min-size: 1
# Fetch请求发给broker后,在broker中可能会被阻塞的(当topic中records的总size小于fetch.min.bytes时),此时这个fetch请求耗时就会比较长。这个配置就是来配置consumer最多等待response多久。
fetch-max-wait: 500
# 心跳间隔。心跳是在consumer与coordinator之间进行的。心跳是确定consumer存活,加入或者退出group的有效手段。这个值必须设置的小于session.timeout.ms,因为:
# 当Consumer由于某种原因不能发Heartbeat到coordinator时,并且时间超过session.timeout.ms时,就会认为该consumer已退出,它所订阅的partition会分配到同一group 内的其它的consumer上。
heartbeat-interval: 3000
# Consumer 在commit offset时有两种模式:自动提交,手动提交。手动提交:通过调用commitSync、commitAsync方法的方式完成offset的提交。
# 自动提交:是Kafka Consumer会在后台周期性的去commit。
enable-auto-commit: false
# 这个配置项,是告诉Kafka Broker在发现kafka在没有初始offset,或者当前的offset是一个不存在的值(如果一个record被删除,就肯定不存在了)时,该如何处理。它有4种处理方式:
#1) earliest:自动重置到最早的offset。
#2) latest:看上去重置到最晚的offset。
#3) none:如果边更早的offset也没有的话,就抛出异常给consumer,告诉consumer在整个consumer group中都没有发现有这样的offset。
# 如果不是上述3种,只抛出异常给consumer。
auto-offset-reset: latest
# Consumer每次调用poll()时取到的records的最大数。
max-poll-records: 50
# Consumer进程的标识。如果设置一个人为可读的值,跟踪问题会比较方便。
client-id: training-platform-consumer
使用@ConfigurationProperties注解,将参数注入到对象
/**
* @author : light
* @date: 2020/11/10 14:32
*/
@Data
@Configuration
@ConfigurationProperties(prefix = "spring.kafka")
public class SpringKafkaEnvConfig {
private String bootstrapServers;
private Consumer consumer;
/**
* consumer 消息消费者配置
*/
@Data
public static class Consumer {
private String groupId;
private Integer fetchMinSize;
private Integer fetchMaxWait;
private Integer heartbeatInterval;
private Boolean enableAutoCommit;
private String autoOffsetReset;
private Integer maxPollRecords;
private String clientId;
}
}
自定义Consumer相关配置
/**
* @author : light
* @date: 2020/11/11 10:30
*/
@Configuration
@EnableKafka
@Slf4j
public class KafkaConsumerConfig {
@Autowired
private KafkaEnvConfig springKafkaEnvConfig;
/**
* 扩展监听器使用(监听容器工厂)
* @return KafkaListenerContainerFactory
*/
@Bean(name = "kafkaListenerContainerFactory")
public KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, String>>
kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
//设置并发量,小于或等于Topic的分区数,并且要在consumerFactory设置一次拉取的数量
factory.setConcurrency(Constants.NUM_ONE);
//设置拉取等待时间(也可间接的理解为延时消费)
factory.getContainerProperties().setPollTimeout(Constants.NUM_THREE_THOUSAND);
//指定使用此bean工厂的监听方法,消费确认为方式为用户指定aks,
// 可以用下面的配置也可以直接使用enableAutoCommit参数
factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL_IMMEDIATE);
return factory;
}
/**
* 批量处理消息
* @return KafkaListenerContainerFactory
*/
@Bean(name = "batchFactory")
public KafkaListenerContainerFactory<?> batchFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.setBatchListener(true);
return factory;
}
/**
* 消费者工厂
* @return ConsumerFactory
*/
@Bean
public ConsumerFactory<String, String> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
/**
* 消费者配置
* @return Map
*/
@Bean
public Map<String, Object> consumerConfigs() {
Map<String, Object> consumerConfigs = Maps.newHashMap();
//kafka服务端地址
consumerConfigs.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, springKafkaEnvConfig.getBootstrapServers());
//序列化方式,七种,最常用的是String
consumerConfigs.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
consumerConfigs.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
//用于表示该consumer想要加入到哪个group中。默认值是 “”。
consumerConfigs.put(ConsumerConfig.GROUP_ID_CONFIG, springKafkaEnvConfig.getConsumer().getGroupId());
//当consumer向一个broker发起fetch请求时,broker返回的records的大小最小值。
//如果broker中数据量不够的话会wait,直到数据大小满足这个条件。
consumerConfigs.put(ConsumerConfig.FETCH_MIN_BYTES_CONFIG,
springKafkaEnvConfig.getConsumer().getFetchMinSize());
//Fetch请求发给broker后,在broker中可能会被阻塞的(当topic中records的总size小于fetch.min.bytes时),
// 此时这个fetch请求耗时就会比较长。这个配置就是来配置consumer最多等待response多久。
consumerConfigs.put(ConsumerConfig.FETCH_MAX_WAIT_MS_CONFIG,
springKafkaEnvConfig.getConsumer().getFetchMaxWait());
//Consumer session 过期时间。这个值必须设置在broker configuration中的
// group.min.session.timeout.ms 与 group.max.session.timeout.ms之间。
consumerConfigs.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, Constants.NUM_TEN_THOUSAND);
//心跳间隔。心跳是在consumer与coordinator之间进行的。心跳是确定consumer存活,加入或者退出group的有效手段。
// 这个值必须设置的小于session.timeout.ms,因为:当Consumer由于某种原因不能发Heartbeat到coordinator时,
// 并且时间超过session.timeout.ms时,就会认为该consumer已退出,它所订阅的partition会分配到同一group 内的其它的consumer上。
consumerConfigs.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG,
springKafkaEnvConfig.getConsumer().getHeartbeatInterval());
//Consumer 在commit offset时有两种模式:自动提交,手动提交。
// 手动提交:通过调用commitSync、commitAsync方法的方式完成offset的提交。
// 自动提交:是Kafka Consumer会在后台周期性的去commit。
consumerConfigs.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,
springKafkaEnvConfig.getConsumer().getEnableAutoCommit());
//这个配置项,是告诉Kafka Broker在发现kafka在没有初始offset,或者当前的offset是一个不存在的值
// (如果一个record被删除,就肯定不存在了)时,该如何处理。它有4种处理方式:
//1) earliest:自动重置到最早的offset。
//2) latest:看上去重置到最晚的offset。
//3) none:如果边更早的offset也没有的话,就抛出异常给consumer,
// 告诉consumer在整个consumer group中都没有发现有这样的offset。
//如果不是上述3种,只抛出异常给consumer。
consumerConfigs.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,
springKafkaEnvConfig.getConsumer().getAutoOffsetReset());
//Consumer每次调用poll()时取到的records的最大数。
consumerConfigs.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG,
springKafkaEnvConfig.getConsumer().getMaxPollRecords());
//Consumer进程的标识。如果设置一个人为可读的值,跟踪问题会比较方便。
consumerConfigs.put(ConsumerConfig.CLIENT_ID_CONFIG,
springKafkaEnvConfig.getConsumer().getClientId());
return consumerConfigs;
}
/**
* 消息消费失败处理
* @return ConsumerAwareListenerErrorHandler
*/
@Bean(name = "consumerListenerErrorHandler")
public ConsumerAwareListenerErrorHandler consumerListenerErrorHandler() {
return new ConsumerAwareListenerErrorHandler() {
@Override
public Object handleError(Message<?> message, ListenerExecutionFailedException exception, Consumer<?, ?> consumer) {
log.info("消息消费失败,message:{}", message.getPayload().toString());
return null;
}
};
}
}
接受消息的工具类
/**
* @author : light
* @date: 2020/11/11 11:38
*/
@Component
@Slf4j
public class KafkaConsumerListener {
/**
* 消费消息
* @param record record
* @param ack ack
*/
@KafkaListener(id = "training-platform-consumer", containerFactory = "kafkaListenerContainerFactory",
topics = "topic_model", errorHandler = "consumerListenerErrorHandler")
public void listener(ConsumerRecord<String, String> record, Acknowledgment ack) {
log.info("收到生产者发送的的消息,message:={}", record.toString());
ack.acknowledge();
}
}
消息发送测试
@SpringBootTest
class PlatformApplicationTests {
@Test
void contextLoads() {
}
@Autowired
private KafkaProducer kafkaProducer;
@Resource
private SpringKafkaEnvConfig config;
@Test
public void sendMessage() {
kafkaProducer.sendToKafkaAsync(config.getTopic().getName(), "aaaaa");
}
}
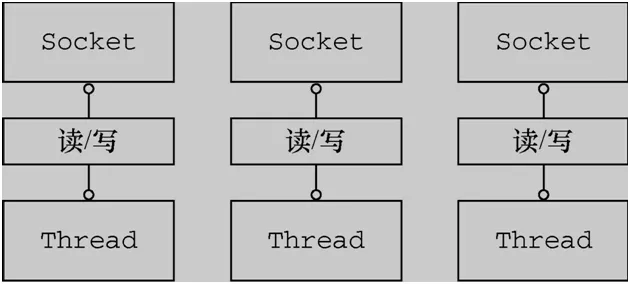
kafka的consumer是用来读取消息的,而且要能够同时读取多个topic的多个分区的消息。若要实现并行的消息读取,一种方法是使用多线程的方式,为每个要读取的分区都创建一个专有的线程去消费(这个是老版本consumer的实现);另一种方式是采用类似于Linux I/O模型的poll或select等,使用一个线程来同时管理多个socket连接,即同时与多个broker通信实现消息读取——这是新版本consumer最重要的设计改变。
一旦consumer订阅了topic,所有的消费逻辑包括coordinator的协调、消费者组的Rebalance以及数据的获取都会在主逻辑poll方法的一次调用中被执行。这样我们可以很容易使用一个线程来管理所有的consumer I/O操作。
新版本的consumer是一个多线程(两个)的Java进程——创建consumer的线程称为主线程,同时KafkaConsumer在后台会创建一个心跳线程,该线程被称为后台心跳线程。KafkaConsumer的poll方法在用户主线程中运行。这也就说明:消费者组执行Rebalance、消息获取、coordinator管理、异步任务结果的处理甚至位移提交等操作都是运行在用户主线程中的。因此仔细调优这个poll方法相关的各种处理超时时间参数至关重要。
consumer会在kafka集群的所有broker中选择一个broker作为consumer group的coordinator,用于实现组成员管理、消费分配方案制定以及提交位移等。
当消费者组首次启动时,由于没有初始位移信息,coordinator必须为其确定初始位移值,这就是consumer参数auto.offset.reset的作用。通常情况下,consumer要么从最早的位移开始读取,要么从最新的位移开始读取。
当consumer运行了一段时间之后,它必须提交自己的位移值。如果consumer崩溃或被关闭,他负责的分区就会被分配给其他的consumer,因此一定要在其他consumer读取这些分区前就应该做好位移提交工作,否则会出现消息的重复消费。
consumer提交位移的主要机制是通过所属的coordinator发送位移提交请求来实现的。每个位移提交请求都会往__consumer_offsets对应分区上追加写入一条消息。消息的key是group.id、topic和分区的元组,而value就是位移值。如果consumer为同一个topic分区提交了多次位移,那么__consumer_offsets对应的分区上就会有若干条key相同但是value1不同的消息,但是我们只关心最新一次提交的那条消息。从某种程度上来说,只有最新提交的位移值是有效的,其他消息包含位移其实都过期了。
位移提交策略对于消息交付语义至关重要。默认情况下,consumer是自动提交位移的,自动提交间隔5秒。这就是说若不做特定的设置,consumer程序在后台自动提交位移。通过设置auto.commit.interval.ms参数可以控制自动提交的间隔。
自动提交唯一的优势是降低了客户的开发成本使得用户不必亲自处理位移提交;劣势是用户不能细粒度的处理位移的提交,特别是在有较强的精确一次处理语义时。这种情况下,可以使用手动位移提交。
所谓的手动位移提交就是客户自行确定消息何时被真正的处理完毕并可以提交位移。在一个典型的consumer中,用户需要对poll方法返回的消息执行业务级别的处理。用户想要确保只有消息被真正的处理完之后再提交位移。如果使用自动位移提交则无法保证这种时序性,因此在这种情况下必须手动提交位移。在构建consumer时,将enable.auto.commit设置为false.
下面就是设置完之后,需要手动提交的例子:
/**
* 消费消息
* @param record record
* @param ack ack
*/
@KafkaListener(id = "training-platform-consumer", containerFactory = "kafkaListenerContainerFactory",
topics = "topic_model", errorHandler = "consumerListenerErrorHandler")
public void listener(ConsumerRecord<String, String> record, Acknowledgment ack) {
log.info("收到生产者发送的的消息,message:={}", record.toString());
ack.acknowledge();
}
consumer自动提交和手动提交之间的特点比较:





 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有