作者:叫爸算了_459 | 来源:互联网 | 2023-08-13 19:16
在JobTracker任务调度器之JobQueueTaskScheduler中(见 2012-01/50857.htm),我讲述Job任务调度的时候简单地讲述了一下Job任务的分解,也就是将一个作业Job切分为一个个相对独立的map任务,以及后面的reduce任务。那么,Hadoop的Mapreduce,确切的说是JobTracker是如何来分解作业Job的呢?当然,在JobTracker中并不把这个动作叫做作业分解,而是叫做“初始化作业”。所以,在接下来的时间里,我将给大家详细的讨论这个过程的实现。
先来看看“初始化作业”这个过程所以来的类图吧!
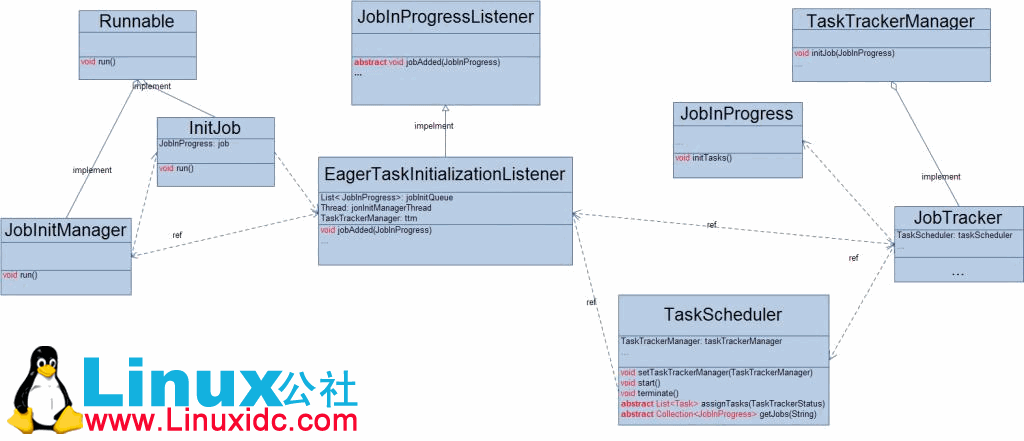
当客户端JobClient向JobTracker提交一个Job之后,JobTracker会把这个Job对应的JobInProgress交给监听器JobInProgressListener,从上面的类图我们可以看出,JobTracker把新来的Job交给JobInProgressListener的一个实现EagerTaskInitializationListener来初始化它。在EagerTaskInitializationListener中,它有一个后台线程JobInitManager,专门负责初始化JobInProgress。在JobInitManager中又采用线程池的方式有效的完成Job的初始化。

根据上面的一个新到的Job初始化过程可知,对一个Job进行map和reduce任务的划分,最终还是由这个Job对应的JobInProgress来完成,所以接下来我们就要重点关注一下JobInProgress的initTasks()方法,这也却如其名。
在JobInProgress的initTasks()方法中,它会首先读取这个Job的job.split文件,关于这个文件的产生和存放位置我记得在前面的博文中详细的提到过,不清楚的童鞋可以去好好看看。但是要注意的是,此时的这个split文件在逻辑上并不在JobTracker本地的文件系统。split文件记录了对所有的输入数据的切分,它被读取之后的每一个输入数据切片都被用一个RawSplit(RawSplit记录了数据的路径,范围,所有的位置信息)来表示,同时每一个RawSplit也就对应了一个MapTask——Job的map任务也就是这样产生了。之后就根据客户端提交Job是设置的reduce任务数来创建Job的reduceMaps,这个reduce任务数量是根据job.xml中的配置项mapred.reduce.tasks确定的。然后又会计算在什么时候开始调用reduce任务,也就是当有多少个map任务被成功完成之后就开始调用reduce任务。这个阈值是怎么计算的呢?很简单:
DEFAULT_COMPLETED_MAPS_PERCENT_FOR_REDUCE_SLOWSTART = 0.05f;
completedMapsForReduceSlowstart = (int)Math.ceil((conf.getFloat("mapred.reduce.slowstart.completed.maps", DEFAULT_COMPLETED_MAPS_PERCENT_FOR_REDUCE_SLOWSTART) * numMapTasks));
客户端如何自己配置这个阈值,就不用我说了吧。最后,JobInProgress还会创建另外的四个Task,它们分别是map的cleanup任务、setup任务,reduce的cleanup任务、setup任务,至于这个Task的用户,我会在后面的博文中详细阐述。
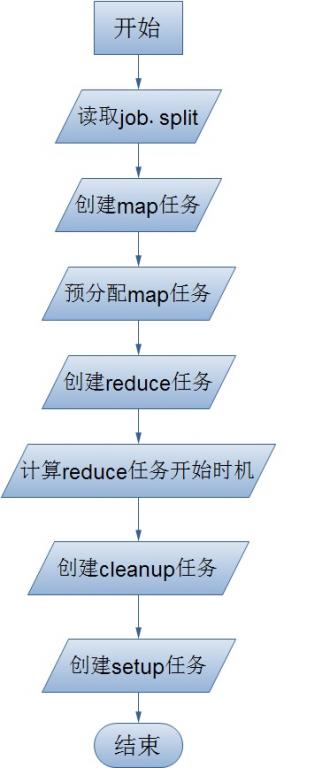
在上面的流程图中,大家可能对预分配map任务感到有些莫名其妙,我首先要申明这个名字是我自己取的,因为实在是找不到关于这个步骤的中文解释,若有大牛有跟准确的解释,请及时给我指正,拜谢先!那么这个“预分配map任务”到底干了什么事情呢?它首先是对每一个输入数据切片的所有副本位置信息就行解析(我们知道,在Hadoop中,所有的节点或被解析成一个网络拓扑图,根据这个图来计算任意两个节点之间的距离),每一个副本的位置被解析成一个Node,然后依次向上获取这个Node的父Node,祖父Node,...,究竟向上扩展多少层,由hadoop的配置文件中的项mapred.task.cache.levels来设置,这些节点就会和这个数据切片对应的map任务进行绑定,当我们给一个TaskTracker分配map任务的时候,就会参考这个缓存信息并根据就近原则来分配了。贴出源代码:
private Map> createCache(JobClient.RawSplit[] splits, int maxLevel) {
Map> cache = new IdentityHashMap>(maxLevel);
for (int i = 0; i String[] splitLocatiOns= splits[i].getLocations();
if (splitLocations.length == 0) {
nonLocalMaps.add(maps[i]);
continue;
}
for(String host: splitLocations) {
Node node = jobtracker.resolveAndAddToTopology(host);
LOG.info("tip:" + maps[i].getTIPId() + " has split on node:" + node);
for (int j = 0; j List hostMaps = cache.get(node);
if (hostMaps == null) {
hostMaps = new ArrayList();
cache.put(node, hostMaps);
hostMaps.add(maps[i]);
}
if (hostMaps.get(hostMaps.size() - 1) != maps[i]) {
hostMaps.add(maps[i]);
}
node = node.getParent();
}
}
}
return cache;
}









 京公网安备 11010802041100号
京公网安备 11010802041100号