1. 消息驱动概述
1.1 是什么
在实际应用中有很多消息中间件,比如现在企业里常用的有ActiveMQ、RabbitMQ、RocketMQ、Kafka等,学习所有这些消息中间件无疑需要大量时间经历成本,那有没有一种技术,使我们不再需要关注具体的消息中间件的细节,而只需要用一种适配绑定的方式,自动的在各种消息中间件内切换呢?消息驱动就是这样的技术,它能 屏蔽底层消息中间件的差异,降低切换成本,统一消息的编程模型。
SpringCloud Stream是一个构件消息驱动微服务的框架。应用程序通过inputs和outputs来与SpringCloud Stream中的绑定器(binder)对象交互,通过配置来绑定,而SpringCloud Stream的绑定器对象负责与消息中间件交互,所以,我们只需要搞清楚如何与SpringCloud Stream交互就可以方便使用消息驱动的方式。但是 截至到目前 SpringCloud Stream仅支持RabbitMQ和Kafka。
1.2 设计思想
标准MQ模型
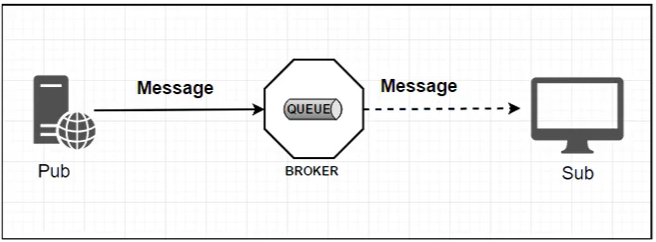
- 生产者 / 消费者之间靠消息媒介传递信息内容 -
Messag - 消息必须走特定的通道 -
Message Channel - 消息通道里的消息如何被消费呢?谁负责处理? - 消息通道
MessageChannel的子接口SubscribableChannel,由 MessageHandler 消息处理器所订阅
为什么使用Cloud Stream
比如说我们用到了RabbitMQ和Kafka,由于这两个消息中间件的架构上的不同,像RabbitMQ有exchange,Kafka有Topic和Partitions分区,这些中间件的差异性导致实际项目开发给我们造成了一定的困扰,我们如果用了两个消息队列的其中一种,后面的业务需求如果又要往另外一种消息队列进行迁移,这无疑是一个灾难,一大堆东西都要重新推到重做,因为它跟我们的系统耦合了,这时候SpringCloud Stream给我们提供了一种解耦合的方式。

stream凭什么可以统一底层差异
在没有绑定器这个概念的情况下,我们的SpringBoot应用要直接与消息中间件进行信息交互的时候,由于各消息中间件构建的初衷不同,它们的实现细节上会有较大的差异性。
通过定义绑定器作为中间层,完美的实现了 应用程序与消息中间件细节之间的隔离。Stream对消息中间件的进一步封装(通过向应用程序暴露统一的Channel通道,使得应用程序不需要再考虑各种不同的消息中间件实现),可以做到代码层面对中间件的无感知,甚至于动态的切换中间件(如RabbitMQ切换为Kafka),使得微服务开发的高度解耦,服务可以更多的关注自己的业务流程。
在消息绑定器中,INPUT对应于消费者,OUTPUT对应于生产者。
Stream中的消息通信方式遵循了 发布-订阅模式,用Topic(主题)进行广播(RabbitMQ中对应于Exchange交换机,Kafka中就是Topic)。
1.3 SpringCloud Stream标准流程套路
-
Binder很方便的连接中间件,屏蔽差异 -
Channel通道,是队列Queue的一种抽象,在消息通讯系统中就是实现了存储和转发的媒介,通过Channel对队列进行配置 -
Source和Sink简单的可以理解为参照对象是SpringCloud Stream自身,从Stream发布消息就是输出,接受消息就是输入

1.4 SpringCloud Stream编码API与常用注解

| 组成 | 说明 |
|---|---|
| Middleware | 中间件,目前只支持RabbitMQ和Kafka |
| Binder | Binder是应用与消息中间件之间的封装,目前实行了RabbitMQ和Kafka的Binder,通过Binder可以很方便的连接中间件,可以动态的改变消息类型(对应于Kafka的topic,RabbitMQ的exchange),这些都可以通过配置文件来实现 |
| @Input | 注解标识输入通道,通过该输入通道接收到的消息进入应用程序 |
| @Output | 注解标识输出通道,发布的消息将通过该通道离开应用程序 |
| @StreamListner | 监听队列,用于消费者的队列的消息接收 |
| @EnableBinding | 使信道Channel和交换机/主题(Exchange/Topic)绑定在一起 |
2. Spring Cloud Stream 案例
新建三个子模块分别对应于消息的生产者和消费者:
| 模块名 | 微服务功能 |
|---|---|
| cloud-stream-rabbitmq-provider8801 | 生产者,发送消息模块 |
| cloud-stream-rabbitmq-consumer8802 | 消费者,接收消息模块 |
| cloud-stream-rabbitmq-consumer8803 | 消费者,接收消息模块 |
2.1 消息驱动之消息生产者
新建Module:cloud-stream-rabbitmq-provider8801作为消息的生产者用来发送消息,在其POM文件中除引入web、actuator、eureka-client等必要启动器外,还需要引入SpringCloud Stream对应实现RabbitMQ的启动器依赖:
org.springframework.cloud
spring-cloud-starter-stream-rabbit
编写其配置文件application.yml:
server:
port: 8801
spring:
application:
name: cloud-stream-provider
cloud:
stream:
binders: # 在此处配置要绑定的rabbitmq的服务信息
defaultRabbit: # 表示定义的名称,用于于binding整合
type: rabbit # 消息组件类型
environment: # 设置rabbitmq的相关的环境配置
spring:
rabbitmq:
host: mpolaris.top
port: 5672
username: admin
password: 1234321
bindings: # 服务的整合处理
output: # 这个名字是一个通道的名称,OUTPUT表示这是消息的发送方
# 表示要使用的Exchange名称定义
destination: testExchange
# 设置消息类型,本次为json,文本则设置“text/plain”
content-type: application/json
# 设置要绑定的消息服务的具体设置
default-binder: defaultRabbit
eureka:
client: # 客户端进行Eureka注册的配置
service-url:
defaultZone: http://eureka7001.com:7001/eureka
instance:
# 设置心跳的时间间隔(默认是30秒)
lease-renewal-interval-in-seconds: 2
# 如果现在超过了5秒的间隔(默认是90秒)
lease-expiration-duration-in-seconds: 5
# 在信息列表时显示主机名称yml
instance-id: send-8801.com
# 访问的路径变为IP地址
prefer-ip-address: true
编写其主启动类
编写业务类,在业务类中分别要编写 发送消息接口 及其 实现类,并在发送接口消息的实现类中 添加 @EnableBinding 注解 用来绑定消息的推送管道,消息生产者绑定的消息推送管道为 org.springframework.cloud.stream.messaging.Source:
public interface IMessageProvider {
public String send();
}
import org.springframework.cloud.stream.annotation.EnableBinding;
import org.springframework.cloud.stream.messaging.Source;
import org.springframework.integration.support.MessageBuilder;
import org.springframework.messaging.MessageChannel;
import javax.annotation.Resource;
import java.util.UUID;
/**
* @Author polaris
* @Date 2021/3/4 21:46
*/
@EnableBinding(Source.class) //定义消息的推送管道
public class MessageProviderImpl implements IMessageProvider {
@Resource
private MessageChannel output; //消息发送管道
@Override
public String send() {
String serial = UUID.randomUUID().toString();
output.send(MessageBuilder.withPayload(serial).build()); //发送消息
System.out.println("==> serial:" + serial);
return null;
}
}
注意我们在service的实现类中不再需要@Service注解,因为这个service不再是传统意义上的和Controller、DAO数据等进行交互的service,而是要绑定绑定器打交道的service。
然后编写其业务层的Controller:
@RestController
public class SendMessageController {
@Autowired
private IMessageProvider messageProvider;
@GetMapping("/sendMessage")
public String sendMessage() {
return messageProvider.send();
}
}
启动服务注册中心后和RabbitMQ后,启动消息生产者微服务,我们在RabbitMQ的控制面板中可以看见多出了一个名为testExchange的交换机,这个交换机恰恰就是我们之前在配置文件中配置的交换机名字testExchange。
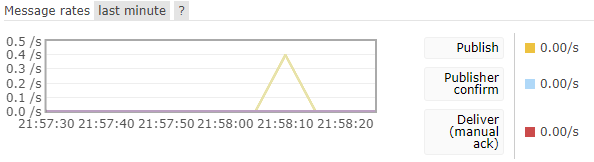
然后我们访问 http://localhost:8801/sendMessage 使用消息生产者微服务发送消息,在其微服务后台我们看到了打印的消息。
在RabbitMQ的控制面板中我们也看到了确实发送了消息。
2.2 消息驱动之消息消费者
新建Module:cloud-stream-rabbitmq-consumer8802/8803作为消息的生产者用来接收消息,其POM文件中引入的启动器依赖和消息生产者微服务的依赖几乎相同,然后编写其配置文件application.yml,其配置文件的书写和消息生产者的几乎一致,特别需要注意的是,消息生产者微服务用到的通道为OUTPUT,而消息消费者微服务用到的通道为INPUT,其他的配置文件信息就只需要注意端口号、注册服务名的区别即可:
spring:
cloud:
bindings:
input: # 这个名字是一个通道的名称,INPUT表示消息消费者
编写主启动类
编写消息消费者的业务类,由于是消费者,所以只需要编写其Controller即可,在其Controller上同样需要添加 @EnableBinding 注解用来绑定消息的推送管道,消息消费者绑定的消息推送管道为import org.springframework.cloud.stream.messaging.Sink,在接收消息的方法中需要使用 @StreamListner 注解来监听其绑定的消息推送管道:
@Component
@EnableBinding(Sink.class)
public class ReceiveMessageController {
@Value("${server.port}")
private String serverPort;
@StreamListener(Sink.INPUT)
public void input(Message message) {
System.out.println("消费者" + serverPort + "号,收到消息:"
+ message.getPayload());
}
}
然后启动消息发送消费者服务,用生产者发送消息,我们可以发现在消费者端可以成功接收到消息。
3. 分组消费和持久化
3.1 重复消费问题
当生产者发送消息后,此时的我们的消费者都接受了消息并进行了消费,也就是说同一条消息被多个消息消费者所消费。
上述的问题就是消息的 重复消费 问题,那么这个问题为什么如此重要呢?其实重复消费这个问题本身不可怕,可怕的是没考虑到重复消费之后,怎么保证幂等性。(幂等性 通俗的说,就一个数据,或者一个请求,重复很多次,需要确保对应的数据是不会改变的,不能出错)。分布式微服务应用为了实现高可用和负载均衡,实际上同一功能的服务都会部署多个具体的服务实例。举个例子,假设有一个系统,有一条消息要求往数据库里插入一条数据,要是这个消息重复消费两次,结果就是向数据库里插入了两条数据,这样数据就错了,就违背了幂等性原则,但是要是该消息消费到第二次的时候,可以判断一下已经消费过了,然后直接将该消息丢弃,这就实现了只插入一条数据,一条消息重复出现了两次,但是只有第一次真正被消费了,数据库里也就只插入了一条数据,这就保证了系统的幂等性。
上面简单的介绍了消息的重复消费问题,那如何解决这种重复消费问题呢,那就需要我们进行 分组和持久化属性组 操作,利用SpringCloud Stream中的消息分组来解决这个问题,需要注意的是在Stream中处于同一组中的多个消息消费者是竞争关系,也就是保证生产者所发送的同一个消息只会被其中一个消费者消费一次。 不同组的消费者是可以对消息进行全面消费(重复消费)的,只有同一组内才会发生竞争关系。
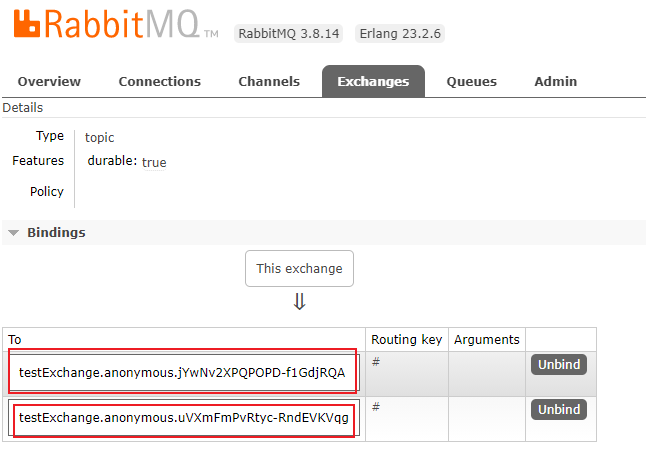
在RabbitMQ中,默认分组group是不同的,组流水号不一样,被认为不同组,我们查看testExchange交换机,可以发现8802和8803两个消息消费者处于不同的组,所以8801消息生产者发送的消息可以被这两个消费者重复消费:
3.2 分组解决重复消费问题
上面在RabbitMQ控制面板中我们看到的组流水号是系统随机分配的,这样无疑不好控制,所以我们应该自定义配置分组,将8802/8803两个消息消费者微服务分为同一个组,以此来解决消息的重复消费问题。
先来演示如何自定义分组
在8802/8803微服务中的配置文件中分别添加组名属性:
spring:
cloud:
stream:
bindings:
input:
group: A/B # 分组名称
这里我们将8802设置为A组,8803设置为B组,然后我们将消息消费方的两个微服务重启,我们再次查看其组流水号,发现不再是长长的随机组流水号,而变成了我们自定义的分组:
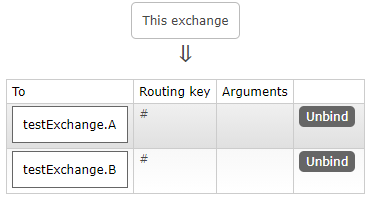
此时由于8802/8803位于两个不同分组下,所以没有竞争关系,消息生产者发送消息后,仍然可以重复消费。
下面我们将这两个消息消费方微服务分到相同的消费组中,这样每次就只有一个消费者,消息生产者发送的消息只能被8802或8803其中一个接受到,这样就避免了重复消费,将8802和8803的分组名都改为A,再次重启两个消息消费方微服务,此时我们可以看到在分组A下已经有了两个消费者。
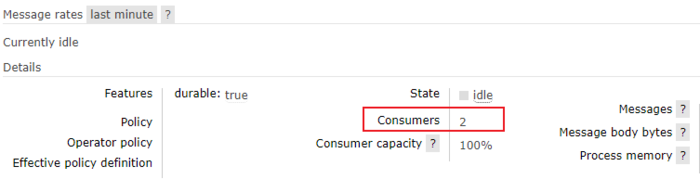
再用生产者发送5条消息,我们发现8802/8803分别消费了3条和2条不同的消息,而没有出现重复消费的问题。
3.3 持久化
通过上述,解决了重复消费问题,再来看看持久化
加上了group就自动支持持久化了
下面来演示一下持久化
-
停止8802/8803并去除掉8802分组group:A(8803的分组group A没有去掉)
-
8801发送4条消息到rabbitmq
-
先启动8802(无分组属性配置),后台没有打出来消息(消息丢失故障)
-
再启动8803(有分组属性配置),后台打出了4条消息(消费持久化消息)





 京公网安备 11010802041100号
京公网安备 11010802041100号