虽然我是一个深度学习方面的小白,但是对于卷积神经网络我仍然有很强的好奇心,所以特地学习了一下,如果出现了错误还望大家及时指正*~*。
文章目录
- 一、简介
- 二、网络结构
- 三、代码实现(Paddle)
- 四、小结
一、简介
在LeNet提出后的几十年里,神经网络一度被其他机器学习的方法超越,而导致出现这种情况的原因主要有:(1)数据,一个包含许多特征的深度模型它需要大量的有标签的数据才能表现得比其他经典方法更好;(2)硬件(算力),深度学习对计算资源要求很高,但是早期的硬件计算能力非常有限。直到2012年,这两点都得到了很大程度的改善,这也就造就了AlexNet模型的横空出世。它首次证明了学习到的特征可以超越手工设计的特征,一举打破了困扰计算机视觉研究的瓶颈。
二、网络结构
AlexNet与LeNet的设计理念非常相似,但也有非常明显的区别。第一、AlexNet包含5层卷积、2层全连接隐藏层以及1层全连接输出层;第二、AlexNet模型将sigmoid激活函数更改为了更为简单的ReLU激活函数;第三、AlexNet通过丢弃法(Dropout)有效的控制了全连接层的模型复杂度,防止引入过多的参数;第四、AlexNet引入了大量的图像增广,如翻转、裁剪以及颜色变化等,有效的增加了数据样本的数量,从而缓解了过拟合现象的发生。
由于ImageNet数据集中的图像要比MINST数据集大许多,所以需要更大的卷积核来捕捉物体,因此第一层卷积核的窗口为11×11。而第二层卷积核就减少到5×5,之后就一直采用3×3。此外,第一、第二和第五个卷积层之后都使用了窗口形状为3×3、步幅为2的最大池化层,最后就是一般的全连接层。借用书中的图来表示一下(主要是我自己作图太难看*^*):
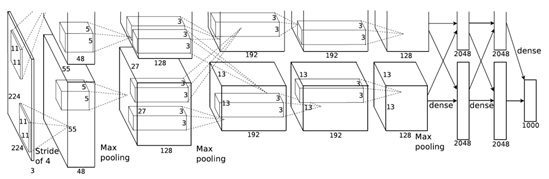
但是呢,你只要细心一点就会发现,第一层卷积层的224×224是有问题的,应该是227×227才对,这一点在吴恩达老师的视频中也被提到,所以正确的图应该是下面这个。

三、代码实现(Paddle)
虽然知道上面的224×224是有点问题的,但是我还只能用它来完成我的AlexNet实验,这是因为当我使用227×227时,出现了下面的错误:

总的来说就是电脑配置有点差,没法完成这个实验*^*,所以就将就一下使用224×224来进行测试了,框架使用的是百度的paddle飞桨,代码如下所示。
import paddle
import paddle.nn.functional as F
class AlexNet(paddle.nn.Layer):def __init__(self) -> None:super(AlexNet,self).__init__()self.conv1 = paddle.nn.Conv2D(in_channels = 1, out_channels = 96, kernel_size = 11, stride = 4)self.conv2 = paddle.nn.Conv2D(in_channels = 96, out_channels = 256, kernel_size = 5, stride = 1, padding = 2)self.conv3 = paddle.nn.Conv2D(in_channels = 256, out_channels = 384, kernel_size = 3, stride = 1, padding = 1)self.conv4 = paddle.nn.Conv2D(in_channels = 384, out_channels = 384, kernel_size = 3, stride = 1, padding = 1)self.conv5 = paddle.nn.Conv2D(in_channels = 384, out_channels = 256, kernel_size = 3, stride = 1, padding = 1)self.pool1 = paddle.nn.MaxPool2D(3,2)self.pool2 = paddle.nn.MaxPool2D(3,2)self.pool3 = paddle.nn.MaxPool2D(3,2)self.linear1 = paddle.nn.Linear(in_features = 256*5*5, out_features = 4096)self.linear2 = paddle.nn.Linear(in_features = 4096, out_features = 4096)self.linear3 = paddle.nn.Linear(in_features = 4096, out_features = 10)def forward(self,x):x = self.conv1(x)x = F.relu(x)x = self.pool1(x)x = self.conv2(x)x = F.relu(x)x = self.pool2(x)x = self.conv3(x)x = F.relu(x)x = self.conv4(x)x = F.relu(x)x = self.conv5(x)x = F.relu(x)x = self.pool3(x)x = paddle.flatten(x,start_axis=1,stop_axis=-1)x = self.linear1(x)x = F.relu(x)x = F.dropout(x,0.5)x = self.linear2(x)x = F.relu(x)x = F.dropout(x,0.5)x = self.linear3(x)return x
def load_data_fashion_mnist(batch_size, resize=None):"""Download the fashion mnist dataset and then load into memory."""trans = []if resize:trans.append(paddle.vision.transforms.Resize(size=resize)) trans.append(paddle.vision.transforms.ToTensor())transform = paddle.vision.transforms.Compose(trans)mnist_train = paddle.vision.datasets.FashionMNIST(mode='train', transform=transform) mnist_test = paddle.vision.datasets.FashionMNIST(mode='test', transform=transform)train_iter = paddle.io.DataLoader(mnist_train,batch_size=batch_size, shuffle=True,places=paddle.CPUPlace())test_iter = paddle.io.DataLoader(mnist_test,batch_size=batch_size, shuffle=False, places=paddle.CPUPlace()) return train_iter , test_iterbatch_size = 128
train_iter, test_iter = load_data_fashion_mnist(batch_size,resize=224)
def train(model):model.train()epochs = 5optim = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())for epoch in range(epochs):for batch_id, data in enumerate(train_iter()):x_data = data[0]y_data = data[1]predicts = model(x_data)loss = F.cross_entropy(predicts, y_data) acc = paddle.metric.accuracy(predicts, y_data) loss.backward()if batch_id % 100 == 0:print("epoch: {}, batch_id: {}, loss is: {}, acc is: {}".format(epoch, batch_id, loss.numpy(), acc.numpy()))optim.step()optim.clear_grad()
model = AlexNet()
train(model)
运行的效果:

四、小结
当然,每个深度学习的框架里可能都有现成的AlexNet模型,我这里之所以选择自己构建一下,主要是出于学习的目的去更好的了解这个模型的一些细节,自我感觉这样更有趣一些。
参考资料:《动手学深度学习》《吴恩达老师视频》








 京公网安备 11010802041100号
京公网安备 11010802041100号