
项目背景
偶然看到了【飞桨论文复现挑战赛】,抱着 划水 提升自己的态度,报名了一个推荐赛道的赛题。因为本身已经参加工作了,实际空闲时间不是太多,只能晚上下班或者周末和各位参赛大佬卷上一卷,划划水~
工欲善其事,必先利其器!在实际推荐算法开发工作中,一般也都有自己的开发项目框架,包含了「数据加载」、「特征处理」、「模型构建」等模块,可以快速完成一个新算法的开发,类似GitHub上开源的DeepCTR包。因此,首先找了一下飞桨的相关套件,所幸飞桨团队开源了PaddleRec飞桨推荐模型库。
工具有了,下面就是比拼对论文的理解了,所以论文复现赛一定要 熟读论文!熟读论文!熟读论文! 重要的事情说3遍.在此前提下,基于PaddleRec复现开发就十分方便了,甚至都不用题目里提到的24小时。下面我们根据复现挑战赛的93号题目DLRM复现进行介绍,主要包括以下几个部分:
DLRM算法原理
PaddleRec介绍
如何基于PaddleRec快速复现
项目总结
参考资料
DLRM算法原理
1.模型结构
DeepLearningRecommendationModelforPersonalizationandRecommendationSystems,DLRM是FaceBook于2019年提出的CTR预估算法,推荐或广告相关同学可以阅读一下原论文,也是非常经典的一篇。
论文链接https://arxiv.org/pdf/1906.00091v1.pdf,
除了DLRM模型本身的经典结构,FaceBook还对线上推断做了非常多的工程方面的优化,感兴趣的同学可以去找一下相关博客。
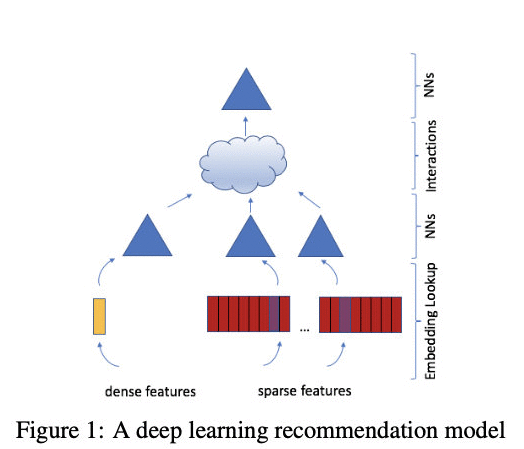
推荐rank模型网络结构一般较为简单,如上图DLRM的网络结构看着和DNN就没啥区别,主要由四个基础模块构成,Embeddings、MatrixFactorization、FactorizationMachine和MultilayerPerceptrons。
DLRM模型的特征输入,主要包括dense数值型和sparse类别型两种特征。
densefeatures直接连接MLP(上图中的蓝色三角形),sparsefeatures经由Embedding层(上图红色模块)查找得到相应的embedding向量.Interactions层(上图云状模块)进行特征交叉,包括densefeatures和sparsefeatures的交叉以及sparsefeatures内部之间的交叉等,该部分与因子分解机FM有些类似。
DLRM模型中所有的sparsefeautres的embedding向量长度均是相等的,且densefeatures经由MLP也转化成相同的维度。这点是理解该模型代码的关键。
总结一下,DLRM模型的步骤如下:
Densefeatures经过MLP(论文中称为bottom-MLP)处理为同样维度的向量;
Sparsefeatures经由lookup获得统一维度的embedding向量(可选择每一个特征对应的embedding是否经过MLP处理);
Densefeatures&sparsefeatures的向量两两之间进行dotproduct交叉;
交叉结果再和dense向量concat一起输入到顶层MLP(top-MLP);
经过sigmoid函数激活得到点击概率。
2.实验部分
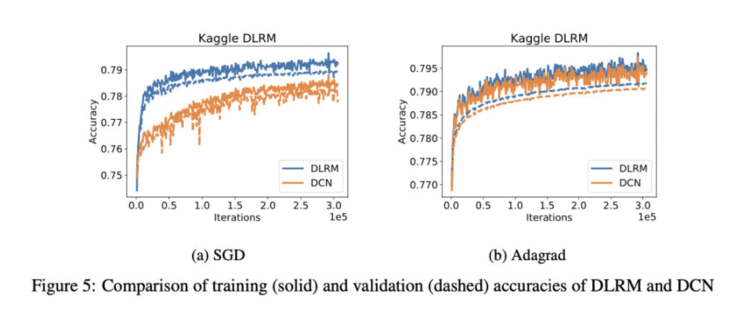
不得不说,Facebook大佬发文章就NB,DLRM网络结构简单干净,没有任何调参,简简单单的SGD+lr=0.1就打败了DCN。原文所说,“DLRMvsDCNwithoutextensivetuningandnoregularizationisused.”太强了!
3.原论文repo
作者原论文开源代码是基于Pytorch实现的,https://github.com/facebookresearch/dlrm,代码逻辑可能有点儿复杂,参考本项目之后再去理解,可能会事半功倍。
4.数据集
原论文采用KaggleCriteo数据集,为常用的CTR预估任务基准数据集。单条样本包括13列densefeatures、26列sparsefeatures及label。
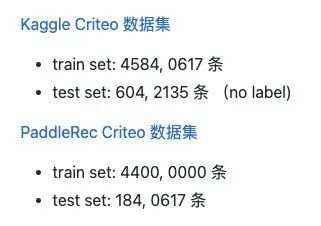
本项目采用PaddleRec所提供的Criteo数据集进行复现。
PaddleRec介绍
PaddleRec涵盖了推荐系统的各个阶段,包括内容理解、匹配、召回、排序、多任务、重排序等,但这里我们只关注CTR预估,即排序阶段.该部分在models/rank/路径下,已经实现了deepfm、dnn、ffm、fm等经典CTR算法,每类算法包含静态图和动态图两种训练方式。我们一般选择动态图复现,因为和PyTorch及Tensorflow2等语法上更接近,调试也更方便。
我们在models/rank/路径下定义dataset加载和模型组网方式之后,便可以通过PaddleRec下tools类进行模型的训练及预测。一个简单的DNN算法训练和推断就是下面简单的两行命令:
# Step 1, 训练模型
python -u tools/trainer.py -m models/rank/dnn/config.yaml
# Step 2, 预测推断
python -u tools/infer.py -m models/rank/dnn/config.yaml
以上trainer.py和infer.py都是PaddleRec预先实现的训练类和预测类,我们不需要关心细节,只需关注数据加载及模型组网等就行,通过上述的配置文件config.yaml去调用我们实现的数据读取类和模型。
|--models|--rank|--dlrm # 本项目核心代码|--data # 采样小数据集|--config.yaml # 采样小数据集模型配置|--config_bigdata.yaml # Kaggle Criteo 全量数据集模型配置|--criteo_reader.py # dataset加载类 |--dygraph_model.py # PaddleRec 动态图模型训练类|--net.py # dlrm 核心算法代码,包括 dlrm 组网等
|--tools # PaddleRec 工具类
总结一下,基于PaddleRecCTR模型快速复现只需要我们在models/rank/路径下,新建自己的模型文件夹,比如我这里的dlrm/.其中,最重要的三个是:
-config.yaml数据、特征、模型等配置
-xxxx_reader.py数据集加载方式
-net.py模型组网
因为DLRM复现要求的是Criteo数据集,甚至这个reader都不用自己去写,PaddleRec帮你做好了。更多关于PaddleRec的介绍,可以参考这里https://github.com/PaddlePaddle/PaddleRec
如何基于PaddleRec
快速复现
上文提到,基于PaddleRec快速复现的关键是net.py模型组网。这里介绍一下net.py代码:
下面实现MLP层,可以看到和PyTorch、Tensorflow2的语法非常接近,几乎可以无缝切换到PaddlePaddle。
官网API文档中有一张映射表,可以参考:PyTorch2PaddlePaddlehttps://www.paddlepaddle.org.cn/documentation/docs/zh/guides/08_api_mapping/pytorch_api_mapping_cn.html
class MLPLayer(nn.Layer):def __init__(self, input_shape, units_list=None, l2=0.01, last_action=None, **kwargs):super(MLPLayer, self).__init__(**kwargs)if units_list is None:units_list = [128, 128, 64]units_list = [input_shape] + units_listself.units_list = units_listself.l2 = l2self.mlp = []self.last_action = last_action
# 堆叠多层 dense 层for i, unit in enumerate(units_list[:-1]):if i != len(units_list) - 1:dense = paddle.nn.Linear(in_features=unit,out_features=units_list[i + 1],weight_attr=paddle.ParamAttr(initializer=paddle.nn.initializer.Normal(std=1.0 / math.sqrt(unit))))self.mlp.append(dense)
# ReLU激活函数relu = paddle.nn.ReLU()self.mlp.append(relu)# BatchNorm加速训练norm = paddle.nn.BatchNorm1D(units_list[i + 1])self.mlp.append(norm)else:dense = paddle.nn.Linear(in_features=unit,out_features=units_list[i + 1],weight_attr=paddle.nn.initializer.Normal(std=1.0 / math.sqrt(unit)))self.mlp.append(dense)if last_action is not None:relu = paddle.nn.ReLU()self.mlp.append(relu)def forward(self, inputs):outputs = inputsfor n_layer in self.mlp:outputs = n_layer(outputs)return outputs
下面是DLRM模型的核心组网,代码中有注释,结合第二部分算法原理很容易理解。
在__init__初始化函数中,定义bottom-MLP模块处理数值型特征,定义Embedding层完成稀疏特征到Embedding向量的映射.定义top-MLP模块处理交叉特征的进一步泛化,得到CTR预测值.
在forward中,对输入的densefeatures和sparsefeatures进行处理,分别得到的embedding向量拼接在一起.经过vector-wise特征交叉后,输入top-MLP得到预测值.
class DLRMLayer(nn.Layer):def __init__(self,dense_feature_dim,bot_layer_sizes,sparse_feature_number,sparse_feature_dim,top_layer_sizes,num_field,sync_mode=None):super(DLRMLayer, self).__init__()self.dense_feature_dim = dense_feature_dimself.bot_layer_sizes = bot_layer_sizesself.sparse_feature_number = sparse_feature_numberself.sparse_feature_dim = sparse_feature_dimself.top_layer_sizes = top_layer_sizesself.num_field = num_field# 定义 DLRM 模型的 Bot-MLP 层self.bot_mlp = MLPLayer(input_shape=dense_feature_dim,units_list=bot_layer_sizes,last_action="relu")# 定义 DLRM 模型的 Top-MLP 层self.top_mlp = MLPLayer(input_shape=int(num_field * (num_field + 1) / 2) + sparse_feature_dim,units_list=top_layer_sizes)# 定义 DLRM 模型的 Embedding 层self.embedding = paddle.nn.Embedding(num_embeddings=self.sparse_feature_number,embedding_dim=self.sparse_feature_dim,sparse=True,weight_attr=paddle.ParamAttr(name="SparseFeatFactors",initializer=paddle.nn.initializer.Uniform()))def forward(self, sparse_inputs, dense_inputs):# (batch_size, sparse_feature_dim)x = self.bot_mlp(dense_inputs)# interact dense and sparse featurebatch_size, d = x.shapesparse_embs = []for s_input in sparse_inputs:emb = self.embedding(s_input)emb = paddle.reshape(emb, shape=[-1, self.sparse_feature_dim])sparse_embs.append(emb)# 拼接数值型特征和 Embedding 特征T = paddle.reshape(paddle.concat(x=sparse_embs + [x], axis=1), (batch_size, -1, d))# 进行 vector-wise 特征交叉Z = paddle.bmm(T, paddle.transpose(T, perm=[0, 2, 1]))Zflat = paddle.triu(Z, 1) + paddle.tril(paddle.ones_like(Z) * MIN_FLOAT, 0)Zflat = paddle.reshape(paddle.masked_select(Zflat,paddle.greater_than(Zflat, paddle.ones_like(Zflat) * MIN_FLOAT)),(batch_size, -1))R = paddle.concat([x] + [Zflat], axis=1)# 交叉特征输入 Top-MLP 进行 CTR 预测y = self.top_mlp(R)return y
本项目DLRM代码已经提交PR,合入到PaddleRec套件中,可以从GitHub上clone代码.源码在PaddleRec/models/rank/dlrm路径中,参考readme.md运行代码。也可以在AIStudio的NoteBook上clone代码,直接上手跑跑看,步骤如下:
-Step1,gitclonecode
-Step2,downloaddata
-Step3,trainmodel&infer
################# Step 1, git clone code ################
# 当前处于 /home/aistudio 目录, 代码存放在 /home/work/rank/DLRM-Paddle 中import os
if not os.path.isdir('work/rank/DLRM-Paddle'):if not os.path.isdir('work/rank'):!mkdir work/rank# 国内访问或 git clone 较慢, 利用 hub.fastgit.org 加速!cd work/rank && git clone https://hub.fastgit.org/Andy1314Chen/DLRM-Paddle.git
################# Step 2, download data ################
# 当前处于 /home/aistudio 目录,数据存放在 /home/data/criteo 中import os
os.makedirs('data/criteo', exist_ok=True)# Download data
if not os.path.exists('data/criteo/slot_test_data_full.tar.gz') or not os.path.exists('data/criteo/slot_train_data_full.tar.gz'):!cd data/criteo && wget https://paddlerec.bj.bcebos.com/datasets/criteo/slot_test_data_full.tar.gz!cd data/criteo && tar xzvf slot_test_data_full.tar.gz!cd data/criteo && wget https://paddlerec.bj.bcebos.com/datasets/criteo/slot_train_data_full.tar.gz!cd data/criteo && tar xzvf slot_train_data_full.tar.gz
################## Step 3, train model ##################
# 启动训练脚本 (需注意当前是否是 GPU 环境, 非 GPU 环境请修改 config_bigdata.yaml 配置中 use_gpu 为 False)
!cd work/rank/DLRM-Paddle && sh run.sh config_bigdata
项目总结
1.基于PaddleRec可以快速进行推荐算法的复现,让你更加专注模型的细节,提升复现效率。
2.PaddleRec提供了通用的训练/推理逻辑,如需增加一些特殊功能,例如,如何提高数据加载速度?如何在训练过程中设置easy_stopping?等。可以直接修改tools/trainer.py和tools/infer.py。
3.有了PaddleRec,论文复现更加强调熟读论文、读懂论文,知道创新点在哪里?核心参数是什么?
参考资料
1.DeepLearningRecommendationModelforPersonalizationandRecommendationSystems,https://arxiv.org/pdf/1906.00091v1.pdf
2.Facebook开源代码
https://github.com/facebookresearch/dlrm
3.PaddleRec
https://github.com/PaddlePaddle/PaddleRec
4.飞桨论文复现打卡营https://aistudio.baidu.com/aistudio/education/group/info/24681

关注公众号,获取更多技术内容~






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 