作者:Pranjal Datta
编译:ronghuaiyang
导读
有很多资料解释了SSIM背后的理论,但很少有资源深入研究细节,本文就是试图填补这一空白的谦虚尝试。
最近,在实现一篇深度估计论文时,我遇到了术语结构相似性指数(SSIM)。SSIM作为度量两个给定图像之间相似度的度量指标。由于这项技术从2004年就开始了,有很多资料解释了SSIM背后的理论,但很少有资源深入研究细节,这对于基于梯度的实现太特别了,因为SSIM经常被用作损失函数。因此,本文就是我试图填补这一空白的谦虚尝试!
本文的目标有两个:
所以让我们开始吧!
理论
SSIM首先在2004年IEEE的论文中被引入,Image Quality Assessment: From Error Visibility to Structural Similarity。
评估感知图像质量的客观方法,传统上试图量化失真图像和参考图像之间的误差(差异)可见性,使用人类视觉系统的各种已知属性。在假设人类视觉感知高度适应于从场景中提取结构信息的前提下,我们引入了一种基于结构信息退化的质量评估替代互补框架。
小结:作者提出了两点要点,
结构相似性指数(SSIM)度量从一幅图像中提取3个关键特征:
两幅图像的比较就是根据这3个特征进行的。
结构相似性度量系统的组织和流程如下图所示。X和Y分别为参考图像和样本图像。

图1: 结构相似性度量系统
这个度量是计算什么呢?
这个系统计算2幅给定图像之间的结构相似度指数,其值在-1到+1之间。值为+1表示两张给定的图像非常相似或相同,值为-1表示两张给定的图像非常不同。这些值通常被调整到范围[0,1],其中极端值具有相同的含义。
现在,让我们简要地探讨一下这些特性是如何用数学表示的,以及它们是如何影响最终的SSIM分数的。
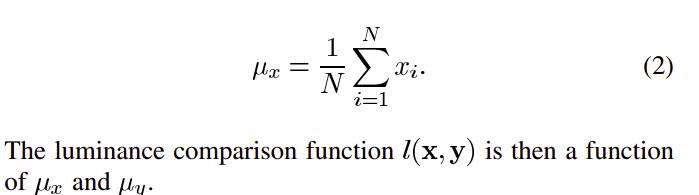
式中,xi为图像x的第i个像素值,N为像素值的总数。
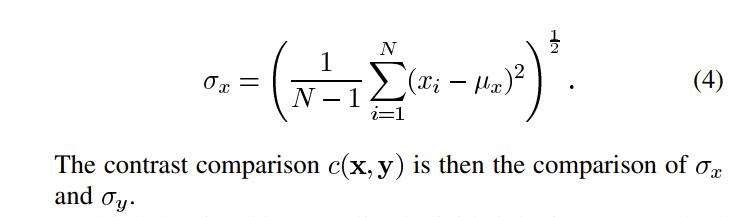
其中x和y为两幅图像,μ为图像像素值的平均值。
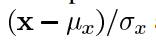
其中x是输入图像。
现在我们已经建立了这三个参数背后的数学直觉。我们还没有完成数学运算,还有一点。我们现在缺少的是比较函数,它可以在这些参数上比较两个给定的图像,最后,一个组合函数,将它们组合在一起。在这里,我们定义了比较函数,最后定义了产生相似性指标值的组合函数。
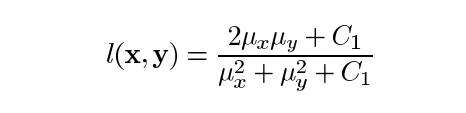
其中C1为常数,保证分母为0时的稳定性。C1这样给出:
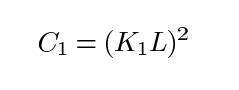
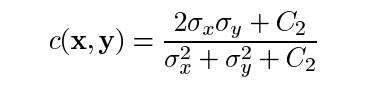
其中C2这样给出:

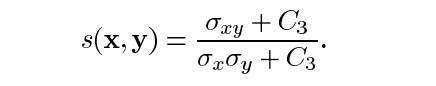
其中σ(xy)定义为:
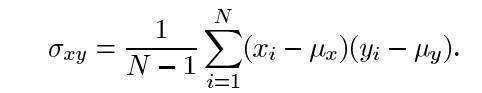
最后,SSIM定义为:
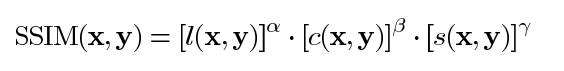
其中 α > 0, β > 0, γ > 0 表示每个度量标准的相对重要性。为了简化表达式,我们设:

现在问题来了!
虽然你可以使用上述公式实现SSIM,但它可能不如已有的现成实现那么好,正如作者解释的那样,
对于图像质量评估,应该局部应用SSIM指数而不是全局应用。首先,图像统计特征通常是高度空间非平稳的。其次,图像失真可能取决于或不取决于局部图像统计,也可能是空间变量。第三,在典型的观测距离下,由于HVS的凹点特征,人眼一次只能看到图像中的具有高分辨率的局部区域。最后,局部质量测量可以提供一个空间变化的图像质量图,它提供了更多关于图像质量退化的信息,在某些应用中可能有用。
总结:与其在全局范围内应用上述度量值(即一次在图像上的所有区域),不如在局部范围内应用这些度量值(即在图像的小部分中,然后取整体的平均值)。
这种方法通常被称为平均结构相似度指数。
由于方法上的这种变化,我们的公式也应该进行修改以反映相同的情况(应该注意的是,这种方法更常见,将用于解释代码)。
(注:如果下面的内容看起来有点难以应付,不用担心!如果你理解了它的要点,那么浏览一下代码会让你更清楚。)
作者使用一个11x11圆对称高斯加权函数(基本上就是一个11x11矩阵,其值来自高斯分布)在整个图像上逐像素移动。在每一步中,在局部窗口内计算局部统计信息和SSIM索引。由于我们现在在局部计算,我们的公式被修改为:
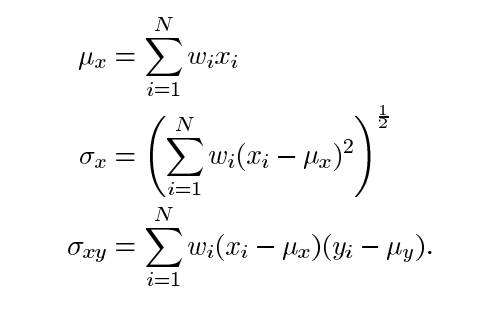
其中wi是高斯加权函数。
如果你觉得这有点不直观,不用担心!可以将wi想象成乘法,并通过一些数学技巧来计算所需的值。
一旦对整个图像进行了计算,我们只需取所有局部SSIM值的平均值,就得到了全局的 SSIM值。
理论终于完成了!现在进入代码!
代码
在深入研究代码之前,需要注意的是,我们不会遍历每行,但是我们将深入研究最基本的那些代码。让我们开始吧!
首先,让我们研究一些执行一些基本任务的函数。
Function #1: gaussian(window_size, sigma)
这个函数本质上是从一个高斯分布中采样的一个数字列表(长度等于window_size)。所有元素的和等于1,值被归一化。Sigma是高斯分布的标准差。
注意:它用于生成上面提到的11x11高斯窗口。
例子:
Code:gauss_dis = gaussian(11, 1.5)
print("Distribution: ", gauss_dis)
print("Sum of Gauss Distribution:", torch.sum(gauss_dis))Output: Distribution: tensor([0.0010, 0.0076, 0.0360, 0.1094, 0.2130, 0.2660, 0.2130, 0.1094, 0.0360,0.0076, 0.0010])Sum of Gauss Distribution: tensor(1.)
Function #2: create_window(window_size, channel)
当我们生成一维高斯张量时,一维张量本身对我们没有用处。因此,我们必须将它转换为一个2D张量(我们之前谈到的11x11张量)。该函数的步骤如下:
Code:window = create_window(11, 3)
print(window.shape)Output:torch.Size([3, 1, 11, 11])
现在我们已经研究了两个函数,让我们看一下主代码!核心的SSIM是通过下面讨论的SSIM()函数实现的。
Function #3: ssim(img1, img2, val_range, window_size=11, window=None, size_average=True, full=False)
在讨论基本内容之前,让我们先看看在计算ssim指标之前函数中发生了什么,
一旦这些步骤完成,我们开始计算各种值,这是得到最终SSIM分数所需要的。
注:由于我们在计算局部统计数据,并且我们需要使其计算更效率,使用的公式有轻微不同。
我们首先计算μ(x),μ(y),它们的平方,以及μ(xy)。这里的channels存储了输入图像的彩色通道的数量。参数的groups用于应用卷积滤波器的所有的输入通道。
channels, height, width = img1.size()mu1 = F.conv2d(img1, window, padding=pad, groups=channels)
mu2 = F.conv2d(img2, window, padding=pad, groups=channels)mu1_sq = mu1 ** 2
mu2_sq = mu2 ** 2mu12 = mu1 * mu2
sigma1_sq = F.conv2d(img1 * img1, window, padding=pad, groups=channels) - mu1_sq
sigma2_sq = F.conv2d(img2 * img2, window, padding=pad, groups=channels) - mu2_s
sigma12 = F.conv2d(img1 * img2, window, padding=pad, groups=channels) - mu12
contrast_metric = (2.0 * sigma12 + C2) / (sigma1_sq + sigma2_sq + C2)contrast_metric = torch.mean(contrast_metric)
numerator1 = 2 * mu12 + C1
numerator2 = 2 * sigma12 + C2
denominator1 = mu1_sq + mu2_sq + C1
denominator2 = sigma1_sq + sigma2_sq + C2ssim_score = (numerator1 * numerator2) / (denominator1 * denominator2)return ssim_score.mean()
代码的执行情况
我们将在三种情况下测试代码,以检查其执行情况。
在第一个场景中,我们对2个非常不同的图像执行SSIM。其中一个是真图像,而另一个是假图像。(既然我们测量的是差异,真伪标签本质上是可以互换的,它们仅被用作参考。)
这些图像是:

假图像(左)真图像(右)
代码如下:
Code: img1 = load_images("img1.jpg")
img2 = load_images("img2.jpg")_img1 = tensorify(img1)
_img2 = tensorify(img2)ssim_score = ssim(_img1, _img2, 225)print(True vs False Image SSIM Score: ", ssim_score)
Output:
True vs False Image SSIM Score: tensor(0.3385)
在这个场景中,我们比较了真实的图像和加了噪声的版本。图像如下所示:

加了噪声的真图像(左),真图像(右)
运行与上面一样的代码:
Code: noise = np.random.randint(0, 255, (640, 480, 3)).astype(np.float32)
noisy_img = img1 + noise_img1 = tensorify(img1)
_img2 = tensorify(noisy_img)true_vs_false = ssim(_img1, _img2, val_range=255)print("True vs Noised True Image SSIM Score:", true_vs_false)Output:True vs Noised True Image SSIM Score: tensor(0.0185)
在最后一种情况下,我们比较真实的图像和它自己。因此,下面显示的图像是与自身进行比较的。如果我们的SSIM代码工作完美,分数应该是**1 **。

在运行下面所示的代码段时,我们可以确认这个给定场景的SSIM得分确实是1。
Code:_img1 = tensorify(img1)
true_vs_false = ssim(_img1, _img1, val_range=255)print("True vs True Image SSIM Score:", true_vs_false)Output:True vs True Image SSIM Score: tensor(1.)
总结
在本文中,我们介绍了SSIM背后的理论和实现它的代码。希望你比我更容易理解SSIM。我试着专注于我个人觉得复杂和难以理解的领域,希望可以不仅巩固我所学到的知识,而且在这个过程中,可以帮助到其他人。

—END—
英文原文:https://medium.com/srm-mic/all-about-structural-similarity-index-ssim-theory-code-in-pytorch-6551b455541e






![[翻译]PyCairo指南裁剪和masking](https://img6.php1.cn/3cdc5/9d74/696/ff5f2ae0c65cf286.jpeg)

 京公网安备 11010802041100号
京公网安备 11010802041100号