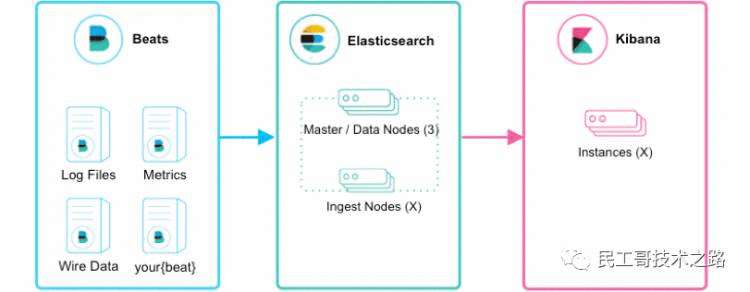
节点是集群中的一个 Elasticearch 实例。 集群是一组拥有共同的 cluster name 的节点。其中一个节点就是一个 ES 进程,多个节点组成一个集群。一般每个节点都运行在不同的操作系统上,配置好集群相关参数后 ES 会自动组成集群。集群内部通过 ES 的选主算法选出主节点,而集群外部则是可以通过任何节点进行操作,无主从节点之分,对外表现对等,去中心化,有利于客户端编程。
索引 Index
索引在ES中索引有两层含义, 作为动词,它指的是把一个文档保存到 ES 中的过程,索引一个文档后,我们就可以使用 ES 搜索到这个文档; 作为名词,它是指保存文档的地方,相当于关系数据库中的database概念,一个集群中可以包含多个索引。
分片 shard
ES 是一个分布式系统,它保存索引时会选择适合的“主分片”(Primary Shard),把索引保存到其中(我们可以把分片理解为一块物理存储区域)。分片的分法是固定的,而且是安装时候就必须要决定好的(默认是 5),后面就不能改变了。
既然有主分片,那肯定是有“从”分片的,在 ES 里称之为“副本分片”(Replica Shard)。副本分片主要有两个作用: 高可用:某分片节点挂了的话可走其他副本分片节点,节点恢复后上面的分片数据可通过其他节点恢复 负载均衡:ES 会自动根据负载情况控制搜索路由,副本分片可以将负载均摊
RESTful支持
ES支持RESTful访问,并且 ES 的 HTTP 接口不只是可以进行业务操作(索引/搜索),还可以进行一些配置等。









 京公网安备 11010802041100号
京公网安备 11010802041100号