作者:我是一颗菠菜 | 来源:互联网 | 2023-09-01 19:04
package SparkStreamingKafKa.OffSetMysql
import java.sql.{DriverManager, ResultSet}
import com.typesafe.config.{Config, ConfigFactory}
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.TopicPartition
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.spark.streaming.kafka010.{HasOffsetRanges, KafkaUtils, LocationStrategies, OffsetRange}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import redis.clients.jedis.Jedis
import scala.collection.mutable
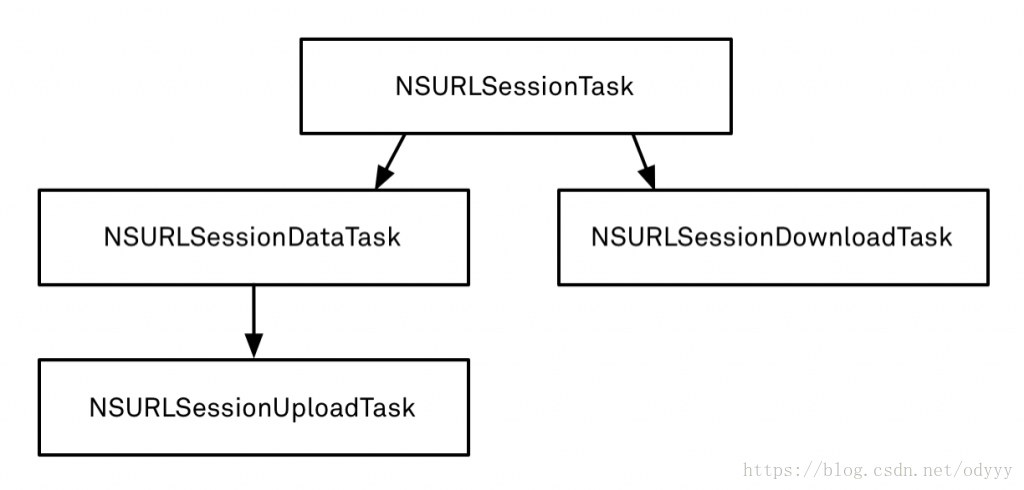
object StreamingKafkaWCMysqlOffset1 {
//设置日志级别
Logger.getLogger("org").setLevel(Level.WARN)
def main(args: Array[String]): Unit = {
//conf 本地运行设置
val conf: SparkCOnf= new SparkConf()
.setMaster("local[*]")
.setAppName(this.getClass.getSimpleName)
//SparkStreaming
val ssc: StreamingCOntext= new StreamingContext(conf, Seconds(3))
val groupId = "hello_topic_group0"
// kafka的参数配置
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "Linux00:9092,Linux01:9092,Linux04:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> groupId,
"auto.offset.reset" -> "earliest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topic = "he8"
val topics = Array(topic)
val config: COnfig= ConfigFactory.load()
// 需要设置偏移量的值
val offsets = mutable.HashMap[TopicPartition, Long]()
val conn1 = DriverManager.getConnection(config.getString("db.url"), config.getString("db.user"), config.getString("db.password"))
val pstm = conn1.prepareStatement("select * from mysqloffset_copy where groupId = ? and topic = ? ")
pstm.setString(1, groupId)
pstm.setString(2, topic)
val result: ResultSet = pstm.executeQuery()
while (result.next()) {
// 把数据库中的偏移量数据加载了
val p = result.getInt("partition")
val f = result.getInt("untilOffset")
// offsets += (new TopicPartition(topic,p)-> f)
val partition: TopicPartition = new TopicPartition(topic, p)
offsets.put(partition, f)
}
val stream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
Subscribe[String, String](topics, kafkaParams,offsets)
)
//转换成RDD
stream.foreachRDD(rdd => {
//手动指定分区的地方
val ranges: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
println("长度=" + ranges.length)
ranges.foreach(println)
val result: RDD[(String, Int)] = rdd.map(_.value()).map((_, 1)).reduceByKey(_ + _)
result.foreach(println)
result.foreachPartition(p => {
val jedis: Jedis = ToolsRedisMysql.getJedis()
p.foreach(t => {
jedis.hincrBy("wc1", t._1, t._2)
})
jedis.close()
})
val cOnn= DriverManager.getConnection(config.getString("db.url"), config.getString("db.user"), config.getString("db.password"))
// 把偏移量的Array 写入到mysql中
ranges.foreach(t => {
// 思考,需要保存哪些数据呢? 起始的offset不需要 还需要加上 groupid
val pstm = conn.prepareStatement("replace into mysqloffset_copy values (?,?,?,?)")
pstm.setString(1, t.topic)
pstm.setInt(2, t.partition)
pstm.setLong(3, t.untilOffset)
pstm.setString(4, groupId)
pstm.execute()
pstm.close()
})
})
ssc.start()
ssc.awaitTermination()
}
}






 京公网安备 11010802041100号
京公网安备 11010802041100号