前言因为一道题目让我不断地深追下去,挖出了我多年的噩梦——数据类型的范围与长度。每次都想得头痛,因为平台不同、编译器不同、编程语言不同等等因素,又没去做实验,网上那么多说法该相信谁
前言
因为一道题目让我不断地深追下去,挖出了我多年的噩梦——数据类型的范围与长度。每次都想得头痛,因为平台不同、编译器不同、编程语言不同等等因素,又没去做实验,网上那么多说法该相信谁都不知道……那不如趁现在就来详细地解决掉它吧。
一、原码、反码和补码
基础知识
相信在大学的《数字逻辑》课上都学过这个内容了,原码、反码和补码都是基于二进制而言的:
【原码】第1位表示符号位,其余位是这个数的绝对值。这是最简单能够马上想到的表示方式了。
【反码】正数的反码是其本身;负数的反码:在原码的基础上,符号位不变,其余位取反。
【补码】正数的补码是其本身;负数的补码:在原码的基础上,符号位不变,其余位取反,最后+1。
举个例子,假设整数在机器上是用8位二进制数表示的(8位就和我们经常说的32位、64位是一样的含义):

为什么要用原码、反码和补码呢?
原码的来源
为了让二进制能够表示负数,产生了原码。
反码的来源
一个正数和一个负数运算需要辨别符号位,然而单独去辨别符号位会给电路设计带来极大的复杂度,因此人们想只设计加法电路,让符号位直接参与加法运算达到减法的目的,产生了反码。例如:3-2 = 3+(-2) = [0000 0011]反+[1111 1101]反 = [0000 0001]反 = [0000 0001]原=1(注意反码的加法当最高位进位的时候,最低位需要+1,不再详细描述,参考百度百科《二进制反码求和》)。这样符号位就能够参与运算了。
补码的来源
反码看起来很完美,但是仍然存在问题。例如3-3 = 3+(-3) = [0000 0011]反+[1111 1100]反 = [1111 1111]反 = [1000 0000]原=-0,而[0000 0000]反=[0000 0000]原 = +0,也就是说,零可以表示为两种形式,这种歧义同样不利于电路实现。并且由于反码的加减法还需要对溢出位进行处理,于是产生了补码。补码对溢出位直接丢弃,而0的表示只有一种[0000 0000]补,[1000 0000]补则看成是-128,解决了所有问题。
原码、反码和补码的范围问题
值得注意的是,8位的原码和反码都只能表示[-127, +127]范围内的整数,而补码可以表示[-128, +127]范围,多一个-128。这里的-128是计算得到的,而不是从反码推出的,-128根本无法用反码表示,却能够用补码计算,比如-127+(-1) = [1000 0001]补+[1111 1111]补 = [1000 0000]补。所以我们经常背的整数取值范围[-32768, +32767]之类的东西为什么负数总比整数的真值大1,就是这样来的。
计算机中按位取反会发生什么?
既然计算机表示的时候用的是补码,那么如果对十进制的整数【按位取反】操作到底操作的是补码还是二进制呢?
实验一下吧:
printf("%d\n", ~(3));
printf("%d\n", ~(-3));
【平台】windows 8 64位
【IDE】vs2013 32位
【语言】C语言
【取反操作】~
【取反结果】~3 = -4,~(-3) = 2
数值比较小,最高位没有影响,就按照8位来仔细观察第一组数据:
3 = [0000 0011]b = [0000 0011]原 = [0000 0011]反 = [0000 0011]补
-4 = [无法表示]b = [1000 0100]原 = [1111 1011]反 = [1111 1100]补
对补码取的反,再来看第二组:
-3 = [无法表示]b = [1000 0011]原 = [1111 1100]反 = [1111 1101]补
2 = [0000 0010]b = [0000 0010]原 = [0000 0010]反 = [0000 0010]补
可以确信100%是对补码取的反了,纯的。
二、C语言中的整数类型的大小和范围
以前我们常常会去记忆[-32767, +32768],尤其是在学pascal的时候,然而现在仔细想想,pascal都是多少年前的编程语言了,那时的电脑和现在的电脑完全不相同,记这个根本没用。整数类型的大小和范围和操作系统、编译器、编程语言都息息相关,抛开运行环境谈论sizeof出什么结果的题目都是耍流氓,然而笔试题这种流氓经常存在………
整数类型的范围与表示位数
用不同位数表示整数,取值的范围就不相同,由于采用补码,总可以多表示一个负数:
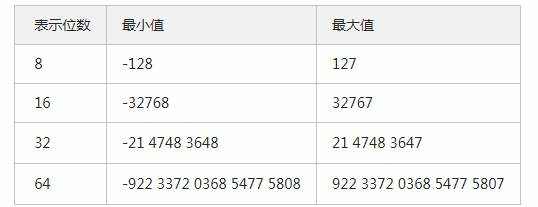
无符号unsigned
无符号的时候,就可以不用担心符号位了,也就是可以表示0~2^bit-1个数,比如:
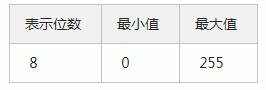
![]()
C语言中的整数类型及其长度
基本整数类型有:char、short int、int、long、long long(c99新增)。
我总是在死记长度,总以为long比int更长,但其实C语言标准是这样规定的:
int最少16位(2字节),long不能比int短,short不能比int长,具体位长由编译器开发商根据各种情况自己决定。
好一个“自己决定”……好一个“不能比”……还是通常情况吧,列个表:
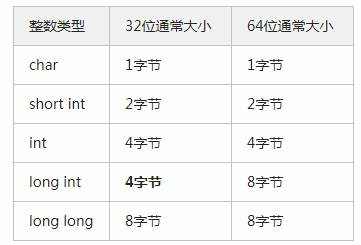
![]()
32位表示方式中,long int和int是一样大的!同时还反映了一个问题:64位运行的代码不一定能在32位上运行。
C语言数据类型名称、输出和编译器的关系
g++和gcc
g++把.c和.cpp程序都认为是c++程序,gcc则会用C语言的方式编译.c,用C++的方式编译.cpp。也就是说,如果你用C写的程序,用g++编译,很可能会报语法错误,因为g++对语法要求更严格,尽管C++是C语言的超集。其他的区别就是,g++能够自动链接c++的库,而gcc需要手动设置参数。
gcc/g++与cl
vs使用的编译器是cl.exe,这是微软自己开发的编译器。CL.exe是控制 Microsoft C 和 C++ 编译器与链接器的 32 位工具。cl和clang是不同的,在Visual Studio 2015已经整合了clang编译器,但它是被用于Android和 iOS上的应用开发。
整数类型不同表示方式以及输出
Visual Studio是在windows下运行的,通常支持__intxx这种写法来定义不同位数的整数,这是gcc/g++通常不支持的(没有实验过)。而long long这种写法在Visual C++ 6.0上是不支持的(没有实验过)。不过,在Visual Studio 2013上,全部的写法都支持,很可靠,列个表:

![]()
并且,所有的printf写法都支持:
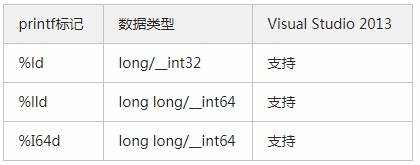
![]()
做个实验:
【操作系统】windows 8 64位
【IDE】Microsoft Visual Studio 2013 32位
【编译器】cl.exe win32
【代码】
long long a = 1231321313131313131;
__int64 b = 1231321313131313131;
printf(" type=long long\n d=%d\n ld=%ld\n lld=%lld\n I64d=%I64d\n ---\n", a,a,a,a);
printf(" type=__int64\n d=%d\n ld=%ld\n lld=%lld\n I64d=%I64d\n", b,b,b,b);
【输出结果】
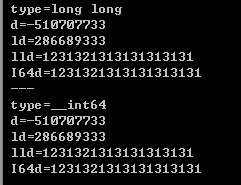
![]()
d和ld都溢出了,而lld、I64d可以工作得很好,而且对long long 和__int64没有任何区别
整数类型越界会发生什么?
这是一直都很好奇的事情,那就来实验一下。
【操作系统】windows 8 64位
【IDE】Microsoft Visual Studio 2013 32位
【编译器】cl.exe win32
【实验结果】
- 取值范围
- unsigned short int 0~65535
- unsigned int 0~4294967295
- int -2147483648~2147483647
- long -2147483648 ~ 2147483647
- long long -9223372036854775808 ~ 9223372036854775807
- 超上限(越来越大)会从最小值开始重新增长:
- unsigned short int 65536=0 | 65537= 1
- unsigned int 4294967296=0 | 4294967297= 1
- int 2147483648=-2147483648 | 2147483649 = -2147483647
- long 2147483648=-2147483648 | 2147483649 = -2147483647
- long long 9223372036854775808 = -9223372036854775808 | 9223372036854775809 = -9223372036854775807
- 超下限(越来越小)会从最大值开始重新减小:
- unsigned short int -1=65535 | -2=65534
- unsigned int -1=4294967295 | -2=4294967294
- int -2147483649=2147483647 | -2147483650=2147483646
- long -2147483649=2147483647 | -2147483650=2147483646
- long long -9223372036854775809 = -9223372036854775807 | 9223372036854775810 = -9223372036854775806
【探究原因】
想一下刚才的补码,假设32位,int取最大值2147483647,打开你的计算器,选择查看→程序员,输入这个数字,看到它的补码:
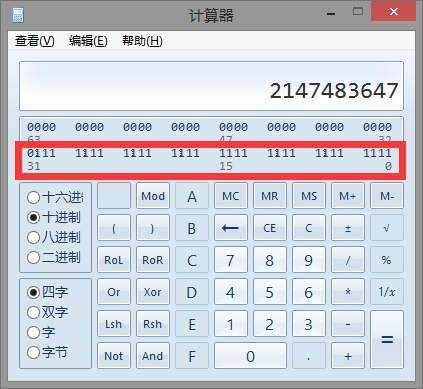
[0111 1111 1111 1111 1111 1111 1111 1111]补 + [0000 0000 0000 0000 0000 0000 0000 0001]补的结果是[1000 0000 0000 0000 0000 0000 0000 0000]补 = -2147483648。
这就是为什么越界的2147483648,打印输出-2147483648的原因了。
【其他】
注意如果你直接进行赋值:
int a = -2147483648;
VS是会报错的:
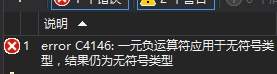
![]()
long long 也是如此,因此这时候应该用:
int a = INT_MIN;
long long b = LLONG_MIN;
来表示,可以看到它们的宏定义:
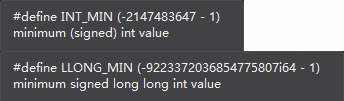
![]()
说好的可以多表示一个负数呢,怎么不行了呢,具体原因参考wiki《VS编写C程序报错error C4146: 一元负运算符应用于无符号类型,结果仍为无符号类》
三、JAVA语言中的整数类型的大小和范围
基本信息
因为我在尽量主学Java副学Python,所以这里也记录一下java的整数类型。java的整数类型比较神奇,有四种基本整数类型:byte、short、int、long,但由于java的设计初衷是跨平台运行的,Write Once and Run Anywhere,所以这几种类型的字长都是固定的,与任何其他的32位64位都无关,列个表:
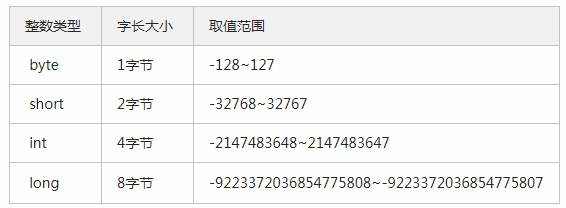
你可以自己测试一下:
System.out.println("Byte: " + Byte.SIZE/8);
System.out.println("Short: " + Short.SIZE/8);
System.out.println("Integer: " + Integer.SIZE/8);
System.out.println("Long: " + Long.SIZE/8);
java中的unsigned类型
java是几乎没有unsigned类型的。为什么说几乎呢,因为在多年的呼吁之后,最新的jdk8支持了unsigned的静态方法调用(也就是说不支持直接写unsigned int这种写法,只能通过Integer.xxxx来调用),参看《Unsigned Integer Arithmetic API now in JDK 8》。真应了那句老话:真香!为什么大家那么希望有unsigned类型呢?因为常常需要处理图片,而我们知道通常的图片数据是从0变化到255的,如果有unsigned byte,那不就刚好了嘛~由于没有unsigned,目前主流的做法是使用更大的类型比如short或者int。值得注意的是,如果要把表达0~255取值的byte转换到short/int,要处理一下符号。因为当从0~255的short/int转换为byte时,考虑他们的补码,例如255:
255 = short [0000 0000 1111 1111]补 → byte [1111 1111]补 = -1
128 = short [0000 0000 1000 0000]补 → byte[1000 0000]补 = -128
0 = short [0000 0000 0000 0000]补 → byte[0000 0000]补 = 0
127 = short[0000 0000 0111 1111]补 → byte[0111 1111]补 = 127
可以看出,0~127(short)被映射到0~127(byte),而128~255则被映射到(-128~-1)了,因此在byte转回short/int时,如果不加处理,得到的值会是-128:
-128 = byte[1000 0000]补 → short [1111 1111 1000 0000]补 = -128
处理的方法很简单,加个掩码0xff屏蔽掉高位的符号扩展即可,也就是将byte的值与0xff进行按位与:
-128 & 0xff = byte[1000 0000]补 & [1111 1111] → short[1111 1111 1000 0000]补 & [0000 0000 1111 1111] = [0000 0000 1000 0000]补 = 128
得到的值就正常了,用代码实验一下:
short s_init = 128,s_force,s_and;
byte b_force;
b_force = (byte)s_init;
s_force = (short)b_force;
s_and = (short)(b_force & 0xFF);
System.out.println("初始short值= "+s_init+"\n转为byte= "+b_force+"\nbyte转为short= "+s_force+"\nbyte掩码后转为short= "+s_and);
得到的结果是:
初始short值= 128
转为byte= -128
byte转为short= -128
byte掩码后转为short= 128
java中的char
char类型长度2个字节,而且取值是无符号的0~65535,其他编程语言通常都是1个字节。java的char是Unicode编码,可以存放中文字符。那么为什么不用它来作为unsigned int 用呢?
【原因1】输出为字符。
java的char类型是设计为存储unicode字符的,采用UTF-16固定宽度的编码格式。虽然赋值的是数值88,但当调用System.out.println(a);的时候,出现的是字母X。
【原因2】运算困难。
char a = 88;
a = a + 1;
编译器会报错需要char类型,而给的是int,因为当char类型运算后就是int类型了,不能直接存回char类型,需要进行强制转换:
a = (char)(a + 1);
既然这么麻烦,为何不直接用int呢?
java中整数类型越界会发生什么?
和C语言是一样的:当越上界,会从最小值继续累加;当越下界,会从最大值继续减小。原因同样是因为补码溢出位被丢弃,在测试的时候,不能直接赋值越界数值,否则会提示类型不匹配或者整数太大了。使用常量+1再强制转换类型,达到越界目的。
byte a = (byte)(Byte.MAX_VALUE+1);
输出结果:-128
作者:三颗豆子
链接:
简单又复杂的“整数类型” | 文章 | BEWINDOWEB
—————–
还没关注我的公众号?
扫文末二维码关注公众号【轮子工厂】,回复“领取资源”可领取如下学习资料:
1T视频教程:涵盖Javaweb前后端教学视频、机器学习/人工智能教学视频、Linux系统教程视频、雅思考试视频教程;
100多本书:包含C/C++、Java、Python三门编程语言的经典必看图书、LeetCode题解大全;
软件工具:几乎包括你在编程道路上的可能会用到的大部分软件;
项目源码:20个JavaWeb项目源码。










 京公网安备 11010802041100号
京公网安备 11010802041100号