一,STL
1> STL中数据结构常见操作
- a.assign(b.begin(), b.begin()+3); //b为向量,将b的0~2个元素构成的向量赋给a
- a.assign(4,2); //是a只含4个元素,且每个元素为2
- a.back(); //返回a的最后一个元素
- a.front(); //返回a的第一个元素
- a[i]; //返回a的第i个元素,当且仅当a[i]存在2013-12-07
- a.clear(); //清空a中的元素
- a.empty(); //判断a是否为空,空则返回ture,不空则返回false
- a.pop_back(); //删除a向量的最后一个元素
- a.erase(a.begin()+1,a.begin()+3); //删除a中第1个(从第0个算起)到第2个元素,也就是说删除的元素从a.begin()+1算起(包括它)一直到a.begin()+ 3(不包括它)
- a.push_back(5); //在a的最后一个向量后插入一个元素,其值为5
- a.insert(a.begin()+1,5); //在a的第1个元素(从第0个算起)的位置插入数值5,如a为1,2,3,4,插入元素后为1,5,2,3,4
- a.insert(a.begin()+1,3,5); //在a的第1个元素(从第0个算起)的位置插入3个数,其值都为5
- a.insert(a.begin()+1,b+3,b+6); //b为数组,在a的第1个元素(从第0个算起)的位置插入b的第3个元素到第5个元素(不包括b+6),如b为1,2,3,4,5,9,8 ,插入元素后为1,4,5,9,2,3,4,5,9,8
- a.size(); //返回a中元素的个数;
- a.capacity(); //返回a在内存中总共可以容纳的元素个数
- a.resize(10); //将a的现有元素个数调至10个,多则删,少则补,其值随机
- a.resize(10,2); //将a的现有元素个数调至10个,多则删,少则补,其值为2
- a.reserve(100); //将a的容量(capacity)扩充至100,也就是说现在测试a.capacity();的时候返回值是100.这种操作只有在需要给a添加大量数据的时候才 显得有意义,因为这将避免内存多次容量扩充操作(当a的容量不足时电脑会自动扩容,当然这必然降低性能)
- a.swap(b); //b为向量,将a中的元素和b中的元素进行整体性交换
- a==b; //b为向量,向量的比较操作还有!=,>=,<=,>,<
- sort(a.begin(),a.end()); //对a中的从a.begin()(包括它)到a.end()(不包括它)的元素进行从小到大排列
- reverse(a.begin(),a.end()); //对a中的从a.begin()(包括它)到a.end()(不包括它)的元素倒置,但不排列,如a中元素为1,3,2,4,倒置后为4,2,3,1
- copy(a.begin(),a.end(),b.begin()+1); //把a中的从a.begin()(包括它)到a.end()(不包括它)的元素复制到b中,从b.begin()+1的位置(包括它)开 始复制,覆盖掉原有元素
- find(a.begin(),a.end(),10); //在a中的从a.begin()(包括它)到a.end()(不包括它)的元素中查找10,若存在返回其在向量中的位置
2>优先队列
大根堆声明方式:
大根堆就是把大的元素放在堆顶的堆。优先队列默认实现的就是大根堆,所以大根堆的声明不需要任何花花肠子,直接按C++STLC++STL的声明规则声明即可
#include
priority_queue q;
priority_queue q;
priority_queue > q;//pair类型放入优先队列中总是先比较first的大小 //相同在比较second的大小
小根堆声明方式
priority_queue
重载运算符
语法格式:
<返回类型> operator <运算符符号>(<参数>)
{
<定义>;
}
例如:
struct node
{
int id;
double x,y;
}//定义结构体
bool operator <(const node &a,const node &b)
{
return a.x3>bitset
bitsetbitset容器概论
bitsetbitset容器其实就是个01串。可以被看作是一个bool数组。它比bool数组更优秀的优点是:节约空间,节约时间,支持基本的位运算。在bitset容器中,8位占一个字节,相比于bool数组4位一个字节的空间利用率要高很多。同时,n位的bitset在执行一次位运算的复杂度可以被看作是n/32.
bitset容器的声明
因为bitset容器就是装01串的,所以不用在<>中装数据类型,这和一般的STL容器不太一样。<>中装01串的位数。
如:(声明一个1e5位的bitset)
bitset<100000> s;
常用的操作函数
- count()函数
它的作用是数出1的个数。
s.count();
- any()/none()函数
如果,bitset中全都为0,那么s.any()返回false,s.none()返回true。
反之,假如bitset中至少有一个1,即哪怕有一个1,那么s.any()返回true,s.none()返回false.
s.any();
s.none();
- set()函数
set()函数的作用是把bitset全部置为1.
特别地,set()函数里面可以传参数。set(u,v)的意思是把bitset中的第u位变成v,v∈0/1。
s.set();
s.set(u,v);
- reset()函数
与set()函数相对地,reset()函数将bitset的所有位置为0。而reset()函数只传一个参数,表示把这一位改成0。
s.reset();
s.reset(k);
- flip()函数
flip()函数与前两个函数不同,它的作用是将整个bitset容器按位取反。同上,其传进的参数表示把其中一位取反。
s.flip();
s.flip(k);
**PS:bitset能直接进行位运算,如:&,|,^,<<,>>,==/!= **
二,链表
1>链式前向星(邻接表)
struct Edge
{
int nex, to;
} e[N <<1];
void add(int u, int v)
{
e[++cnt].nex = head[u];
head[u] = cnt;
e[cnt].to = v;
}
2>舞蹈链
解决一类精确覆盖问题
模板题目为:给定一个N行M列的矩阵,矩阵中每个元素要么是1,要么是0
你需要在矩阵中挑选出若干行,使得对于矩阵的每一列j,在你挑选的这些行中,有且仅有一行的第j个元素为1
#include
using namespace std;
#define re register int
#define ull unsigned long long
#define ll long long
#define inf 0x3f3f3f3f
#define N 1000010
#define mod 114514
#define lson rt <<1
#define rson rt <<1 | 1
inline ll read()
{
ll x=0,f=1;char ch=getchar();
while (ch<\'0\'||ch>\'9\') {if (ch==\'-\') f=-1; ch=getchar();}
while (ch>=\'0\' && ch <= \'9\') { x=(x<<1) + (x<<3) + (ll)ch-\'0\';ch=getchar();}
return x*f;
}
int n, m, ans[1100],a[1100],l[250010],r[250010],las[1100];
int up[250010],down[250010],row[250010],col[250010];
int cnt,siz[1100];
void newlr(int u)
{
r[l[u]]=l[r[u]]=u;
}
void newud(int u)
{
down[up[u]]=up[down[u]]=u;
}
void dellr(int u)
{
r[l[u]]=r[u];
l[r[u]]=l[u];
}
void delud(int u)
{
up[down[u]]=up[u];
down[up[u]]=down[u];
}
void link(int lef,int rr,int uu,int dd,int rw,int dw)
{
l[cnt]=lef; r[cnt]=rr;
up[cnt]=uu; down[cnt]=dd;
row[cnt]=rw; col[cnt]=dw;
}
void prep(int x)
{
l[0]=r[0]=up[0]=down[0]=0;
for (int i=1; i <= x; i++)
{
siz[i]=0;
las[i]=i;
cnt++;
link(i-1,r[i-1],i,i,0,i);
newlr(i);
}
}
void add(int rw)
{
if (a[0] == 0) return ;
cnt++;
link(cnt,cnt,las[a[1]],down[las[a[1]]],rw,a[1]);
newud(cnt);
siz[a[1]]++;las[a[1]]=cnt;
for (int i=2;i<=a[0];i++)
{
cnt++;
link(cnt-1,r[cnt-1],las[a[i]],down[las[a[i]]],rw,a[i]);
newlr(cnt);newud(cnt);
siz[a[i]]++;las[a[i]]=cnt;
}
}
void del(int x)//因为节点序号1-m的节点的行数都为0,即虚拟节点,左右只用删除一次
{
dellr(x);
for (int i=up[x];i!=x;i=up[i])
{
for (int j=l[i];j!=i;j=l[j])
delud(j),siz[col[j]]--;
}
}
void back(int x)
{
newlr(x);
for (int i = up[x]; i!=x; i = up[i])
{
for (int j = l[i]; j!=i; j = l[j])
newud(j),siz[col[j]]++;
}
}
int dance(int step)
{
if (!r[0])
{
for (int i=0;i 3>ST表
区间查询,O(1),不能修改
区间最大值模板:
int main()
{
n=read(),Q=read();
for (int i=1;i<=n;i++) f[i][0]=read();
for (int j=1;j<=18;j++)
for (int i=1;i+(1<4>并查集
-
普通并查集
#includeusing namespace std; int n, m, z, x, y, fa[100010]; int getfa(int x) { return x == fa[x] ? x : fa[x] = getfa(fa[x]); } int main() { scanf("%d%d", &n, &m); for (int i = 1; i <= n; i++) fa[i] = i; for (int i = 1; i <= m; i++) { scanf("%d%d%d", &z, &x, &y); if (z == 1) { fa[getfa(x)] = getfa(y); } else { if (getfa(x) == getfa(y)) puts("Y"); else puts("N"); } } return 0; } -
带权并查集
与普通并查集相比,在递归前加了一步赋值操作
带权并查集图示为:
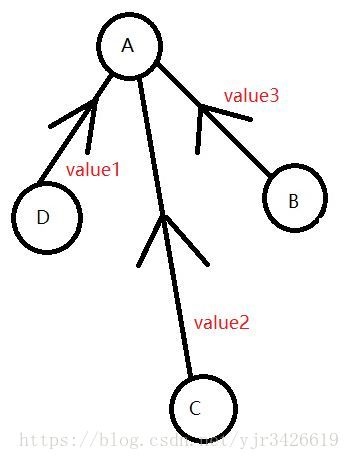
它的每一条边都记录了每个节点到根节点的一个权值,这个权值该设为什么由具体的问题而定,一般都是两个节点之间的某一种相对的关系
查询:
int getfa(int x)
{
if (x != dad[x])
{
int t = dad[x];
dad[x] = getfa(dad[x]);
value[x] += value[t];
}
return dad[x];
}
合并:
int px = getfa(x);
int py = getfa(y);
if (px != py)
{
dad[px] = py;
value[px] = -value[x] + value[y] + s;
}
3.种类并查集
维护一类“朋友的朋友是朋友,朋友的敌人是敌人,敌人的敌人是朋友”的关系,一般用拆点
经典例题1:食物链
动物王国中有三类动物A,B,C,这三类动物的食物链构成了有趣的环形。A吃B, B吃C,C吃A。
现有N个动物,以1-N编号。每个动物都是A,B,C中的一种,但是我们并不知道它到底是哪一种。
有人用两种说法对这N个动物所构成的食物链关系进行描述:
第一种说法是"1 X Y",表示X和Y是同类。
第二种说法是"2 X Y",表示X吃Y。
此人对N个动物,用上述两种说法,一句接一句地说出K句话,这K句话有的是真的,有的是假的。当一句话满足下列三条之一时,这句话就是假话,否则就是真话。
1) 当前的话与前面的某些真的话冲突,就是假话;
2) 当前的话中X或Y比N大,就是假话;
3) 当前的话表示X吃X,就是假话。
你的任务是根据给定的N(1 <= N <= 50,000)和K句话(0 <= K <= 100,000),输出假话的总数。
int n,k,dad[5000050],ans;
int getf(int x)
{
return x==dad[x]?x:dad[x]=getf(dad[x]);
}
int main()
{
scanf("%d%d",&n,&k);
for (int i=1;i<=500100;i++) dad[i]=i;
while (k--)
{
int a,b,ty;
scanf("%d%d%d",&ty,&a,&b);
int aa=a+n,bb=b+n;
int aaa=a+2*n,bbb=b+2*n;
if (a>n||b>n)
{
ans++;
continue;
}
if (ty==1)
{
if (getf(aa)==getf(b)||getf(aaa)==getf(b))
{
ans++;
continue;
}
dad[getf(a)]=getf(b);
dad[getf(aa)]=getf(bb);
dad[getf(aaa)]=getf(bbb);
}
if (ty==2)
{
if (a==b)
{
ans++;
continue;
}
if (getf(a)==getf(b)||getf(aaa)==getf(b))
{
ans++;
continue;
}
dad[getf(a)]=getf(bbb);
dad[getf(aa)]=getf(b);
dad[getf(aaa)]=getf(bb);
}
}
printf("%d",ans);
return 0;
}








 京公网安备 11010802041100号
京公网安备 11010802041100号