作者:皇家冷情绪 | 来源:互联网 | 2023-08-23 18:24
基于scrapy-redis的通用分布式爬虫框架-spiderman基于scrapy-redis的通用分布式爬虫框架项目地址github.comTurboWaysp…
spiderman




基于 scrapy-redis 的通用分布式爬虫框架
项目地址 github.com/TurboWay/sp…
目录
-
效果图
- 采集效果
- 爬虫元数据
- 分布式爬虫运行
- 单机爬虫运行
- 附件下载
- kafka实时采集监控示例
-
介绍
-
快速开始
- 下载安装
- 如何开发一个新爬虫
- 如何进行补爬
- 如何下载附件
- 如何扩展分布式爬虫
- 如何管理爬虫元数据
- 如何配合kafka做实时采集监控
- 如何使用爬虫api
-
其它
demo采集效果
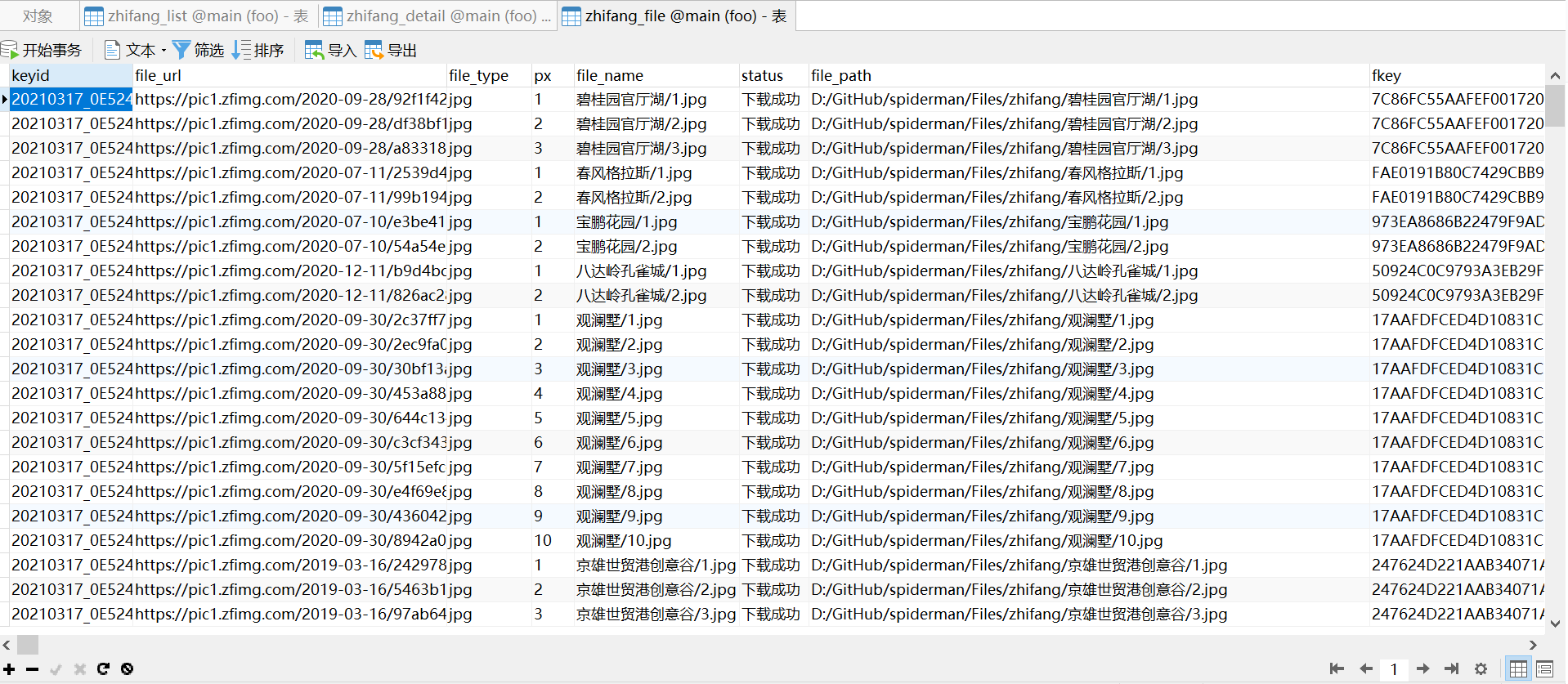
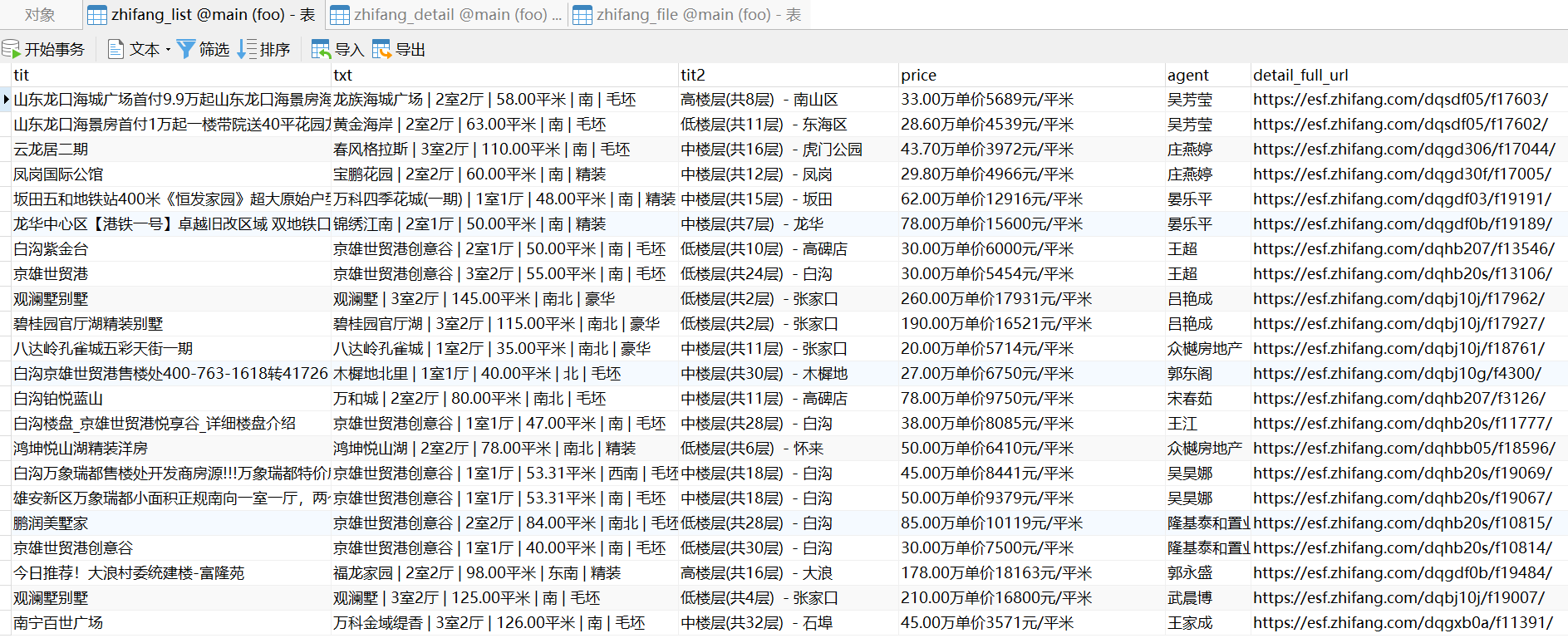
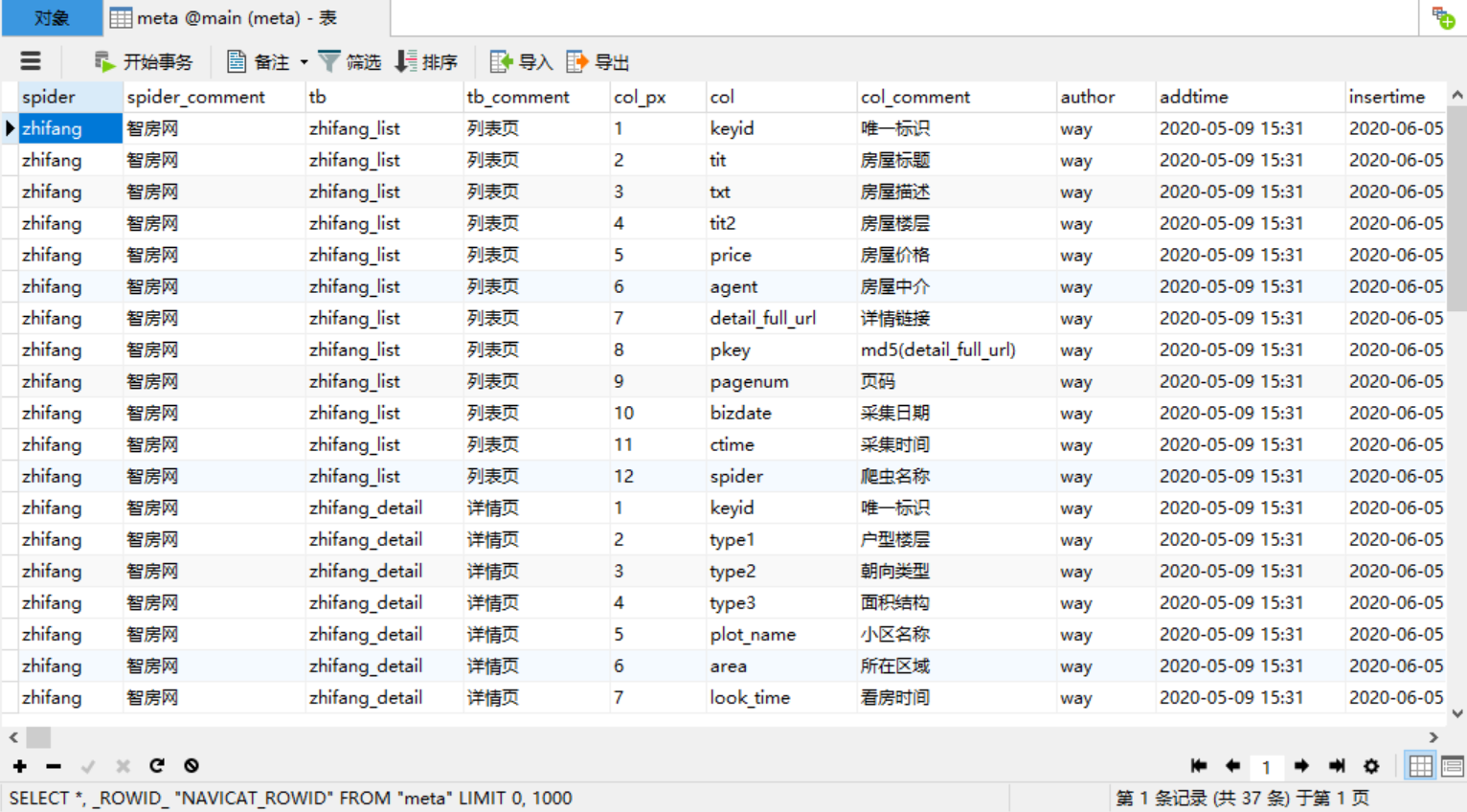
爬虫元数据
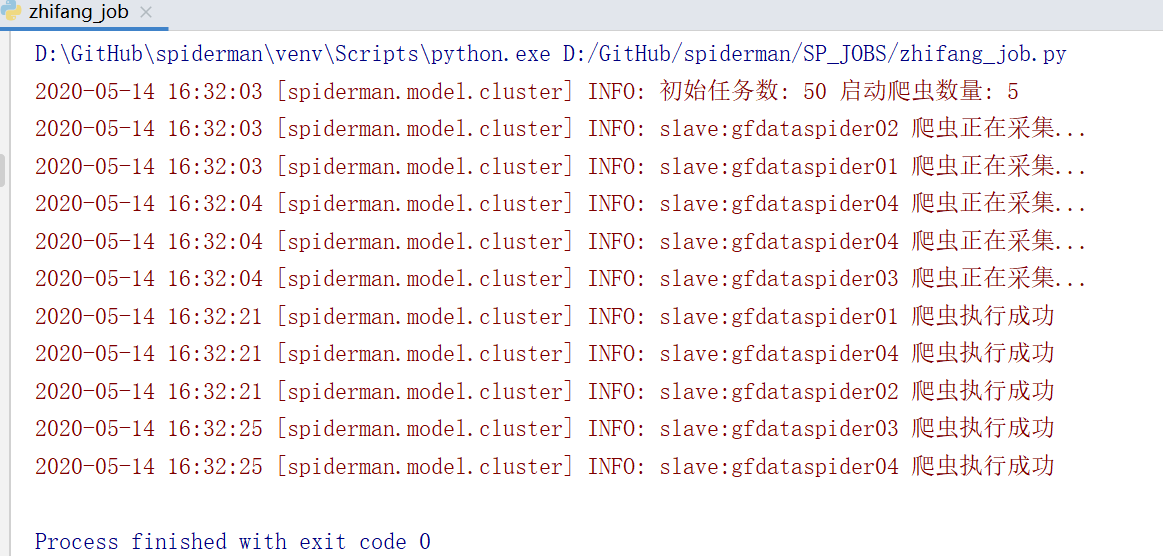
cluster模式
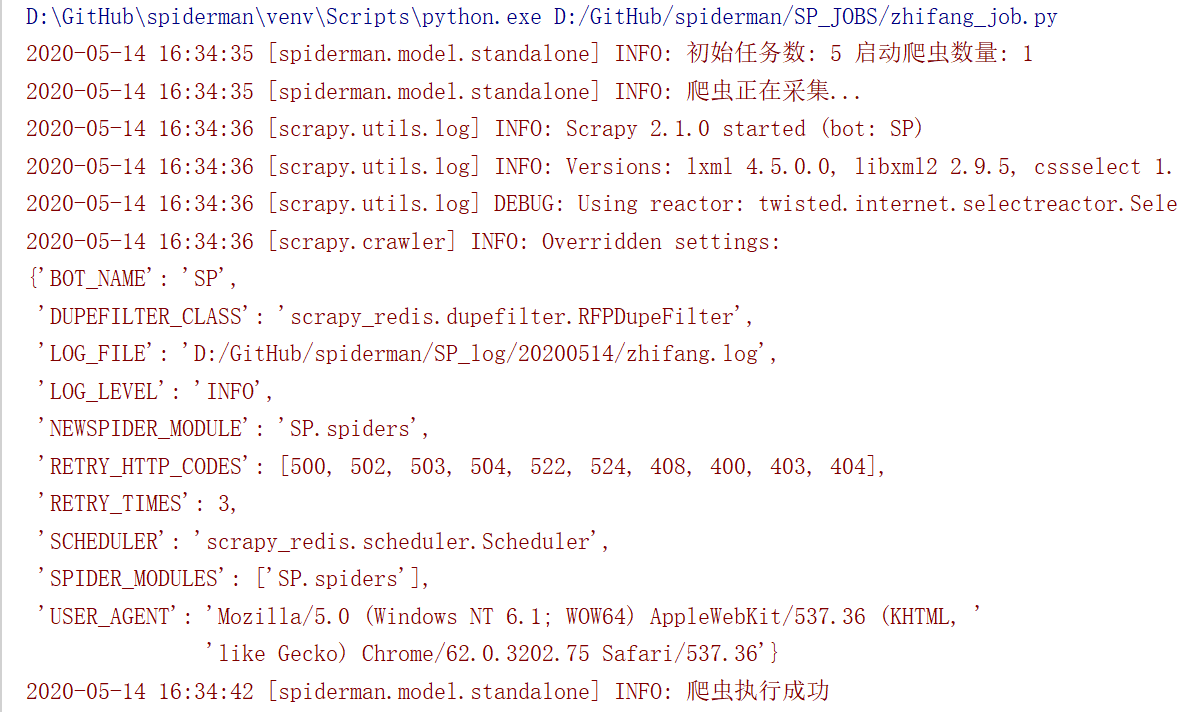
standalone模式
附件下载

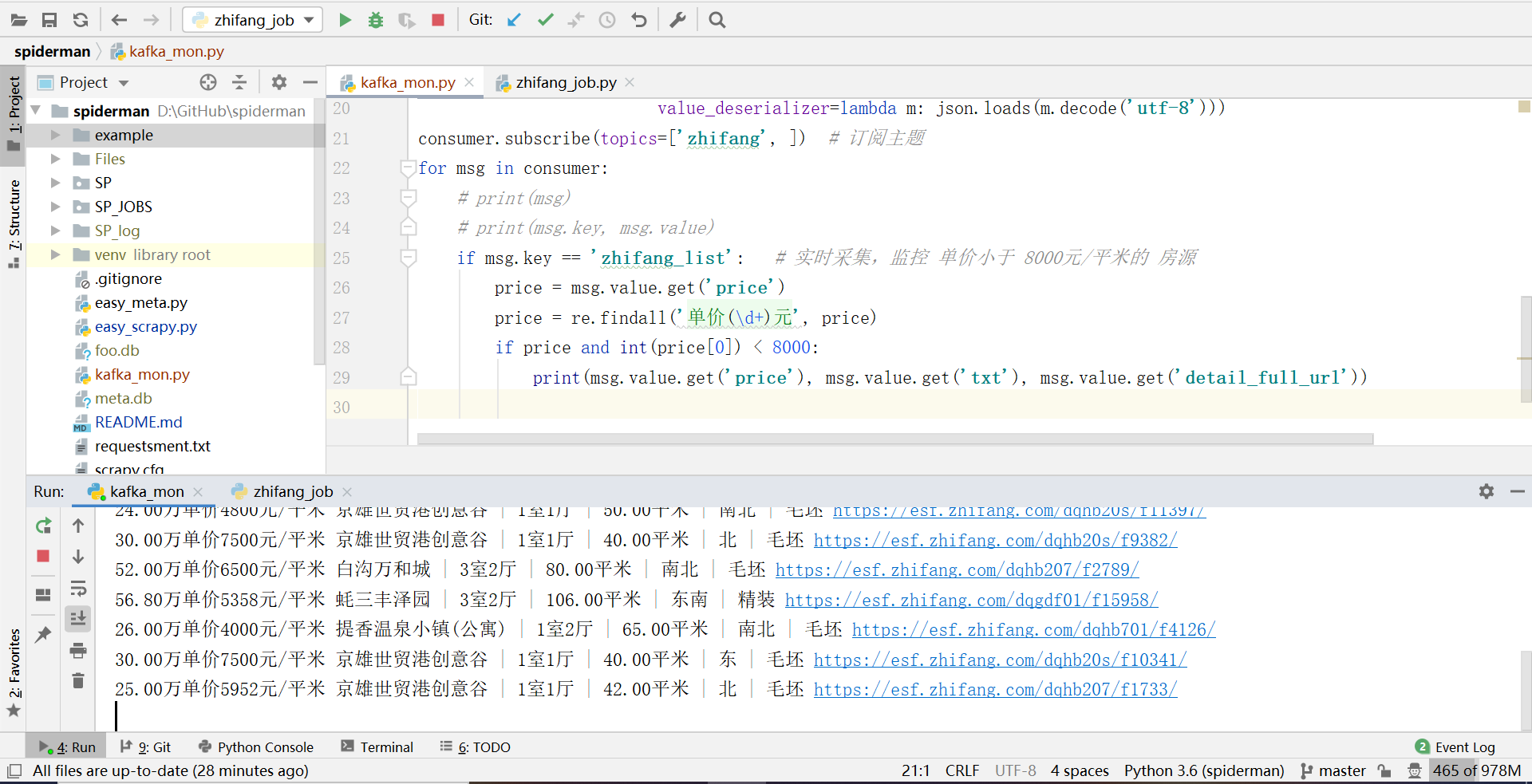
kafka实时采集监控
功能
-
自动建表
-
自动生成爬虫代码,只需编写少量代码即可完成分布式爬虫
-
自动存储元数据,分析统计和补爬都很方便
-
适合多站点开发,每个爬虫独立定制,互不影响
-
调用方便,可以根据传参自定义采集的页数以及启用的爬虫数量
-
扩展简易,可以根据需要选择采集模式,单机 standalone (默认) 或者 分布式cluster
-
采集数据落地方便,支持多种数据库,只需在 spider 中启用相关的管道
关系型
非关系型
-
反爬处理简易,已封装各种反爬中间件
原理说明
- 消息队列使用 redis,采集策略使用广度优先,先进先出
- 每个爬虫都有一个 job 文件,使用 job 来生成初始请求类 ScheduledRequest,并将其推送到 redis;
初始请求全部推到 redis 后,运行 spider 解析生成数据 并迭代新的请求到redis, 直到 redis 中的全部请求被消耗完
class ScheduledRequest:
def __init__(self, **kwargs):
self.url = kwargs.get('url')
self.method = kwargs.get('method', 'GET')
self.callback = kwargs.get('callback')
self.body = kwargs.get('body')
self.meta = kwargs.get('meta')
- item 类定义表名、字段名、排序号(自定义字段顺序)、注释说明(便于管理元数据)、字段类型(仅关系型数据库管道有效)
class zhifang_list_Item(scrapy.Item):
tablename = 'zhifang_list'
tabledesc = '列表'
tit = scrapy.Field({'idx': 1, 'comment': '房屋标题'})
txt = scrapy.Field({'idx': 2, 'comment': '房屋描述'})
tit2 = scrapy.Field({'idx': 3, 'comment': '房屋楼层'})
price = scrapy.Field({'idx': 4, 'comment': '房屋价格'})
agent = scrapy.Field({'idx': 5, 'comment': '房屋中介'})
detail_full_url = scrapy.Field({'idx': 100, 'comment': '详情链接'})
pkey = scrapy.Field({'idx': 101, 'comment': 'md5(detail_full_url)'})
pagenum = scrapy.Field({'idx': 102, 'comment': '页码'})
- 去重策略,默认不去重,每次采集独立,即每次启动 job 都会清空上一次未完成的 url,并且不保留 redis 中上一次已采集的 url 指纹。
如需调整可以修改以下配置
class zhifang_job(SPJob):
def __init__(self):
super().__init__(spider_name=zhifang_Spider.name)
custom_settings = {
...,
'DUPEFILTER_CLASS': 'scrapy_redis.dupefilter.RFPDupeFilter',
'SCHEDULER_PERSIST': True,
}
def get_callback(self, callback):
callback_dt = {
'list': (self.list_parse, False),
'detail': (self.detail_parse, False),
}
return callback_dt.get(callback)
当采集的数据量很大时,可以使用布隆过滤器,该算法占用空间小且可控,适合海量数据去重。
但是该算法会有漏失率,对爬虫而言就是漏爬。可以通过调整过滤器负载个数、内存配置、哈希次数以降低漏失率。
默认 1 个过滤器,256 M 内存,使用 7 个 seeds,这个配置表示漏失概率为 8.56e-05 时,可满足 0.93 亿条字符串的去重。当漏失率为 0.000112 时,可满足 0.98 亿条字符串的去重。调参与漏失率参考
custom_settings = {
...,
'DUPEFILTER_CLASS': 'SP.bloom_dupefilter.BloomRFDupeFilter',
'SCHEDULER_PERSIST': True,
'BLOOM_NUM': 1,
'BLOOM_MEM': 256,
'BLOOM_K': 7,
}
def get_callback(self, callback):
callback_dt = {
'list': (self.list_parse, False),
'detail': (self.detail_parse, False),
}
return callback_dt.get(callback)
下载安装
- git clone github.com/TurboWay/sp…; cd spiderman;
- 【不使用虚拟环境的话,可以跳过步骤23】virtualenv -p /usr/bin/python3 venv
- 【不使用虚拟环境的话,可以跳过步骤23】source venv/bin/activate
- pip install -i pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
- 修改配置 vi SP/settings.py
- 运行demo示例 python SP_JOBS/zhifang_job.py
如何开发一个新爬虫
运行 easy_scrapy.py 会根据模板自动生成以下代码文件,并自动在编辑器打开 spidername_job.py 文件;
| 类别 | 路径 | 说明 |
|---|
| job | SP_JOBS/spidername_job.py | 编写初始请求 |
| spider | SP/spiders/spidername.py | 编写解析规则,产生新的请求 |
| items | SP/items/spidername_items.py | 定义表名字段 |
以上代码文件编写完成后,直接执行 python SP_JOBS/spidername_job.py
或者动态传参(参数说明 -p 采集页数, -n 启用爬虫数量) python SP_JOBS/spidername_job.py -p 10 -n 1
如何进行补爬
运行 easy_scrapy.py 会根据模板自动生成以下代码文件,并自动在编辑器打开 spidername_job_patch.py 文件;
| 类别 | 路径 | 说明 |
|---|
| job | SP_JOBS/spidername_job_patch.py | 编写补爬请求 |
以上代码文件编写完成后,直接执行 python SP_JOBS/spidername_job_patch.py
如何下载附件
提供两种方式下载:
- 1、直接在 spider 中启用附件下载管道
- 2、使用自定义的下载器 execute_download.py 传参下载
jpg/pdf/word...等各种各样的文件,统称为附件。
下载附件是比较占用带宽的行为,所以在大规模采集中,最好是先把结构化的表数据、附件的元数据入库,
保证数据的完整性,然后再根据需要,通过下载器进行附件下载。
如何扩展分布式爬虫
采集模式有两种(在 settings 控制): 单机 standalone(默认) 和 集群分布式
如果想切换成分布式爬虫,需要在 spiderman/SP/settings.py 中启用以下配置
注意:前提是 所有SLAVE机器的爬虫代码一致、python环境一致,都可以运行爬虫demo
CLUSTER_ENABLE = True
| 配置名称 | 意义 | 示例 |
|---|
| SLAVES | 【二选一】爬虫机器配置列表 | [{'host': '172.16.122.12', 'port': 22, 'user': 'spider', 'pwd': 'spider'},
{'host': '172.16.122.13', 'port': 22, 'user': 'spider', 'pwd': 'spider'} ] |
| SLAVES_BALANCE | 【二选一】爬虫机器配置(ssh负载均衡) | {'host': '172.16.122.11', 'port': 2202, 'user': 'spider', 'pwd': 'spider'} |
| SLAVES_ENV | 【可选】爬虫机器虚拟环境路径 | /home/spider/workspace/spiderman/venv |
| SLAVES_WORKSPACE | 【必填】爬虫机器代码工程路径 | /home/spider/workspace/spiderman |
如何管理爬虫元数据
运行 easy_meta.py 自动生成当前项目所有爬虫的元数据, 默认记录到sqlite meta.db, 可以在 setting 中自行配置;
META_ENGINE = 'sqlite:///meta.db'
元数据表meta字典如下:
| 字段名 | 类型 | 注释 |
|---|
| spider | varchar(50) | 爬虫名 |
| spider_comment | varchar(100) | 爬虫描述 |
| tb | varchar(50) | 表名 |
| tb_comment | varchar(100) | 表描述 |
| col_px | int | 字段序号 |
| col | varchar(50) | 字段名 |
| col_comment | varchar(100) | 字段描述 |
| author | varchar(20) | 开发人员 |
| addtime | varchar(20) | 开发时间 |
| insertime | varchar(20) | 元数据更新时间 |
如何配合kafka做实时采集监控
- 配置 kafka(修改 setting 的 KAFKA_SERVERS)
- 自定义监控规则(修改编写 kafka_mon.py , 并运行该脚本程序, 开始监控)
- 在 spider 中启用 kafka 管道(运行爬虫 job , 开始采集)
如何使用爬虫api
直接运行 api.py,然后可以通过 http://127.0.0.1:2021/docs 查看相关的 api 文档
注意事项
- 字段名称不能使用 tablename、isload、ctime、bizdate、spider 等字段,因为这些字段被作为通用字段,避免冲突
- items 文件每个字段建议添加注释,生成元数据时,会将注释导入到元数据表,便于管理爬虫
hive环境问题
在 windows 环境下,使用 python3 连接 hive 会有很多坑,所以使用 hdfs 管道时,hive 自动建表功能默认关闭,便于部署。
假如需要启用 hive 自动建表功能,请进行如下操作:
- pip install -i pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
- pip install --no-deps thrift-sasl==0.2.1
- 验证环境,执行 SP.utils.ctrl_hive
如果执行成功,说明 hive 环境准备完毕,可以直接启用 hive 自动建表功能;如果遇到问题,可以参考 【大数据】windows 下python3连接hive
更新日志
| 日期 | 更新内容 |
|---|
| 20200803 | 1.使用更优雅的方式来生成元数据;
2.管道函数传参的写法调整;
3.附件表通用字段更名:下载状态 (isload => status) |
| 20200831 | 1.解决数据入库失败时,一直重试入库的问题;
2.所有管道优化,入库失败时,自动切换成逐行入库,只丢弃异常记录 |
| 20201104 | 1.requests 中间件支持 DOWNLOAD_TIMEOUT、DOWNLOAD_DELAY |
| 20201212 | 1.payload 中间件支持 DOWNLOAD_TIMEOUT、DOWNLOAD_DELAY;
2.get_sp_COOKIEs 方法优化,使用轻量级的 splash 替换 selenium;
3.md 的原理部分增加去重策略的说明 |
| 20210105 | 1.增加布隆过滤器 |
| 20210217 | 1.elasticsearch 管道调整,兼容 elasticsearch7 以上版本,直接使用表名作为索引名 |
| 20210314 | 1.所有反爬中间件合并到 SPMiddleWare |
| 20210315 | 1.使用更优雅的方式生成 job 初始请求;
2.headers 中间件优化,减少 redis 的内存占用;
3.删除 COOKIE 中间件,COOKIE 只是 headers 里面的一个值,可以直接使用 headers 中间件;
4.删除 Payload 中间件,Payload 请求可以直接使用 requests 中间件
5.增加 COOKIEsPool 中间件,用于需要多个账号随机切换采集的场景 |
| 20210317 | 1.增加可以脱离 scrapy 独立工作的、支持分布式的附件下载器 |
| 20210318 | 1.增加 api 服务 |










 京公网安备 11010802041100号
京公网安备 11010802041100号