接着系统一,继续开始我们face_recognition.
import face_recognition
image = face_recognition.load_image_file("my_picture.jpg")
face_locations = face_recognition.face_locations(image)
# face_locations is now an array listing the co-ordinates of each face!
看定位鞠婧祎的脸:在knowe_people文件夹中创建find_faces_in_picture.py文件并写入以下代码:
from PIL import Image
import face_recognition
# Load the jpg file into a numpy array
image = face_recognition.load_image_file("鞠婧祎.jpeg")
# Find all the faces in the image using the default HOG-based model.
# This method is fairly accurate, but not as accurate as the CNN model and not GPU accelerated.
# See also: find_faces_in_picture_cnn.py
face_locatiOns= face_recognition.face_locations(image)
print("I found {} face(s) in this photograph.".format(len(face_locations)))
for face_location in face_locations:
# Print the location of each face in this image
top, right, bottom, left = face_location
print("A face is located at pixel location Top: {}, Left: {}, Bottom: {}, Right: {}".format(top, left, bottom, right))
# You can access the actual face itself like this:
face_image = image[top:bottom, left:right]
pil_image = Image.fromarray(face_image)
pil_image.show()
然后终端切换到knowe_people目录下,输入以下命令,弹出窗口如下:
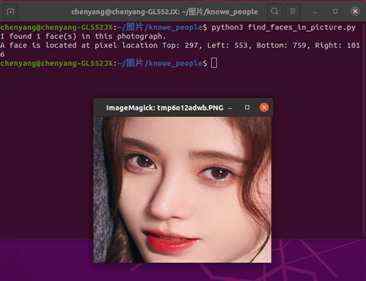
可以看到终端已经找到鞠婧祎人脸坐标分别是:Top: 297, Left: 553, Bottom: 759, Right: 1016,并输出人脸。继续测试
将第二段第二行改为image = face_recognition.load_image_file("特朗普.jpg"),终端输出如下:
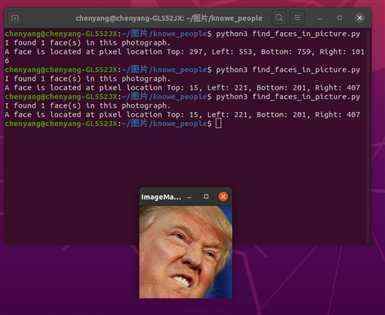
你也可以使用深度学习模型达到更加精准的人脸定位。
注意:这种方法需要GPU加速(通过英伟达显卡的CUDA库驱动),你在编译安装dlib的时候也需要开启CUDA支持。
import face_recognition
image = face_recognition.load_image_file("my_picture.jpg")
face_locations = face_recognition.face_locations(image, model="cnn")
# face_locations is now an array listing the co-ordinates of each face!
看案例:利用卷积神经网络深度学习模型定位鞠婧祎的人脸
在knowe_people文件夹中创建find_faces_in_picture_cnn.py文件并写入以下代码:
from PIL import Image
import face_recognition
# Load the jpg file into a numpy array
image = face_recognition.load_image_file("鞠婧祎.jpg")
# Find all the faces in the image using a pre-trained convolutional neural network.
# This method is more accurate than the default HOG model, but it‘s slower
# unless you have an nvidia GPU and dlib compiled with CUDA extensions. But if you do,
# this will use GPU acceleration and perform well.
# See also: find_faces_in_picture.py
face_locatiOns= face_recognition.face_locations(image, number_of_times_to_upsample=0, model="cnn")
print("I found {} face(s) in this photograph.".format(len(face_locations)))
for face_location in face_locations:
# Print the location of each face in this image
top, right, bottom, left = face_location
print("A face is located at pixel location Top: {}, Left: {}, Bottom: {}, Right: {}".format(top, left, bottom, right))
# You can access the actual face itself like this:
face_image = image[top:bottom, left:right]
pil_image = Image.fromarray(face_image)
pil_image.show()
然后终端切换到knowe_people目录下,输入以下命令,弹出窗口如下:
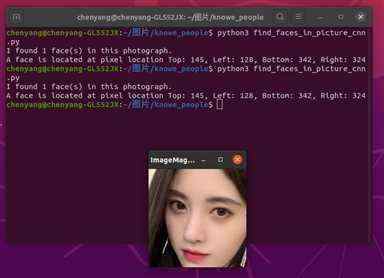
如果你有很多图片需要识别,同时又有GPU,那么你可以参考这个例子:
案例:利用卷积神经网络深度学习模型批量识别人脸照片
在knowe_people文件夹中创建find_faces_in_batches.py文件并写入以下代码:
import face_recognition
import cv2
# This code finds all faces in a list of images using the CNN model.
#
# This demo is for the _special case_ when you need to find faces in LOTS of images very quickly and all the images
# are the exact same size. This is common in video processing applications where you have lots of video frames
# to process.
#
# If you are processing a lot of images and using a GPU with CUDA, batch processing can be ~3x faster then processing
# single images at a time. But if you aren‘t using a GPU, then batch processing isn‘t going to be very helpful.
#
# PLEASE NOTE: This example requires OpenCV (the `cv2` library) to be installed only to read the video file.
# OpenCV is *not* required to use the face_recognition library. It‘s only required if you want to run this
# specific demo. If you have trouble installing it, try any of the other demos that don‘t require it instead.
# Open video file
video_capture = cv2.VideoCapture("short_hamilton_clip.mp4")
frames = []
frame_count = 0
while video_capture.isOpened():
# Grab a single frame of video
ret, frame = video_capture.read()
# Bail out when the video file ends
if not ret:
break
# Convert the image from BGR color (which OpenCV uses) to RGB color (which face_recognition uses)
frame = frame[:, :, ::-1]
# Save each frame of the video to a list
frame_count += 1
frames.append(frame)
# Every 128 frames (the default batch size), batch process the list of frames to find faces
if len(frames) == 128:
batch_of_face_locatiOns= face_recognition.batch_face_locations(frames, number_of_times_to_upsample=0)
# Now let‘s list all the faces we found in all 128 frames
for frame_number_in_batch, face_locations in enumerate(batch_of_face_locations):
number_of_faces_in_frame = len(face_locations)
frame_number = frame_count - 128 + frame_number_in_batch
print("I found {} face(s) in frame #{}.".format(number_of_faces_in_frame, frame_number))
for face_location in face_locations:
# Print the location of each face in this frame
top, right, bottom, left = face_location
print(" - A face is located at pixel location Top: {}, Left: {}, Bottom: {}, Right: {}".format(top, left, bottom, right))
# Clear the frames array to start the next batch
frames = []
注意到:这个例子需要安装openCV.这个例子需要GPU cuda加速,否则运行卡顿。我就试了几次,电脑死机,先跳过,以后再说。
案例:使用卷积神经网络深度学习模型把来自网络摄像头视频的人脸高斯模糊。
在knowe_people文件夹中创建blur_faces_on_webcam.py文件并写入以下代码:
import face_recognition
import cv2
# This is a demo of blurring faces in video.
# PLEASE NOTE: This example requires OpenCV (the `cv2` library) to be installed only to read from your webcam.
# OpenCV is *not* required to use the face_recognition library. It‘s only required if you want to run this
# specific demo. If you have trouble installing it, try any of the other demos that don‘t require it instead.
# Get a reference to webcam #0 (the default one)
video_capture = cv2.VideoCapture(0)
# Initialize some variables
face_locatiOns= []
while True:
# Grab a single frame of video
ret, frame = video_capture.read()
# Resize frame of video to 1/4 size for faster face detection processing
small_frame = cv2.resize(frame, (0, 0), fx=0.25, fy=0.25)
# Find all the faces and face encodings in the current frame of video
face_locatiOns= face_recognition.face_locations(small_frame, model="cnn")
# Display the results
for top, right, bottom, left in face_locations:
# Scale back up face locations since the frame we detected in was scaled to 1/4 size
top *= 4
right *= 4
bottom *= 4
left *= 4
# Extract the region of the image that contains the face
face_image = frame[top:bottom, left:right]
# Blur the face image
face_image = cv2.GaussianBlur(face_image, (99, 99), 30)
# Put the blurred face region back into the frame image
frame[top:bottom, left:right] = face_image
# Display the resulting image
cv2.imshow(‘Video‘, frame)
# Hit ‘q‘ on the keyboard to quit!
if cv2.waitKey(1) & 0xFF == ord(‘q‘):
break
# Release handle to the webcam
video_capture.release()
cv2.destroyAllWindows()
然后终端切换到knowe_people目录下,输入以下命令,弹出窗口如下:(把自己宿舍卖了,希望室友不要介意,嘻嘻)
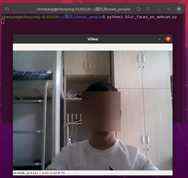
好了,今天就到这吧,今天主要实现4个功能(如下),更多功能见系列三。
案例一:定位鞠婧祎的脸
案例二:利用卷积神经网络深度学习模型定位鞠婧祎的人脸
案例三:利用卷积神经网络深度学习模型批量识别人脸照片
案例四:使用卷积神经网络深度学习模型把来自网络摄像头视频的人脸高斯模糊。









 京公网安备 11010802041100号
京公网安备 11010802041100号