基线系统需要受到更多关注:基于词向量的简单模型
最近阅读了《Baseline Needs More Love: On Simple Word-Embedding-Based Models and Associated Pooling Mechanisms》这篇论文[1],该工作来自杜克大学,发表在ACL 2018上。论文详细比较了直接在词向量上进行池化的简单模型和主流神经网络模型(例如CNN和RNN)在NLP多个任务上的效果。实验结果表明,在很多任务上简单的词向量模型和神经网络模型(CNN和LSTM)的效果相当,有些任务甚至简单模型更好。下面是我对这篇论文的阅读笔记。
1 引言
在NLP领域,词向量(word embedding)已经受到了研究者们的广泛关注和应用。它通过大量的无标签数据将每个词表示成一个固定维度的向量。相比传统的独热(one-hot)表示,词向量具有低维紧密的特点,并能学习到丰富的语义和句法信息。目前代表性的词向量工作有word2vec [2]和GloVe [3]。在NLP领域,使用词向量将一个变长文本表示成一个固定向量的常用方法有:1)以词向量为输入,使用一个复杂的神经网络(CNN,RNN等)来进行文本表示学习;2)在词向量的基础上,直接简单的使用按元素求均值或者相加的简单方法来表示。对于复杂神经网络方法,模型复杂计算量大耗时。该论文通过大量实验发现,基于词向量的简单池化模型对于大多数的NLP问题,已经表现得足够好,有时甚至效果超过了复杂的神经网络模型。
2. 方法
该文对比的主流神经网络模型为:LSTM和CNN。对于LSTM特点在于使用门机制来学习长距离依赖信息,可以认为考虑了词序信息。对于CNN特点是利用滑动窗口卷积连续的词特征,然后通过池化操作学习到最显著的语义特征。
对于简单的词向量模型(Simple word-embedding model,SWEM),作者提出了下面几种方法。

- SWEM-aver:就是平均池化,对词向量的按元素求均值。这种方法相当于考虑了每个词的信息。
- SWEM-max:最大池化,对词向量每一维取最大值。这种方法相当于考虑最显著特征信息,其他无关或者不重要的信息被忽略。
- SWEM-concat:考虑到上面两种池化方法信息是互补的,这种变体是对上面两种池化方法得到的结果进行拼接。
- SWEM-hier:上面的方法并没有考虑词序和空间信息,提出的层次池化先使用大小为n局部窗口进行平均池化,然后再使用全局最大池化。该方法其实类似我们常用的n-grams特征。
接下来对比一下SWEM和神经网络模型结构。可以看到SWEM仅对词向量使用池化操作,并没有额外的参数,且可以高度并行化。

3. 实验结果与分析
实验中,使用了300维的GloVe词向量,对于未登录词按照均匀分布进行初始化。最终的分类器使用了多层感知机MLP进行分类。在文档分类,文本序列匹配和句子分类三大任务,共17个数据集上进行了实验并进行了详细的分析。
3.1 文档分类
实验中的文档分类任务能被分为三种类型:主题分类,情感分析和本体分类。实验结果如下:
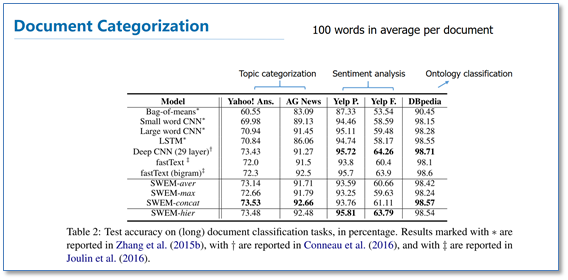
令人惊奇的是在主题分类任务上,SWEM模型获得了比LSTM和CNN更好的结果,特别是SWEM-concat模型的效果甚至优于29层的Deep CNN。在本体分类任务上也有类似的趋势。有趣的是对于情感分析任务,CNN和LSTM效果要好于不考虑词序信息的SWEM模型。对于考虑了词序和空间信息的SWEM-hier取得了和CNN/LSTM相当的结果。这可能是情感分析任务需要词序信息。例如"not really good"和"really not good"的情感等级是不一样的。
在大多数任务上SWEM-max的方法略差于SWEM-aver,但是它提供了互补的信息,所以SWEM-concat获得了更好的结果。更重要的是,SWEM-max具有很强的模型解释性。论文在Yahoo数据集上训练了SWEM-max模型(词向量随机初始化)。然后根据训练学习后的词向量中的每一维的值画了直方图,如下图1:

可以看到相比与GloVe,SWEM-max学习出来的词向量是十分稀疏的,这说明在预测文本时,模型只依靠一些关键词,这就增加了模型的解释性。论文在整个词汇表中根据词向量维度挑选出了一个维度中值最大的5个词展示在表3中。可以看到每个维度选出的词是同一个主题相关的。甚至模型可以学到没有标签信息的结构,例如表3中的"Chemistry",在数据集中是没有chemistry标签的,它属于science主题。
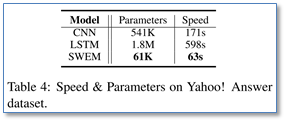
在模型时间上,SWEM模型要比CNN和LSTM都高效。
3.2 文本序列匹配
在句子匹配问题的实验室中,主要包括自然语言推理,问答中答案句选择和复述识别任务。实验结果如下:
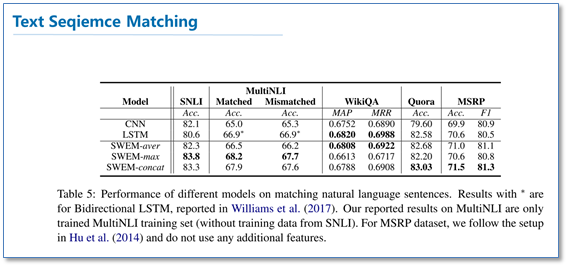
可以看到除了WikiQA数据集,其他数据集上,SWEM模型获得了比CNN和LSTM更好的结果。这可能是因为在当匹配自然语言句子时,在大多数情况下,只需要使用简单模型对两个序列之间在单词级别上进行对比就足够了。从这方面也可以看出,词序信息对于句子匹配的作用比较小。此外简单模型比LSTM和CNN更容易优化。
3.3 句子分类
相比与前面的文档分类,句子分类任务平均只有20个词的长度。实验结果如下:
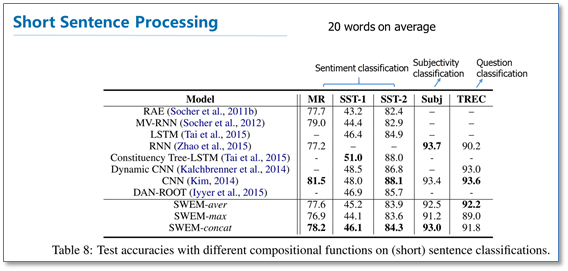
在情感分类任务上,和前面文档分类的实验结果一样,SWEM效果差于LSTM和CNN,在其他两个任务上,效果只是略差于NN模型。相比与前面的文档分类,在短句子分类上SWEM的效果要比长文档的分类效果要差。这也可能是由于短句中词序信息更重要。此外,论文还在附加材料中补充了对序列标注任务的实验,实验结果如下:
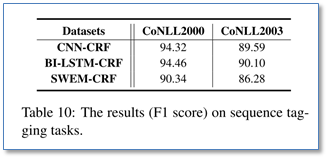
可以看到对于词序敏感的序列标注任务,SWEM的效果明显要差于CNN和RNN。
3.4 词序信息的重要性
从上面可以看到,SWEM模型的一个缺点在于忽略了词序信息,而CNN和LSTM模型能够一定程度的学习词序信息。那么在上述的这些任务中,词序信息到底有多重要?为了探索这个问题,该文将训练数据集的词序打乱,并保持测试集的词序不变,就是为了去掉词序信息。然后使用了能够学习词序信息LSTM模型进行了实验,实验结果如下:
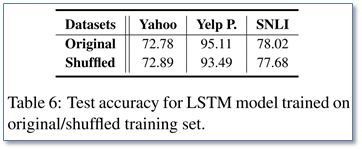
令人惊奇地发现,在Yahoo和SNLI数据集(也就是主题分类和文本蕴涵任务)上,在乱序训练集上训练的LSTM取得了和原始词序相当的结果。这说明词序信息对这两个问题并没有明显的帮助。但是在情感分析任务上,乱序的LSTM结果还是有所下降,说明词序对于情感分析任务还是比较重要。
在来看看SWEM-hier在情感分析上的效果,相比与SWEM其他模型,SWEM-hier相当于学习了n-gram特征,保留了一定的局部词序信息。在两个情感任务上效果也是由于其他SWEM模型,这也证明了SWEM-hier能够学习一定的词序信息。
3.5. 其他实验
除了上述实验,该文还设置了一些实验在说明SWEM的性能。对于之前的使用非线性的MLP作为分类器,替换成了线性分类器进行了实验。在Yahoo(从73.53%到73.18%)和Yelp P(93.76%到93.66%)数据集上SWEM的效果并未明显下降。这也说明了SWEM模型能够抽取鲁棒、有信息的句子表示。该文还在中文数据集上进行了实验,实验结果表明层次池化比最大和平均池化更适合中文文本分类,这样暗示了中文可能比英文对词序更加敏感。
在附加材料中,该文还用SWEM-concat模型在Yahoo数据集上对词向量维度(从3维到1000维)进行了实验,这里词向量使用随机初始化。

可以看到高的维度一般效果会更好一些,因为能够表示更丰富的语义信息。但是,可以看到词向量在10维的时候已经可以达到和1000维相当的效果。其实这也和论文[4]的结果比较一致,在一些任务上小维度的词向量效果也已经足够好了。
此外,论文还对训练集规模对模型效果影响进行了实验。在Yahoo和SNLI数据集上分别取不同比例的训练集对模型进行训练测试,结果如下图:
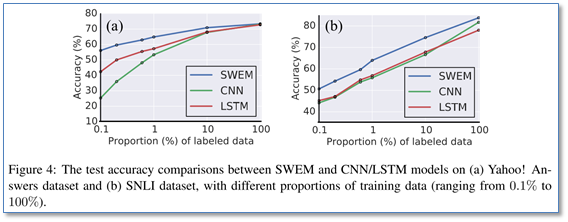
可以看到当标注训练集规模比较小时,简单的SWEM模型的效果更好,这可能也是CNN和LSTM复杂模型在小规模训练数据上容易过拟合导致的。
4. 总结
该论文展示了在词向量上仅使用池化操作的简单模型SWEM的性能,在多个NLP任务数据集上进行了实验,比较了SWEM和目前主流的NN模型(CNN和LSTM)性能。实验发现,SWEM这样简单的基线系统在很多任务上取得了与NN相当的结果,实验中的一些总结如下:
-
简单的池化操作对于长文档(上百个词)表示具有不错的表现,而循环和卷积操作对于短文本更有效。
-
情感分析任务相比主题文本分类任务对词序特征更敏感,但是该文提出的一种简单的层次池化也能够学习一定的词序信息,和LSTM/CNN在情感分析任务上取得了相当的结果。
-
对于句子匹配问题,简单的池化操作已经展现出了与LSTM/CNN相当甚至更好的性能。
-
对于SWEM-max模型,可以通过对词向量维度的分析得到较好的模型解释。
-
在一些任务上,词向量的维度有时在低维已经足够好。
-
在标注训练集规模小的时候,简单的SWEM模型可能更加鲁棒、获得更好的表现。
总的来说,我们在进行研究时,有时为了让模型学习到更为丰富的信息,会把模型设计得十分复杂,但是这篇论文通过实验告诉了我们,简单的基线系统也能够获得很不错的表现。当我们做具体任务时,应该根据具体需求来选择设计模型(模型效果,模型复杂度,模型运行时间等的权衡),简单有效的系统也应该受到关注。
参考文献:
[1] Shen, Dinghan, et al. "Baseline needs more love: On simple word-embedding-based models and associated pooling mechanisms." arXiv preprint arXiv:1805.09843 (2018).
[2] Mikolov, Tomas, et al. "Distributed representations of words and phrases and their compositionality." Advances in neural information processing systems. 2013.
[3] Pennington, Jeffrey, Richard Socher, and Christopher Manning. "Glove: Global vectors for word representation." Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP). 2014.
[4] Lai, Siwei, et al. "How to generate a good word embedding." IEEE Intelligent Systems 31.6 (2016): 5-14.





 京公网安备 11010802041100号
京公网安备 11010802041100号