作者: | 来源:互联网 | 2023-09-07 20:26
文章目录即席查询—Presto1提高查询速度?2定义3架构4优、缺5命令行客户端6可视化客户端7优化7.1数据存储7.2SQL8避坑即席查询—Presto1提高查询
文章目录
- 即席查询—Presto
- 1 提高查询速度?
- 2 定义
- 3 架构
- 4 优、缺
- 5 命令行客户端
- 6 可视化客户端
- 7 优化
- 8 避坑
即席查询—Presto
1 提高查询速度?
1、基于内存:充分利用内存引入Presto
2、预计算:查之前将可能查询的结果都计算出(提前计算出)kylin
2 定义
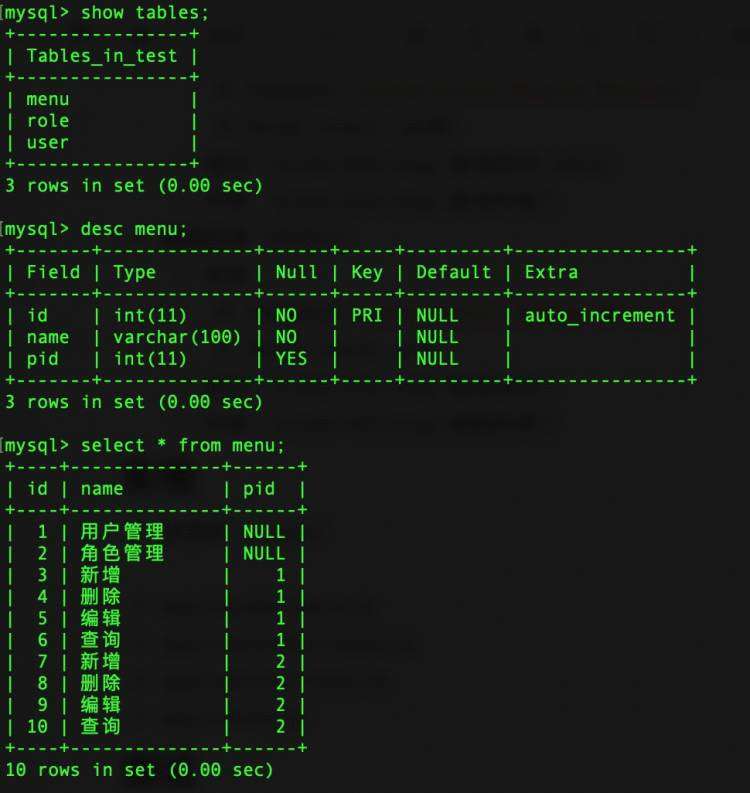
Presto是一个开源的分布式的SQL查询引擎,数据量支持GB到PB字节,主要用来处理秒级查询的场景。但是它并不是一个标准的数据库,只是用来解析SQL。
3 架构
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ok8abKt4-1621403043329)(../../AppData/Roaming/Typora/typora-user-images/image-20210519101232540.png)]](https://img3.php1.cn/3cdc5/63cc/61b/1504bf259d0dd461.png)
各功能解释如下
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NKIQmmZU-1621403043332)(../../AppData/Roaming/Typora/typora-user-images/image-20210519101201000.png)]](https://img3.php1.cn/3cdc5/63cc/61b/5af3a1c102ededb3.png)
4 优、缺
优
1、基于内存计算,减少磁盘IO
2、支持多种数据源,可以进行跨数据源的连表查询,比如读取hive某表信息和mysql中进行表的关联匹配(主要的原因是因为presto有其统一的数据结构schema+table)
缺
缺点无非是效率和数量的不平衡,虽说presto可以处理PB级别的数据,但它并不是将这个数据放在内存中进行计算,而是根据场景进行调整,比如一些聚合(count、avg、sum、max等)的操作就会边读、边算、边清内存,然后再读再算,所以这种消耗内存不高,但是连表查会产生大量临时数据(主要就是多表联合得先生成一个最终需要查询的临时表,再进行查询操作),因而速度会慢;解决方案:可以先在hive里面提前进行多表关联成大宽表的操作,然后presto就可直接查询
5 命令行客户端
./prestocli --server master:8881 --catalog hive --schema default
它和hive查询不太一样,它不是全部出来,只会出现一部分,可以使用回车出现一行,空格进行换页,到最后结尾end的时候按q退出
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SJZ2Pk1c-1621403043333)(../../AppData/Roaming/Typora/typora-user-images/image-20210519113235897.png)]](https://img3.php1.cn/3cdc5/63cc/61b/47997ec85a68b8f7.png)
其实它中间查询是由一个通道,查多少拿多少,没有全部显示直接退出可能会报断开的管道错;如果不添加LZO的依赖,presto查询会出问题
6 可视化客户端
nohup bin/yanagishima-start.sh >y.log 2>&1 &

7 优化
7.1 数据存储
1、分区处理:合理化的设置分区,同hive类似;合理的分区可以减少它的数据读取量,提升查询的性能
2、存储格式:对ORC文件进行特定的优化,相对于Parquet,对ORC更友好
3、压缩格式:选择snappy优先,要求速度快
7.2 SQL
1、选择字段:选择需要的字段进行读取、减少数据量,少用*
2、分区字段:能以分区作为过滤条件,尽量使用分区
3、Group By:将group by语句中的字段按照每个字段的distinct数据多少进行降序排列
4、Order By:如果需要使用order by进行全局排序查询TopN或者BottomN(倒数),使用limit可减少排序计算和内存的压力
5、Join:①broadcast join大表join小表,presto中join的默认算法是broadcast join,采用的大表切分、小表广播,大表会被切分成每份送往worker,小表直接广播复制到worker中进行join;②hash join大表join大表,会根据要join的字段将两张表进行hash,hash相同的进入同一worker进行join
8 避坑
1、引用关键字:避免对关键字的冲突引用,MySQL对字段加反引号`,但在presto对字段是假双引号"",如果字段不是关键字可以不加
2、时间函数:对于时间戳类型(timestamp)需要比较的时候,需要添加timestamp关键字
SELECT t FROM a WHERE t > '2017-01-01 00:00:00';
SELECT t FROM a WHERE t > timestamp '2017-01-01 00:00:00';
3、不支持insert overwrite:persto中不支持insert overwrite语法,毕竟它是专门用来查询的,如果实在想插入数据,那只能先delete,然后insert into
4、parquet存储格式:persto只支持parquet列式存储格式的查询,不支持插入








 京公网安备 11010802041100号
京公网安备 11010802041100号