来源:Jerry的算法和NLP
Jerry的算法和NLP
先说下结论:没有一个模型是万能的,需要根据数据选择适合的模型。
在机器学习中,数据大概可以分成四大类:图像 (Image),序列(Sequence),图(Graph) 和表格(Tabular) 数据。其中,前3类数据有比较明显的模式,比如图像和图的空间局部性,序列的上下文关系和时序依赖等。而表格数据常见于各种工业界的任务,如广告点击率预测,推荐系统等。在表格数据中,每个特征表示一个属性,如性别,价格等等,特征之间一般没有明显且通用的模式。
神经网络适合的是前三类数据,也就是有明显模式的数据。因为我们可以根据数据的模式,设计对应的网络结构,从而高效地自动抽取“高级”的特征表达。如常见的 CNN (卷积神经网络) 就是为图像而设计的,RNN (循环神经网络) 为序列数据而设计的。而表格数据,因没有明显的模式,非要用神经网络的话,就只能用低效的全连接网络,一般效果都不太好。在实践中,对于表格数据,除了专门对特定任务设计的网络结构如DeepFM等,更多时候还是用传统机器学习模型。尤其是 GBDT (梯度提升树),因其自动的特征选择能力及动态的模型复杂度,算得上是一个万金油模型,在各种类型的表格数据上都表现很好。但对于表格数据而言,其实特征工程才是更关键的。在给定数据的情况下,模型决定了下限,特征决定了上限。特征工程类似于神经网络的结构设计,目的是把先验知识融入数据,并且让模型更好地理解数据,让模型可以学得更好。
另外,神经网络实质上不算是一个模型,而是一类可以自由“搭积木”的模型。结构不同的神经网络可以认为是不同的模型了。
总结下,no free lunch,没有一个万能的模型,可以直接用于各种数据。有多少人工就有多少智能:用神经网络的话,你需要结构设计;而用传统模型的话,你需要特征工程。
首先说大家熟悉的监督学习任务,比如分类和回归。
神经网络的优势要在数据量很大,计算力很强的时候才能体现,数据量小的话,很多任务上的表现都不是很好。
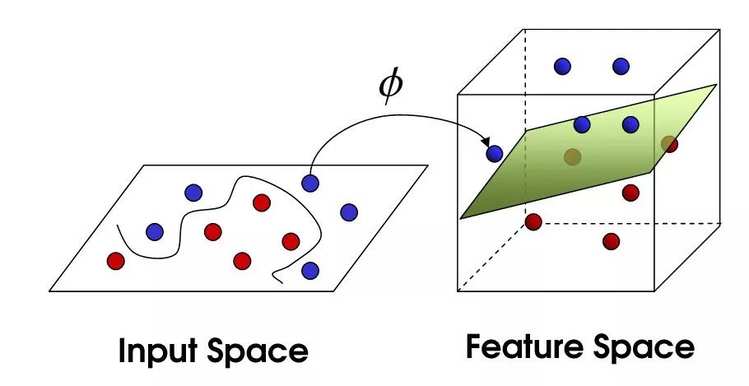
SVM属于非参数方法,拥有很强的理论基础和统计保障。损失函数拥有全局最优解,而且当数据量不大的时候,收敛速度很快,超参数即便需要调整,但也有具体的含义,比如高斯kernel的大小可以理解为数据点之间的中位数距离(Median heuristic)。在神经网络普及之前,引领了机器学习的主流,那时候理论和实验都同样重要。
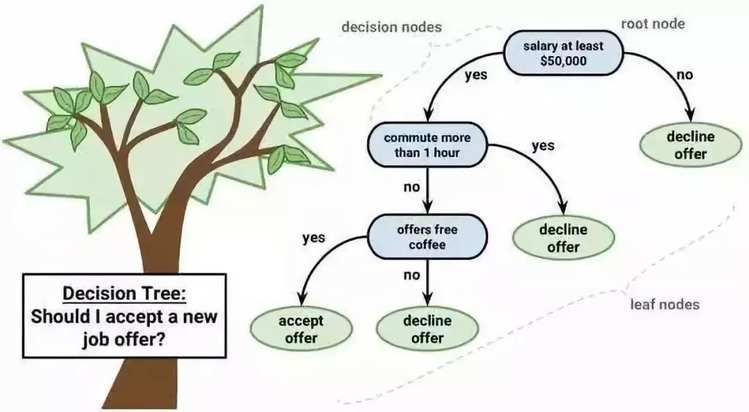
决策树也是非参数方法之一。我的经验告诉我,很多时候随机森林要比SVM要好,而且森林的训练时间可以很短,但感觉超参数调节上不是很intuitive,几棵树?收敛条件?都需要一个个试。
神秘网络拥有很多局部最优,而且理论上过拟合很容易,但各种tricks神奇的避免了这些理论弊端,但很多时候人们并不清楚它的工作和训练原理,而且泛化能力为什么高(各种竞赛结果)/低(对抗样本),也没有解释。在给定计算量下,神经网络基本上没办法和传统方法比。好在GPU解决了这个弊端。
总之,当数据量小的时候,传统方法依靠理论保障(kernel methods),或者用先验(贝叶斯方法)来控制解的空间,通常会有很好的表现。
再说一些光看神经网络还用不到的任务。答主可能也只是问在监督范畴内,传统方法有什么价值。但我想在更广泛的背景下介绍一下传统方法的意义何在。
一般认为监督式学习是已经解决了的问题,所以最前沿的理论研究都集中在非监督领域。炼丹在此略过。
非监督学习领域,虽然神经网络也被用作模型一部分,但主要还是以方程近似的角色体现。GAN,Normalizing flow, VAE,energy-based models... 这些方法还依靠统计理论。比如,kernel methods加上神经网络可以用于密度估计,但主要的原理还是建立在传统体系下(max likelihood,score matching等),神经网络只不过是更复杂的kernel超参数而已。
最后提一项神经网络基本不可能用到的任务
假设检验是非常重要的科研工具,用在很多关键领域上。医学上判断药物是否有作用,社会学上判断一项政策是否改变了社会参数,金融上判断两只产品的之间是否有关联,机器学习上判断两个GAN生成的图片那个更真实…都需要用到假设检验。
大家熟悉的t-test, rank test, K-S test等都只适用于一维数据,而且数据的收集可能不理想(比如长期监测的病人提前退出测试),数据本身并不满足参数性假设(如残差为高斯分布)…
如果要开发一项检验方法,需要控制Type-1 error,也就是当H0为真的时候,错误拒绝H0的概率。这个时候神经网络这个黑箱就成了很大的障碍,因为没有任何理论基础。而kernel方法依靠深厚的理论基础,可以在几乎没有任何数据分布假设下,从数学上给出Type-1 error的保障,也就可以被用在很多关键领域的检测。同时,数据收集不理想的时候,也可以通过一大堆数学推倒来实现这些test。如果有了黑箱,那基本就相当于把理论给扔了。

未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”










 京公网安备 11010802041100号
京公网安备 11010802041100号