一般分为编码层、交互层和输出层。
机器阅读理解模型的输入为文章和问题。因此,首先要对这两部分进行数字化编码,将其变成可以被计算机处理的信息单元。在编码的过程中,模型需要保留原有语句在文章中的语义。因此,每个单词、短语和句子的编码必须建立在理解上下文的基础上。我们把模型中进行编码的模块称为编码层。
接下来,由于文章和问题之间存在相关性,模型需要建立文章和问题之间的联系。例如,如果问题中出现关键词“河流”,而文章中出现关键词“长江”,虽然两个词不完全一样,但是其语义编码接近。因此,文章中“长江”一词以及邻近的语句将成为模型回答问题时的重点关注对象。这可以通过3.4节介绍的注意力机制加以解决。在这个过程中,阅读理解模型将文章和问题的语义结合在一起进行考量,进一步加深模型对于两者的理解。我们将这个模块称为交互层。
经过交互层,模型建立起文章和问题之间的语义联系,接下来就可以预测问题的答案了。完成预测功能的模块称为输出层。根据1.4.1节的介绍,机器阅读理解任务的答案有多种类型,如区间型、多项选择型等,因此输出层的具体形式需要和任务的答案类型相关联。此外,输出层确定模型优化时的评估函数和损失函数。
下图所示为机器阅读理解模型的一般架构。从图中可以看出,编码层可分别对文章和问题进行底层处理,将文本转化成数字编码。交互层可以让模型聚焦文章和问题的语义联系,借助于文章的语义分析加深对问题的理解,同时借助于问题的语义分析加深对文章的理解。输出层根据语义分析结果和答案的类型生成模型的答案输出,以输出层为区间式答案为例,机器阅读理解模型的总体架构如图所示。
在基本架构的框架下,不同的机器阅读理解模型在结构的每个计算层中设计和采用各种子结构,以不断提高模型的效率和答案的质量。值得注意的是,大部分阅读理解模型的创新集中在交互层,因为在这一层中对文章和问题语义的交叉分析有很多不同的处理方式,而且这也是使模型最终能产生正确答案的关键步骤。相比之下,编码层和输出层有着较为稳定的模式,但也在不断进行改良和创新。
与其他基于深度学习的自然语言处理模型类似,机器阅读理解模型首先需要将文字形式的文章和问题转化为词向量。
编码层一般采用类似的算法对文本进行分词和向量化处理,然后加入字符编码等更丰富的信息,并采用上下文编码获得每个单词在具体语境中的含义。
我们有两种方式获得词表中的单词向量:
第一种选择的优势是模型参数少,训练初期收敛快;第二种优势是可以根据实际数据调整词向量的值,以达到更好的训练效果。而采用预训练词表向量初始化一般可以使得模型在优化的最初几轮获得明显比随机初始化方法更优的效果。
命名实体和词性编码
在编码层,为了更准确的表示每个单词在语句中的语义,除了词表向量外,还经常对命名实体(named entity)和词性(pard-of-speech)进行向量化处理。如果命名实体有N种,则建立一个大小为N的命名实体表,每种命名实体用一个长度为dN的向量表示;词性同理。然后用文本分析软件包,如spaCy,获得文章和问题中的每个词的命名实体和词性,再将对应向量拼接在词向量之后。由于一个词的命名实体属性与词性和这个词所在的语句有关,因此用这种方式获取的向量编码可以更好的表示单词的语义,在许多模型中对性能有明显的提高。
精确匹配编码
另一种在机器阅读理解种非常有效的单词编码是精确匹配编码。
对文章中的单词w,检查w是否出现在问题中:如果是,w的精确匹配编码为1,否者为0。然后将这个二进制位拼接在单词向量后。由于单词可能有变体(复数、时态),也可以用另一个二进制位表示w的词干(stem)是否和问题中某些词的词干一致。精确匹配编码可以使模型快速找到文章中出现了问题单词的部分,而许多问题的答案往往就在这部分内容的附近。
文本处理种时常会出现拼写错误,即一个单词中大部分字符正确,但有几个字符的拼写或顺序与正确方式不同,这时通过字符组合,往往可以识别正确的单词形式。此外,许多语言种存在词根的概念,在单词理解中字符和子词具有很强的辅助作用。
基于词表的单词向量是固定的,不会随着上下文变化,这就会导致同一个词在不同的语句中的语义不同但其向量表示完全相同的情况。因此编码层需要对每个单词生成上下文编码,这种编码会随着单词的上下文不同而发生改变,从而反映出单词在当前语句中的含义。
在深度学习中,为了实现上下文语义的理解,通常采用单词之间的信息传递。RNN是最常用的上下文编码生成结构,因为RNN利用相邻单词间的状态向量转移实现语义信息的传递。为了更有效地利用每个单词左右两个方向的语句信息,采用双向循环神经网络;而许多模型还采用多层RNN,用于提取更高级的上下文语义,获得更好的效果。
以下代码给出了多层双向RNN获得文本单词上下文编码的代码。RNN的输入为每个单词的编码,维度是word_dim。输出维度是2*state_dim,其中2表示RNN共有两个方向。
import torch
import torch.nn as nnclass Contextual_Embedding(nn.Module):# word_dim为词向量维度,state_dim为RNN状态维度,rnn_layer为RNN层数def __init__(self, word_dim, state_dim, rnn_layer):super(Contextual_Embedding, self).__init__()#多层双向GRU,输入维度word_dim,状态维度state_dimself.rnn = nn.GRU(word_dim, state_dim, num_layers=rnn_layer, bidirectional=True, batch_first=True) # 输入x为batch组文本,每个文本长度seq_len,每个词用一个word_dim维向量表示,输入维度为batch x seq_len x word_dim# 输出res为所有单词的上下文向量表示,维度是batch x seq_len x out_dimdef forward(self, x):# 结果维度batch x seq_len x out_dim,其中out_dim=2 x state_dim,包括两个方向res, _ = self.rnn(x) return resbatch = 10
seq_len = 20
word_dim = 50
state_dim = 100
rnn_layer = 2
x = torch.randn(batch, seq_len, word_dim)
context_embed = Contextual_Embedding(word_dim, state_dim, rnn_layer)
res = context_embed(x)
print(res.shape) # torch.Size([10, 20, 200])
研究者进一步发现,在大规模自然语言处理任务上进行预训练,然后将预训练模型中的循环神经网络参数用于机器阅读理解,可以获得明显的性能提升。如CoVe模型在大量机器翻译数据上训练seq2seq模型,然后将编码器部分的循环神经网络用于SQuAD数据集,F1分数提高4%左右。
综上所述,在编码层中,每个问题单词由词表向量、命名实体向量、词性向量、字符编码、上下文编码组成,而每个文章单词除了以上五种向量外,还有精确匹配编码。

交互层的输入是编码层的输出,即文章的单词向量(p1, p2, …,pm)和问题的单词向量(q1,q2,…qn)。为了对两部分的语义进行交互处理,一般采用注意力机制。
注意力机制最初应用在序列到序列模型中,它的输入包括一个单词向量x和一个单词向量组A=(a1,a2,…an)。注意力机制从向量x的角度对A进行总结,从而获得A所代表的语句与单词x相关的部分的信息。注意力机制的结果为向量xA,是向量组A的线性组合。其中,与x相关的A中单词获得相对较大的权重。
例如,如果x为“踢球”的向量表示,A为“我|喜欢|足球”的向量表示(a1,a2,a3),则注意力机制的结果是xA=0.1×a1+0.05×a2+0.85×a3。
在机器阅读理解中,可以使用注意力机制计算从文章到问题的注意力向量:基于对文章第i个词pi的理解、对问题单词向量组(q1,q2,…qn)的语义总结,得到向量piq。注意力函数需要反应pi和qj的相似度。一般而言,常见的注意力函数有:
内积函数
二次型函数
加法形式函数
双维度转换函数
获得每个qj的分数后,使用softmax函数进行归一化,得到权重。最后使用权重计算(q1,q2…qn)的加权和,即注意力机制的结果。
值得注意的是,交互注意力的结果向量个数是文章单词的个数m,而维度是问题单词的编码长度q1。每个注意力向量piq都是问题单词编码的线性组合,而系数来自文章和问题的语义相似度。以最简单的内积注意力函数为例,由于两个语义相近的词向量方向更为一致,所以注意力机制给予和文章单词i语义更相近的问题单词j更大的权重,从而达到交互信息的目的。
利用类似方法也可以获得从问题到文章的注意力向量。
在计算上下文编码时,循环神经网络RNN以线性方式传递单词信息。在这个过程中,一个单词的信息随着距离的增加而衰减,特别是当文章比较长时,靠前部分的语句和靠后部分的语句几乎没有进行有效的状态传递。但在一些文章中,要获得答案可能需要理解文章中若干段相隔较远的部分。
为了解决这个问题,可以使用自注意力机制。自注意力要计算一个向量组和自身的注意力向量: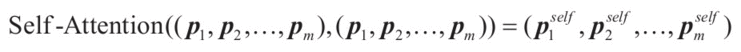
下面代码是自注意力计算的代码示例。其中使用参数矩阵w将原向量映射到隐藏层,然后计算内积得到注意力分数,这样做的好处是可以在向量维度较大时通过控制隐藏层的大小降低时空复杂度。
import torch
import torch.nn as nn
import torch.nn.functional as Fclass SelfAttention(nn.Module):# dim为向量维度,hidden_dim为自注意力计算的隐藏层维度def __init__(self, dim, hidden_dim):super(SelfAttention, self).__init__()# 参数矩阵Wself.W = nn.Linear(dim, hidden_dim) ''' x: 进行自注意力计算的向量组,batch x n x dim'''def forward(self, x):# 计算隐藏层,结果维度为batch x n x hidden_dimhidden = self.W(x)# 注意力分数scores,维度为batch x n x nscores = hidden.bmm(hidden.transpose(1, 2))# 对最后一维进行softmaxalpha = F.softmax(scores, dim=-1)# 注意力向量,结果维度为batch x n x dimattended = alpha.bmm(x) return attendedbatch = 10
n = 15
dim = 40
hidden_dim = 20
x = torch.randn(batch, n, dim)
self_attention = SelfAttention(dim, hidden_dim)
res = self_attention(x)
print(res.shape) # torch.Size([10, 15, 40])
在自注意力机制中,文本中所有的单词对(pi,pj),无论其位置远近,均直接计算注意力函数值。这使得信息可以直接在相隔任意距离的单词间交互,大大提高了信息的传递效率。而且每个单词计算注意力向量的过程都是独立的,可以并行计算提高运算速度。
在机器阅读理解的交互层中也常常使用编码层中的上下文编码技术。交互层可以交替使用互注意力、自注意力及上下文编码,以文章部分为例,互注意力机制可以获得问题的信息,自注意力机制可以获得文章内部所有单词之间的信息,上下文编码则可以使用RNN基于文章单词的位置信息进行语义的传递。通过这些步骤的反复使用可以使模型更好地理解单词、短语、句子、片段以及文章的语义信息,同事融入对问题的理解,从而提高预测答案的准确度。
由于交互层对于注意力和上下文的编码的使用比较灵活,也使其称为机器阅读理解模型发展中最多样、成果最丰富的一部分。例如2016年的机器阅读理解模型BiDAF在交互层使用了RNN->互注意力->RNN的结果;2017年的R-Net模型在交互层中使用了RNN->互注意力->RNN->自注意力->RNN的结构;2018年的fusionNe模型在交互层中采用了互注意力->RNN->自注意力->RNN的结果。
但我们也应该注意到,随着交互层结构的复杂化,容易导致参数过多、模型过深,引起梯度消失、梯度爆炸、难以收敛或过拟合等不利于模型优化的现象。因此一般建议可以从较少的层数开始,逐渐增加注意力和上下文编码的模块,并在雅正数据上观察效果,同时配合采用Dropout、梯度裁剪(gradient clipping)等辅助手段加速优化进程。
梯度裁剪是指计算梯度后,将所有导数按比例缩小直到其平方和小于某个定值R,或者将绝对值大于定值C的导师全部设置为C或-C。
输出层是机器阅读理解模型计算并输出答案的模块。经过编码层和交互层的计算,模型已经掌握了问题和文章的语义信息并进行了信息间的交互传递,具备了生成答案的条件。输出层的主要任务是根据任务要求的方式生成答案,并构造合理的损失函数便于模型在训练集上进行优化。
在经过交互层的处理后,问题中的n个单词均得到了向量表示,记作(q1,q2,…qn)。为了从文章中生成答案,通常将问题作为一个整体与文章中的单词进行匹配运算,因此需要用一个向量q表示整个问题,以方便后续处理。
3.1节中介绍了由词向量生成文本向量的3种方法:RNN最终状态、CNN和池化、含参加权和。这些方法都可以从问题中所有单词的向量表示(q1,q2,…qn)生成q。
区间式答案是指答案由文章中一段连续的语句组成。对于一篇长度为m个词的文章,可能的区间式答案有m(m-1)/2种。在实际数据中,标准答案的长度不会太长。例如在SQuAD中,大部分参赛队伍根据训练将答案最长长度限定在15个单词。但是即使限定答案的最长长度为L,可能的区间答案仍有越L*M种。如果将答案的选择视为分类问题,会造成类别数太多而难以进行有效的优化。因此对于区间型答案的机器阅读理解任务,模型的输出层应预测答案区间的开始位置和结束位置。
这里输出层对于所有单词计算两个得分,分别为第i个单词作为答案区间第一个词的可能性分数以及其作为答案区间最后一个词的可能性分数。之后利用softmax得出相应概率。
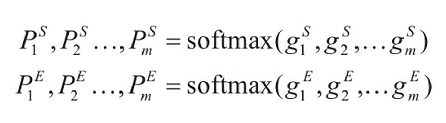
可以看出计算答案开始位置和结束位置的过程是独立的,因此也有模型尝试在两个计算过程之间传递信息。例如FusionNet模型在得到开始位置概率后,用单步循环神经网络GRU计算:

为GRU的输入,v是GRU的输出状态。然后利用v计算每个单词作为答案结束位置的得分,这样计算答案开始位置和结束位置的过程之间就有了关联。
由于预测答案的开始位置和结束位置均为多分类问题,因此可以采用交叉熵损失函数。如果正确答案在文章中的开始位置为i* ,结束位置为j* ,则相应的损失函数值为两个多分类问题的交叉熵之和。
模型在预测时需要找到概率最大的一组开始位置和结束位置iR与jR,并以这个区间中所有单词组成的语句作为预测答案,即
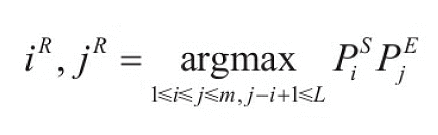
其中,L为答案区间的最大限定长度。如图4-7所示,限定答案最长长度为L=2个单词,则最终选取最优答案“太阳系中心”。

下面代码为根据开始位置概率和结束位置概率求出概率最大的区间。其中prob_s大小为m。表示文本中以每个单词作为答案开始位置的概率;prob_e大小为m,表示文本中以每个单词作为答案结束位置的概率;L是答案中最多可以包含的单词个数。
import torch
import numpy as np
import torch.nn.functional as F# 设文本共m个词,prob_s是大小为m的开始位置概率,prob_e是大小为m的结束位置概率,均为一维PyTorch张量
# L为答案区间可以包含的最大的单词数
# 输出为概率最高的区间在文本中的开始和结束位置
def get_best_interval(prob_s, prob_e, L):# 获得m×m的矩阵,其中prob[i,j]=prob_s[i]×prob_e[j]prob = torch.ger(prob_s, prob_e) # 将prob限定为上三角矩阵,且只保留主对角线及其右上方L-1条对角线的值,其他值清零# 即如果i>j或j-i+1>L,设置prob[i, j] x 0prob.triu_().tril_(L - 1) # 转化成为numpy数组prob = prob.numpy()# 获得概率最高的答案区间,开始位置为第best_start个词, 结束位置为第best_end个词best_start, best_end = np.unravel_index(np.argmax(prob), prob.shape)return best_start, best_endsent_len = 20
L = 5
prob_s = F.softmax(torch.randn(sent_len), dim=0)
prob_e = F.softmax(torch.randn(sent_len), dim=0)
best_start, best_end = get_best_interval(prob_s, prob_e, L)
print(best_start, best_end)
自由式答案是指答案可以为任何自然语言形式,不需要其中所有单词均来自文章。生成自由式答案的过程就是自然语言生成的过程。因此对于这种任务,模型的输出层基本采用seq2seq模型。
编码器从交互层获得文本中每个单词的向量(p1,p2,…,pm),然后使用双向循环神经网络处理文本中的所有单词,第i个单词产生输出状态h。这里可以使用问题向量q作为RNN的初始状态。
为了减少代码量,这里假设RNN的状态维度和单词词表向量维度word_dim相同,且编码器使用单向RNN。实际使用中,可以用全连接层nn.Lin ear转化任何两个不同的维度。
生成式seq2seq模型代码:包括编码器、解码器和注意力机制。解码器的词表和全连接层复用了编码层使用的词表embed。在解码过程,每一步均利用Attention函数代码计算上下文向量context,并于解码器RNN状态new_state合成新的状态。这个状态既传入下一个RNN单元,也用于解码得到该位置模型预测词表中每个单词的分数。同时,解码器使用RNN单元GRUCell,因为每一步只需要预测下一个位置的单词。解码过程使用teacher-forcing,即利用标准答案的单词预测下一个位置的单词。
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F'''a: 被注意的的向量组,batch x m x dim x: 进行注意力计算的向量组,batch x n x dim
'''
def attention(a, x):# 内积计算注意力分数,结果维度为batch x n x mscores = x.bmm(a.transpose(1, 2))# 对最后一维进行softmaxalpha = F.softmax(scores, dim=-1)# 注意力向量,结果维度为batch x n x dimattended = alpha.bmm(a) return attendedclass Seq2SeqOutputLayer(nn.Module):# word_dim为交互层输出的问题向量和文章单词向量的维度,以及词表维度# embed为编码层使用的词表,即nn.Embedding(vocab_size, word_dim)# vocab_size为词汇表大小def __init__(self, embed, word_dim, vocab_size):super(Seq2SeqOutputLayer, self).__init__()# 使用和编码层同样的词表向量self.embed = embedself.vocab_size = vocab_size# 编码器RNN,单层单向GRU,batch是第0维self.encoder_rnn = nn.GRU(word_dim, word_dim, batch_first=True)# 解码器RNN单元GRUself.decoder_rnncell = nn.GRUCell(word_dim, word_dim)# 将RNN状态和注意力向量的拼接结果降维成word_dim维self.combine_state_attn = nn.Linear(word_dim + word_dim, word_dim)# 解码器产生单词分数的全连接层,产生一个位置每个单词的得分self.linear = nn.Linear(word_dim, vocab_size, bias=False)# 全连接层和词表共享参数self.linear.weight = embed.weight# x: 交互层输出的文章单词向量,维度为batch x x_seq_len x word_dim# q: 交互层输出的问题向量,维度为batch x word_dim# y_id:真值输出文本的单词编号,维度为batch x y_seq_len# 输出预测的每个位置每个单词的得分word_scores,维度是batch x y_seq_len x vocab_sizedef forward(self, x, q, y_id):# 得到真值输出文本的词向量,维度为batch x y_seq_len x word_dimy = self.embed(y_id) # 编码器RNN,以问题向量q作为初始状态# 得到文章每个位置的状态enc_states,结果维度是batch x x_seq_len x word_dim# 得到最后一个位置的状态enc_last_state,结果维度是1 x batch x word_dimenc_states, enc_last_state = self.encoder_rnn(x, q.unsqueeze(0))# 解码器的初始状态为编码器最后一个位置的状态,维度是batch x word_dimprev_dec_state = enc_last_state.squeeze(0)# 最终输出为每个答案的所有位置各种单词的得分scores = torch.zeros(y_id.shape[0], y_id.shape[1], self.vocab_size)for t in range(0, y_id.shape[1]):# 将前一个状态和真值文本第t个词的向量表示输入解码器RNN,得到新的状态,维度batch x word_dimnew_state = self.decoder_rnncell(y[:,t,:].squeeze(1), prev_dec_state) # 利用3.4节的attention函数获取注意力向量,结果维度为batch x word_dimcontext = attention(enc_states, new_state.unsqueeze(1)).squeeze(1)# 将RNN状态和注意力向量的拼接结果降维成word_dim维, 结果维度为batch x word_dimnew_state = self.combine_state_attn(torch.cat((new_state, context), dim=1))# 生成这个位置每个词表中单词的预测得分scores[:, t, :] = self.linear(new_state)# 此状态传入下一个GRUCellprev_dec_state = new_statereturn scores# 100个单词
vocab_size = 100
# 单词向量维度20
word_dim = 20
embed = nn.Embedding(vocab_size, word_dim)
# 共30个真值输出文本的词id,每个文本长度8
y_id = torch.LongTensor(30, 8).random_(0, vocab_size)
# 此处省略编码层和交互层,用随机化代替
# 交互层最终得到:
# 1) 文章单词向量x,维度30 x x_seq_len x word_dim
# 2) 问题向量q,维度30 x word_dim
x = torch.randn(30, 10, word_dim)
q = torch.randn(30, word_dim)
# 设定网络
net = Seq2SeqOutputLayer(embed, word_dim, vocab_size)
optimizer = optim.SGD(net.parameters(), lr=0.1)
# 获得每个位置上词表中每个单词的得分word_scores,维度为30 x y_seq_len x vocab_size
word_scores = net(x, q, y_id)
# PyTorch自带交叉熵函数,包含计算softmax
loss_func = nn.CrossEntropyLoss()
# 将word_scores变为二维数组,y_id变为一维数组,计算损失函数值
# word_scores计算出第2、3、4...个词的预测,因此需要和y_id错开一位比较
loss = loss_func(word_scores[:,:-1,:].contiguous().view(-1, vocab_size), y_id[:,1:].contiguous().view(-1))
print('loss1 =', loss)
optimizer.zero_grad()
loss.backward()
optimizer.step()
word_scores = net(x, q, y_id)
loss = loss_func(word_scores[:,:-1,:].contiguous().view(-1, vocab_size), y_id[:,1:].contiguous().view(-1))
print('loss2 =', loss) # loss2应该比loss1小











 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 