本文由编程笔记#小编为大家整理,主要介绍了机器学习中的线性模型相关的知识,希望对你有一定的参考价值。
一、基本形式
给定由d个属性描述的示例x=(x1, x2, ..., xd),则线性模型(linear mdel)的预测函数f(x)是属性的线性组合,用向量形式表示为f(x) = wTx + b。
线性模型蕴涵了机器学习中一些重要的基本思想。通过在线性模型中引入层次结构或高维映射,就可以得到更为强大的非线性模型(nonlinear model)。此外,线性模型也具有很好的可解释性(comprehensibility)。
针对回归任务、二分类任务、多分类任务,下文总结了几种经典的线性模型。
二、线性回归
给定数据集D = {(x1, y1), (x2, y2), ..., (xm, ym)},其中xi = (xi1; xi2; ...; xid), yi为实数。线性回归(linear regression)试图学得一个线性模型以尽可能准确地预测实值输出标记(试图学得f(xi) = wxi + b,使得f(xi) ≈ yi)。
对于输入的属性,若k个属性间存在序关系,则可以通过连续化转化为连续值;若不存在序关系,则通常转化为k维向量。
对于输入属性数目只有一个的情况,可以通过最小化均方误差(亦称为平方损失函数,square loss)来确定w和b,即
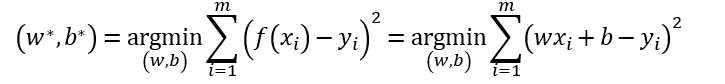
其中(w*, b*)表示w和b的解。
使用均方误差,是因为它对应了常用的”欧式距离“(Euclidean distance)。基于均方误差最小化来求解模型的方法称为“最小二乘法”(least square method)。在线性回归中,求解w和b使得E(w,b)最小的过程被称为线性回归模型的最小二乘“参数估计”(parameter estimation)。
求解方法:将E(w,b)分别对w和b求导,得到
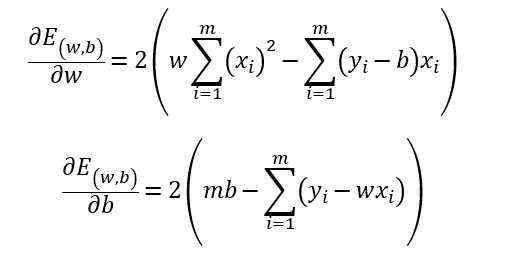
令两式为零,即可得到w和b最优解的闭式(closed-form)解
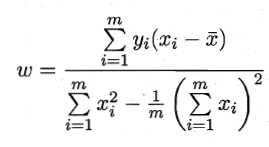
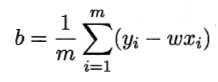
其中
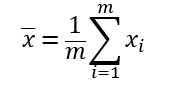
更一般的情形,设样本由d个属性描述,此情形被称为“多元线性回归”(multivariate linear regression)。
类似地,可以用最小二乘法对向量w和b进行估计。设
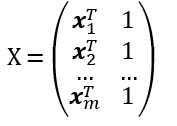
则X是一个m×(d+1)大小的矩阵。记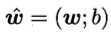 ,标记y = (y1; y2; ...; ym)。则类似地,有
,标记y = (y1; y2; ...; ym)。则类似地,有
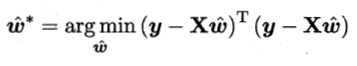
令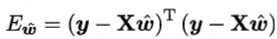 ,对
,对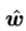 求导得
求导得
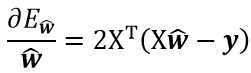
令上式 = 0。当XTX是满秩矩阵时,有
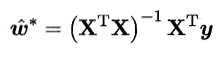
否则,利用最小二乘法,求解方程组
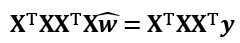
此时可能会解出多个。选择哪一个解输出,将由学习算法的归纳偏好决定,常见的做法是引入正则化(regularization)项。
考虑单调可微函数g,令y=g-1(wTx + b),则得到“广义线性模型”(generalized linear model),g称为“联系函数”(link function)。例如,当g(x)=lnx时,对应的模型即为对数线性回归。 顺便一提,对广义线性模型的参数估计,常通过加权最小二乘法或极大似然法进行。
三、对数几率回归
对于分类任务,可以采用广义线性模型。为此,希望找到某个可谓函数,将分类任务的真实标记y与线性回归模型的预测值联系起来。比如说,考虑二分类任务,十分理想的是“单位阶跃函数”(unit-step function, 亦称Heaviside function)
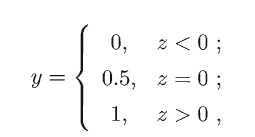
但是单位阶跃函数并不可谓,不能作为联系函数。因此,希望找到一定程度上近似单位阶跃函数的“替代函数”(surrogate function),并希望它单调可谓。
一个选择是“对数几率函数”(logistic function),其定义如下
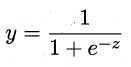
将对数几率函数作为g-1(x) 代入y=g-1(wTx + b),即得到
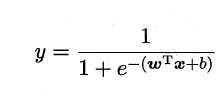
经过变换得到
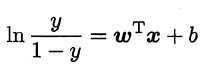
将y视为样本x作为正例的可能性,则1-y是其反例的可能性,两者的比值称为“几率”(odds),反映了x作为正例的相对可能性。对几率取对数,则得到“对数几率”(log odds, 亦称logit)。因此,上式实际上是在用线性回归模型的预测结果去逼近真实标记的对数几率,其对应模型称为“对数几率回归”(logistic regression, 亦称logit regression)。虽然名字是回归,实际则是一种分类学习方法。
对数几率回归的优点在于:可以直接对分类可能性建模,无需事先假设数据分布; 不仅可以预测出类别,还可以预测近似概率;对率函数任意阶可导,有很好的数学性质。
在对数几率回归模型中,若将y视为类后验概率估计p(y=1|x),则有
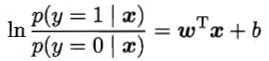
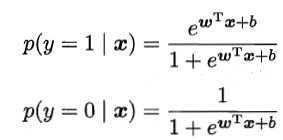
于是,可以用“极大似然法”(maximum likelihood method)估计w和b。详细计算过程见书p.59。
四、线性判别分析
“线性判别分析”(Linear Discriminant Analysis, LDA)在二分问题上最早由[Fisher, 1936]提出,因此亦称为“Fisher判别分析”。
LDA的思想是:设法将样例投影到一条直线上,使得同类样例的投影点尽可能接近、异样例投影点尽可能远离;对新样本进行分类时,将其投影到直线上,再根据投影点的位置来确定新样本的分类。
给定数据集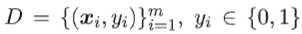 ,令Xi, μi, ∑i分别表示第i类示例的集合、均值向量、协方差矩阵。将数据投影到直线ω上。则欲使同类样例投影点尽可能接近,即让
,令Xi, μi, ∑i分别表示第i类示例的集合、均值向量、协方差矩阵。将数据投影到直线ω上。则欲使同类样例投影点尽可能接近,即让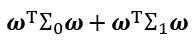 尽可能小;要让不同类样例投影点尽可能远离,即让
尽可能小;要让不同类样例投影点尽可能远离,即让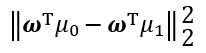 尽可能大。同时考虑而者,则得到欲最大化目标
尽可能大。同时考虑而者,则得到欲最大化目标
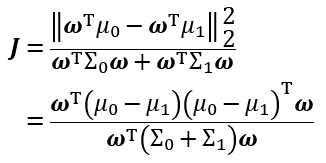
定义“类内散度矩阵”(within-class scatter matrix)
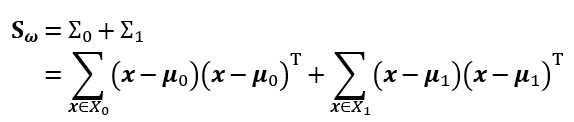
以及“类间散度矩阵”(between-class scatter matrix)
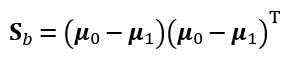
于是
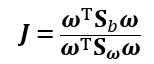
此即LDA欲最大化的目标,即Sω与Sb的“广义瑞利商”(generalized Rayleigh quotient)。
可以用拉格朗日乘子法来确定ω,解得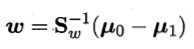 。具体过程详见书pp.61-63。
。具体过程详见书pp.61-63。
五、多分类学习
现实中常遇到多分类学习任务。基于一些基本策略,可以利用二分类学习器来解决多分类问题。不失一般性,考虑N个类别C1, C2, ..., CN,一个基本思路是“拆解法”,即将多分类任务拆解为多个二分类任务。
最经典的拆分策略有三种:“一对一”(One vs. One, OvO),“一对其余”(One vs. Rest, OvR),以及“多对多”(Many vs. Many, MvM)。
OvO:将N个类别两两匹配,在训练阶段为每一组配对训练一个分类器,测试阶段则将新样本同时提交给所有分类器。最终通过投票产生被预测得最多的类别作为最终分类结果。
OvR:将每个样例作为正例,其余样例作为反例来训练N个分类器。测试阶段,若仅有一个分类器预测为正类,则对应类别标记作为最终结果;若有多个分类器预测为正类,则考虑各分类器的预测置信度,选择置信度大的标记作为分类结果。
比较:OvO的存储开销及测试时间开销高于OvR;但当类别很多时,OvO的训练时间开销比OvR小。预测性能则取决于数据分布,多数情形下两者差不多。
MvM:每次将若干个类作为正类,若干个其它类作为反类。值得注意的是,正反例的构造需要特殊的设计,不可随意选取。
一种常用的MvM技术是“纠错输出码”(Error Correcting Output Code, ECOC)。ECOC工作步骤分为两步:
- 编码:对N个类别做M次划分,每次划分将一部分归为正类,另一部分归为反类,得到M个训练集。
- 解码:M个分类器对分类样本进行预测,预测标记组成一个编码。将此编码与每个类别各自的编码比较,返回其中距离最小的类别作为最终预测结果。
类别划分通过“编码矩阵”(coding matrix)指定。常见的编码矩阵的形式主要有:
- 二元码:将每个类别分别指定为正类和反类
- 三元码:在正反类之外,还可以指定“停用类”
概念比较抽象,有点难以理解。看一下书中给出的示例图,可以由更直观的感受。
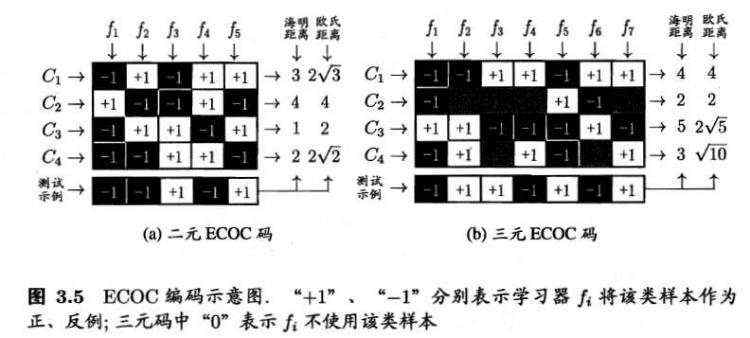
从图中可以看出,在测试阶段,ECOOC编码对分类器的错误有一定的容忍能力,这也是其名“纠错输出码”的来由。
一般来说,对同一个学习任务,ECOOC编码越长,纠错能力越强,代价是分类器增多带来的计算、存储开销;以及对于有限类别,组合数有限,编码太长也会失去意义。另一方面,对于长度相同的编码,距离越远,纠错能力越强。编码较小时可以此原则确定理论最优编码;而当编码过长时,确定最优编码则成为NP-难问题。不过,并非编码的理论性质越好,分类器性能就越好。比如:一个理论性质很好、但导致的二分类问题较难的编码,与另一个理论性质稍差、但导致的而分类问题比较简单的编码相比,最终产生的模型孰强孰弱很难说。
六、类别不平衡问题
类别不平衡(class-imbalance)是指分类任务中不同类别的训练样例数差别很大的情况。例如,在拆分法解决多分类学习任务时,即便原始问题的不同类别的训练数据相当,在产生的而分类任务中仍然可能出现类别不平衡现象。因此有必要了解对类别不平衡的处理办法。
在线性分类器中,一个基本策略是“再缩放”(rescaling),也称“再平衡”(rebalance)。其思想是:当训练集中正、反例不同时,令m+表示正例数,m-表示反例数,则观测几率为m+ / m-。假设训练集是真实样本总体的无偏采样,则观测几率就代表了真实几率。因此,当y / (1 - y) > m+ / m-时,预测为正例。即令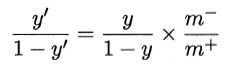 ,再将阈值设为1,当预测值大于1时预测为正例,即可。顺便一提,再缩放也是“代价敏感学习”(cost-sensitive learning)的基础。
,再将阈值设为1,当预测值大于1时预测为正例,即可。顺便一提,再缩放也是“代价敏感学习”(cost-sensitive learning)的基础。
然而在现实中,“训练集是真实样本总体的无偏采样”的假设往往并不成立,因此未必能有效地基于训练集的观测几率推断真实几率。现有技术有三类解决办法:
- 欠采样(undersampling):去除一些反例使得正、反例数目相近,再进行学习。
- 过采样(oversampling):增加一些正例使得正、反例数目相近,再进行学习。需要考虑过拟合问题。代表性算法是SMOTE,通过对训练集里的正例进行插值来产生额外的正例。
- “阈值移动”(threshold-moving):基于原始训练集学习,但在预测时将再缩放策略嵌入到决策过程中。










 京公网安备 11010802041100号
京公网安备 11010802041100号