目录

思维导图转载自:https://blog.csdn.net/liuyan20062010/article/details/72842007
导入:
机器学习的核心价值观:根据一些已观察到的证据来推断未知。其中基于概率的模型将学习任务归结为计算变量的概率分布;
生成式模型:先对联合分布P(Y,R,O)进行建模,从而再来求解后验概率,例如:贝叶斯分类器先对联合分布进行最大似然估计,从而便可以计算类条件概率;
判别式模型:直接对条件分布P(Y,R|O)进行建模。
推断:利用已知变量推测未知变量;即由联合分布P(Y,R,O)或条件分布P(Y,R|O)推出条件概率分布P(Y,O)
概率图模型(probabilisticgraphical model)是一类用图来表达变量相关关系的概率模型。概率图模型,以图为表示工具,如一个结点表示一个或一组随机变量,结点之间的边表示变量间的概率相关关系,即变量关系图。
根据边的性质不同,概率图模型大致可分为两类:
1)使用有向无环图表示变量间的依赖关系,称为有向图模型或贝叶斯网(Bayesian network);
2)使用无向图表示变量间的相关关系,称为无向图模型或马尔可夫网(Markov network);
这里上一个概率图模型的思维导图:

隐马尔科夫模型
统计学习方法里面的解释:http://www.cnblogs.com/QueenJulia/articles/8940010.html
隐马尔可夫模型(Hidden Markov Model,HMM)是结构最简单的动态贝叶斯网(dynamic Bayesian network),是著名的有向图模型,主要用于时序数据建模,在语音识别、自然语言处理等领域有广泛应用。
1)HMM结构信息
HMM的变量可分为两组:
- 第一组是状态变量{y1,y2,…,yn},其中yi∈Y表示第i时刻的系统状态,通常假定状态变量是隐藏的、不可观测的,因此状态变量也叫隐变量(hidden variable);
- 第二组是观测变量{x1,x2,…,xn},其中xi∈X表示第i时刻的观测值。
在HMM中,系统通常在多个状态{ s1,s2,…,sN }之间转换,因此状态变量yi的取值范围Y(状态空间)通常是有N个可能取值的离散空间。观测变量xi可以是离散型也可以使连续型,这里仅考虑离散型观测变量,并假定其取值范围X为{ o1,o2,…,oM}。
HMM图结构如下:

图中箭头表示了变量间的依赖关系。在任一时刻,观测变量的取值仅依赖于状态变量,即xt由yt确定;与其他状态变量及观测变量的取值无关。t时刻的状态yt仅依赖于t-1时刻的状态yt-1,与其余n-2个状态无关。此为马尔科夫链(Markov chain),即:系统下一时刻的状态仅由当前状态决定,不依赖于以往的任何状态。基于这种依赖关系,所有变量的联合概率分布为:

确定隐马尔科夫模型 :
:




产生观测序列过程:

实际应用中关注的三个问题:


马尔科夫随机场
统计学习方法中的解释:http://www.cnblogs.com/QueenJulia/articles/8940012.html
马尔科夫随机场是典型的马尔科夫网,无向图模型:

势函数(因子):
定义在变量子集上的非负实函数,主要用于定义概率分布函数或者说用定量刻画变脸记Xq中半年之间的相关关系;且在所骗号的变量取值上有较大的函数值;

团:
图中结点的一个子集中,若其中任意两结点都有边连接,则该结点子集为一个“团;”
极大团:
若在一个团中加入另外任何一个节点都不再构成团,该团为“极大团”;
联合概率(基于团定义):

联合概率(基于极大团定义)

注:
若团Q不是极大团,则必被一个极大团Q*所包含;
分离集:

 得出:
得出:


条件随机场CRF
定义:
若G=表示结点与标记变量y中元素一一对应的无向图,yv表示与结点v的标记变量,n(v)表示结点v的邻接结点,若图G的每个变量yv都满足马尔可夫性,则(y,x)构成一个条件随机场。
马尔可夫性:

链式条件随机场chain-structured CRF:

条件概率

转移特征函数:刻画相邻标记变量之间的相关关系以及观测序列对他们的影响;
- 主要判定两个相邻的标注是否合理,例如:动词+动词显然语法不通;
状态特征函数:刻画观测序列对标记变量的影响;
- 主要判定观测值与对应的标注是否合理,例如: ly结尾的词–>副词较合理。
学习与推断
边际化:
概率图模型的推断方法大致分为两类:
- 精确推断方法:变量消去、信念传播;
- 近似推断方法:MCMC采样、变分推断;
精确推断
精确推断的实质是一种动态规划算法,他利用图模型所描述的条件独立性来削减计算目标概率值所需的计算量。
变量消去

(1)有向图模型:

(2)对无向图同样适用!

缺点:
- 若需要计算多个边际分布,重复使用变量消去会造成大量的冗余计算。
信念传播
解决求解多个边际分布的重复计算问题:将变量消去法中的求和操作看做一个消息传递的过程;

信念传播算法步骤:

信念传播算法图示:

近似推断
两大类方法:
- 采样:采用随机化方法完成近似;
- 确定性近似:典型代表变分推断;
采样
可以参考的博客:https://www.cnblogs.com/ironstark/p/5229085.html
典型代表:马尔科夫链蒙特卡罗MCMC
目的:通过构造‘平稳分布为p的马尔科夫链’来产生样本;
平稳分布:假设平稳马尔科夫链T的状态转移概率为T(x'|x),t时刻状态的分布为P(x^t),则若在某个时刻马尔科夫链满足平稳条件:

则p(x)是该马尔科夫链的平稳分布
步骤:
- 构造马尔科夫链;
- 逼近(收敛)至平稳分布恰为带估计参数的后验分布;
- 用马尔科夫链产生符合该后验分布的样本,并基于这些样本进行估计
重点:马尔科夫链转移概率的构造
MH(MCMC代表):基于“拒绝采样”来逼近平稳分布p;

MC算法特例:吉布斯采样

变分推断
附变分推断的知乎讨论:https://www.zhihu.com/question/41765860
目标:通过使用已知简单分布来逼近需推断的复杂分布,并通过限制及时发布的类型,从而得到一种局部最优、但具有确定街的近似后验分布。
盘式记忆:

(b)中所能观测到的变量x的联合分布的概率密度函数:

对应的对数似然函数:

推断和学习的任务:
由观察到的变量x来估计隐变量z和分布参数变量Θ,即求解P(z|x,Θ)
解决方法:
EM算法
总结:
1、如何拆解隐变量;
2、假设各变量子集服从的分布;
3、服从的最优分布;
4、EM算法;
话题模型
生产式有向图模型,主要处理离散型数据(如文本集合)。
隐狄利克雷分配模型(Latent Dirichlet Allocation,简称LDA)
基本概念:词(word)、文档(document)、话题(topic)。
词:最基本的离散单元;
文档:待处理的数据对象,由一组词组成,词在文档中不计顺序;(词袋bag-of-words)
话题:表示一个概念,具体表现为一系列相关的词,以及它们该概念下出现的概率。这组词具有较强的相关关系。
在现实任务中,一般我们可以得出一个文档的词频分布,但不知道该文档对应着哪些话题,LDA话题模型正是为了解决这个问题。
具体来说:LDA认为每篇文档包含多个话题,且其中每一个词都对应着一个话题。因此可以假设文档是通过如下方式生成:

这样一个文档中的所有词都可以认为是通过话题模型来生成的,当已知一个文档的词频分布后(即一个N维向量,N为词库大小),则可以认为:每一个词频元素都对应着一个话题,而话题对应的词频分布则影响着该词频元素的大小。
LDA变量关系:

因此很容易写出LDA模型对应的联合概率函数:

补充:
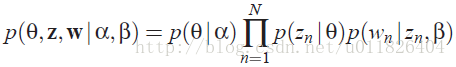
从上图可以看出,LDA的三个表示层被三种颜色表示出来:
corpus-level(红色): α和β表示语料级别的参数,也就是每个文档都一样,因此生成过程只采样一次。
document-level(橙色): θ是文档级别的变量,每个文档对应一个θ。
word-level(绿色): z和w都是单词级别变量,z由θ生成,w由z和β共同生成,一个单词w对应一个主题z。
通过上面对LDA生成模型的讨论,可以知道LDA模型主要是想从给定的输入语料中学习训练出两个控制参数α和β,当学习出了这两个控制参数就确定了模型,便可以用来生成文档。其中α和β分别对应以下各个信息:
α:分布p(θ)需要一个向量参数,即Dirichlet分布的参数,用于生成一个主题θ向量;
β:各个主题对应的单词概率分布矩阵p(w|z)。
把w当做观察变量,θ和z当做隐藏变量,就可以通过EM算法学习出α和β,求解过程中遇到后验概率p(θ,z|w)无法直接求解,需要找一个似然函数下界来近似求解,原作者使用基于分解(factorization)假设的变分法(varialtional inference)进行计算,用到了EM算法。每次E-step输入α和β,计算似然函数,M-step最大化这个似然函数,算出α和β,不断迭代直到收敛。













 京公网安备 11010802041100号
京公网安备 11010802041100号