作者:winnie198808616 | 来源:互联网 | 2023-07-21 20:25
所属知识点:Machine Learning:Feature Engineering
归纳和总结机器学习技术的库:ViolinLee/ML_notes。该库主要内容是我的机器学习笔记,同时挑选和收集各类与机器学习技术相关的高质量资源,欢迎大家关注和Star!会一直更新下去。
使用滴滴云AI大师码【0212】消费GPU有9折优惠哦!
(1)基础概念
特征(Feature):特征是所有独立单元共享的属性,是进行分析或预测的对象。只要对模型有用,任何属性都可以是特征。在某个问题背景下,特征(而不是属性)的目的将更容易理解。“A feature is a characteristic that might help when solving the problem”,我认为这句话的内涵是:特征只有在某个具体需要解决的问题下讨论才具有意义。
特征的重要性:数据中的特征对预测模型(predictive models)十分重要,并且会影响将要实现的结果。特征的质量和数量对模型的好坏有很大影响。“特征越好,结果越好”这并非完全正确,因为结果还取决于模型和数据,而不仅仅是所选的特征。但选择正确的特征仍非常重要。更好的特征可以产生更简单、更灵活的模型,并且通常会产生更好的结果。
DataRobot首席数据科学家、在2012-2013年Kaggle榜上排名第一的Xavier Conort曾说过,团队使用的算法在Kagglers中是十分常规的。他们将大多数精力花在特征工程上。他们也非常小心地放弃了可能会使模型产生过拟合的特征。“一些机器学习项目成功了而另外一些却失败了,是什么导致了这种差别呢?很简单,最关键的因素出现在他们所使用的特征上 ”,《主算法》作者Pedro Domingos的回答更为直接。
特征相关性(Feature relevance):关于某个具体特征,它可能是强相关的(即该特征具有任何其他特征中不存在的信息)、相关的、弱相关的(包含其他特征的某些信息)或不相关的。创建大量特征是很重要的,后续可以使用特征选择来防止过拟合。
特征爆炸(Feature explosion):功能组合(Feature combinations)或特征模板(Feature templates)都可能导致功能爆炸,这两种情况都可能导致特征数量快速增长。有一些解决方案可以帮助避免特征爆炸,例如:正则化(regularization)、内核方法(kernel method)、特征选择(feature selection)。
(2)特征工程
特征工程是利用数据的领域知识来创建提供给机器学习算法训练的特征的过程。特征工程是机器学习应用的基础,既困难又昂贵。自动特征学习可以避免手工特征工程的需要。特征工程是一个非正式的话题,但在应用机器学习中却被认为是必不可少的,因为原始数据中通常有大量的特征,这是不可能全部处理的。特征工程消除了噪声,提高了模型的精度。它优化了训练过程,推理过程,消除了过拟合。Andrew Ng曾说过:“创造特征是很困难的,即耗时,还需要专业知识。‘应用机器学习’基本上是特征工程”。
特征工程的流程:
- 头脑风暴;
- 决定创建哪些特征;
- 创建特征;
- 检查特征如何与模型一起工作;
- 必要时改进特征;
- 回到头脑风暴创建更多特征,直到工作完成。
特征工程常见手段:
- 注入领域知识
- 创建交互功能
- 合并稀疏类
- 添加虚拟变量
- 删除无用的特征
自动特征工程:自动特征工程已成为学术界研究的一个新兴课题。2015年,麻省理工学院的研究人员提出了深度特征合成算法(Deep Feature Synthesis algorithm),并证明了其在在线数据科学竞赛中的有效性,该算法击败了615/906个人类团队。IBM的研究人员表示,自动特征工程“有助于数据科学家缩短数据探索时间,使他们能够在短时间内尝试并错误地提出许多想法。另一方面,它使不熟悉数据科学的非专家能够快速地从他们的数据中提取价值,只需花费很少的精力、时间和成本。”
(3)特征提取:
在机器学习、模式识别和图像处理中,特征提取从最初的一组测量数据开始,构建旨在提供信息且非冗余的派生值(特征),以促进后续的学习和泛化过程。在某些情况下,特征还能产生更好的、人类能够理解的解释。特征提取是一个降维过程,将原始变量的初始集合降维至更易于管理的组别(特征)进行处理,同时仍然准确、完整地描述原始数据集。
当一个算法的输入数据太大而不便处理,并且可能是冗余时(例如,不同单位下的相同测量),则可以将其转换为一组简化的特征(也称为特征向量)。确定初始特征子集称为特征选择。所选特征将包含来自输入数据的相关信息,因此可以使用这种简化的表示来执行所需的任务,而不是使用完整的初始数据。
特征提取包括减少描述一组大数据所需的资源量。在对复杂数据进行分析时,主要问题之一是涉及的变量数量。对大量的变量进行分析通常会占用大量内存和计算能力,同时也可能导致分类算法对训练样本过拟合,难以泛化到新样本。特征提取是构造变量组合以解决上述问题的方法的一个通用术语,同时特征提取仍然以足够的精度描述数据。许多机器学习实践者认为,适当优化的特征提取是构建有效模型的关键。
使用构建的依赖于应用的特征集合(通常由专家构建)可以改进结果,一种这样的过程称为特征工程。或者,也可以使用通用的降维技术,例如:
- 独立成分分析 Independent component analysis (ICA)
- 等距映射 Isomap
- 核主成分分析 Kernel PCA
- 潜在语义分析 Latent semantic analysis
- 偏最小二乘 Partial least squares ( PLS)
- 主成分分析 Principal component analysis(PCA)
- 多因子降维法 Multifactor dimensionality reduction
- 非线性降维 Nonlinear dimensionality reduction
- Multilinear Principal Component Analysis
- Multilinear subspace learning
- Semidefinite embedding(SDE)
- 自动编码器 Autoencoder
特征提取的实际应用包括:
- Autoencoder — 自动编码器的作用是以无监督方式学习有效的数据编码。利用特征提取技术,通过学习原始数据集的编码,得到新的编码特征,从而识别编码数据中的关键特征。
- Bag-of-Words — 一种自然语言处理技术,提取句子、文档、网站等使用的单词(特征),并按使用频率对其进行分类。这种技术也可以应用于图像处理。
- Image Processing — 用于检测数字图像或视频中的形状、边缘或运动等特征的算法。
(4)特征选择
在机器学习和统计中,特征选择,又称变量选择、属性选择或变量子集选择,是选择相关特征(变量、预测器)子集用于模型构造的过程。简要地说就是:检测相关特征,摒弃冗余特征,获得特征子集,从而以最小的性能损失更好地描述给出的问题。(注意:这里的相关指的是单个特征的Relevant,而不是特征间的Correlation。)
使用特征选择技术主要有四个原因:① 简化模型,使研究人员/用户更容易理解这些模型;② 缩短训练时间;③避免维数灾难(the curse of dimensionality);④ 通过减少过拟合来增强泛化能力。
使用特征选择技术的前提是,数据包含一些冗余(Redundant) 或不相关(Irrelevant)的特征,因此可在不造成大量信息丢失的情况下删除这些特征。冗余和不相关是两个截然不同的概念,一个相关特征在与另一个相关特征强相关的情况下可能是冗余的。
应将特征选择与特征提取区分开来。特征提取根据原始特征的功能创建新特征,而特征选择返回特征的子集。特征选择技术常用于特征多、样本(或数据点)相对较少的领域。应用特征选择的典型案例包括对文字和DNA微阵列数据的分析,其中有成千上万的特征和几十到数百个样本。
(5)数据降维
指采用某种映射方法,将原高维空间中的数据点映射到低维度的空间中。降维的本质是学习一个映射函数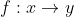 ,其中
,其中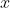 是原始数据点的表达,目前最多使用向量表达形式。
是原始数据点的表达,目前最多使用向量表达形式。 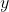 是数据点映射后的低维向量表达,通常的维度小于的维度(当然提高维度也是可以的)。
是数据点映射后的低维向量表达,通常的维度小于的维度(当然提高维度也是可以的)。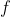 可能是显式的或隐式的、线性的或非线性的。
可能是显式的或隐式的、线性的或非线性的。
关于数据降维详见后续文章。
读到这里,大家对特征工程、特征提取、特征选择应该有了一些认识。但是对它们之间的区别和联系可能还是不太清晰的。事实上,在介绍上述概念的时候,有些内容已经谈到了它们之间的联系,我也特意有用下划线标注主来。
总的来说,三者的特点如下:
- 特征工程:从已有数据中创建新的特征;注入领域知识。
- 特征提取:将原始数据转换为特征,会创建新特征;降维过程;
- 特征选择:选择特征子集;不创建新特征。
可以看出,特征工程和特征提取都是将原始数据转换为适合建模的特征,有些情况下可以互换概念,但特征提取更注重数据降维。特征选择不创建新特征,注重删除无用特征。有时候还会看到特征转换(Feature transfomation),它属于数据转换,目的是提高算法的精度。特征提取主要用在图像、信号处理和信息检索领域,在这些领域,模型精确度比模型可解释性要重要;特征选择主要用于数据挖掘,如文本挖掘,基因分析和传感器数据处理。为了更直观地体现区别联系,下面给出一些例子:
① 特征提取和特征工程(从中提取出信息)
- 文本(ngrams、word2vec、tf-idf)
- 图像(CNN)
- 地理空间数据(经纬度)
- 日期和时间(日、月、周、年)
- 时间序列、网络
- 数据降维
② 特征选择(基于选择的特征构建模型)
- 统计方法
- 交叉验证
- 特征加权算法(ReliefF)
③ 特征转换(转换为有意义的)
- 规范化和改变分布(例如缩放)
- 交互作用
- 填写缺失值(中间值填充等)
Resources & References
资源及参考
[1] WikiPedia. Feature engineering,Feature extraction,Feature selection
[2] DeepAI. Feature Extraction
[3] scikit-learn docs. Preprocessing (Feature extraction and normalization)
[4] Data Science Primer. Feature Engineering
[5] Open Machine Learning Course. Topic 6. Feature Engineering and Feature Selection









 京公网安备 11010802041100号
京公网安备 11010802041100号