作者:mgmonster | 来源:互联网 | 2023-07-27 12:04
文章目录前言一、LDA主题模型是什么?1.LDA主题模型原理2.LDA主题模型推演过程三、问题总结1.怎么确定LDA的标题个数?四、拔高亮点1.如何用主题模型解决推荐系统中的冷启动
文章目录
- 前言
- 一、LDA主题模型是什么?
- 三、问题总结
- 四、拔高亮点
- 1. 如何用主题模型解决推荐系统中的冷启动问题?
- 2.如何解决系统冷启动问题呢?
- 总结
前言
随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习LDA主题模型的基础内容。
一、LDA主题模型是什么?
1.LDA主题模型原理
其实说到LDA能想到的有两个含义,
一种是线性判别分析(Linear Discriminant Analysis),
一种说的是概率主题模型:隐含狄利克雷分布(Latent Dirichlet Allocation,简称LDA)。
现在讨论的是主题模型这个东西,它通俗点说吧,就是可以将一篇文中的主题以概率分布的形式来给出,从而通过去分析一些文档抽取出来它们的主题(分布)以后,就可以根据主题(分布)进行主题聚类或文本分类。同时,它是一种典型的词袋子模型,也就是说一篇文档是由一组词构成,词与词之间没有先后顺序的关系。除此之外,一篇文章它可以包含多个主题,文章中每一个词都由是其中的一个主题生成。
我们其实很简单就可以想到我们是如何生成的文章?就是给几个主题,然后按一定的概率去选择主题,以一定的概率选择这个主题所包含的词汇,最终组合成一篇文章。LDA就是反过来的,给它一篇文章,去推断该文章的主题分布是什么。
2.LDA主题模型推演过程
我们先从一个类似LDA的模型开始,它就是PLSA模型,它类型属于有向边概率图模型。比如说我有一批数据,有部分是垃圾邮件,有部分是正常邮件,来个新数据,我怎么判定它是不是垃圾邮件?我们首先需要建立词汇表(使用现有的单子字典或者将邮件里的单词统计下得到字典),然后随机一个矩阵,经过训练后让这个矩阵去表示那个词,为啥不用onehot呢?因为比较稀疏,很容易梯度爆炸。然后套到贝叶斯公式里: P(C|X) = P©*P(X|C) / P(X),会有个问题,它没有办法解决一词多意或者多词一意的问题,会导致我们计算文本之间相似度时候的不准确性。我们找到个解决办法就是为每一篇文档加上一个主题。其实它核心的过程就是选定文章生成主题,确定主题生成词。在这个过程里,我们其实并没有关注词和词之间的出现顺序,所以PLSA是一种词袋子方法。它主要应用于信息检索,过滤,自然语言处理等领域,考虑到词分布和主题分布,使用EM最大期望算法去学习参数。
然后我们将PLSA模型加上一个贝叶斯框架就是我们的LDA主题模型了,换句话说LDA就是PLSA的贝叶斯版本,朴素贝叶斯的文本分类问题里的两个基础条件是:①条件独立;②每个特征的重要性都是一样的。
LDA在选主题和选词两个参数都弄成随机的,而且加入了一个dirichlet先验随机确定;但是PLSA中主题分布和词分布是唯一确定的,用EM极大似然估计算法去推断两未知的固定参数,这也是它俩之间最大的区别。
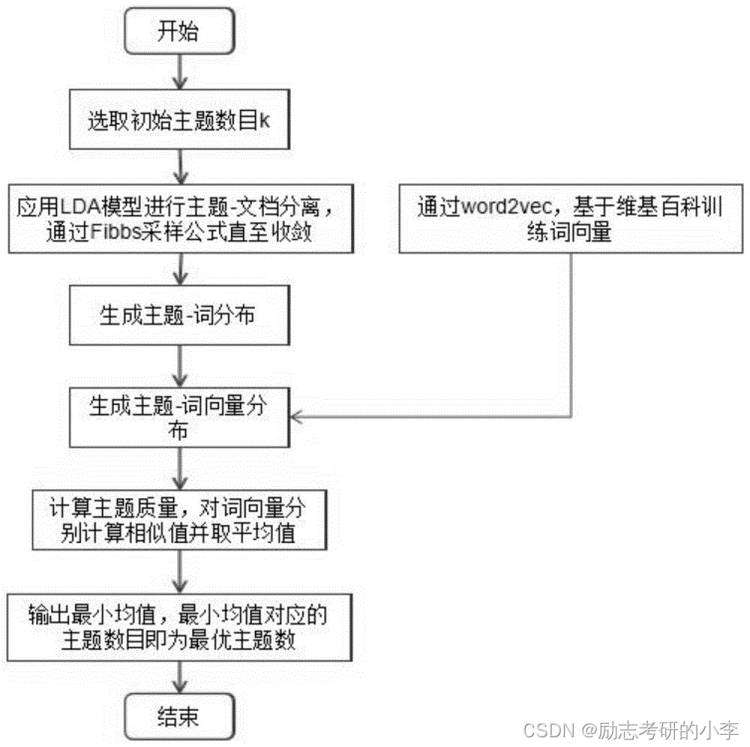
三、问题总结
1.怎么确定LDA的标题个数?
- 基于经验进行主观的判断、不断地调试、操作性强、最为常用;
- 基于困惑度(主要是比较两个模型之间的好坏);
- 使用Log-边际似然函数的方法,也比较常用;
- 计算主题向量之间的余弦距离,KL距离等
四、拔高亮点
1. 如何用主题模型解决推荐系统中的冷启动问题?
推荐系统中的冷启动问题就是指在没有大量用户数据的情况下如何给用户进行个性化推荐,目的是最优化点击率、转化率或用户的体验(用户停留时间、留存率等)。冷启动问题一般分为用户冷启动、物品冷启动和系统冷启动三大类。解决冷启动问题的方法一般是基于内容的推荐。从三个角度进行分析:
- 对用户冷启动来说,我们希望根据用户的注册信息(如:年龄、性别、爱好等)、搜索关键词或者合法站外得到的其他信息(例如用户使用Facebook账号登录,并得到授权,可以得到Facebook中的朋友关系和评论内容)来推测用户的兴趣主题。得到用户的兴趣主题之后,我们就可以找到与该用户兴趣主题相同的其他用户,通过他们的历史行为来预测用户感兴趣的电影是什么。
- 对物品冷启动来说,我们也可以根据电影的导演、演员、类别、关键词等信息推测该电影所属于的主题,然后基于主题向量找到相似的电影,并将新电影推荐给以往喜欢看这些相似电影的用户。可以使用主题模型(PLSA、LDA等)得到用户和电影的主题。
- 对用户冷启动来说,我们把每个用户看作主题模型中的一篇文章,用户对应的特征作为文档中的单词,这样每个用户可以表示成一种词袋子特征的形式。通过主题模型去学习之后,经常共同出现的特征将会对应同一个主题,同时每个用户也会相应地得到一个主题分布。每个电影的主题分布也可以用类似的方法去得到。
2.如何解决系统冷启动问题呢?
首先可以得到每个用户和电影对应的主题向量,除此之外,还需要知道用户主题和电影主题之间的偏好程度,也就是哪些主题的用户可能喜欢哪些主题的电影。当系统中没有任何数据的时侯,我们需要一些先验知识来指定,并且由于主题的数目通常比较小,随着系统的上线,收集到少量的数据之后我们就可以对主题之间的偏好程度得到一个比较准确的估计了。
总结
以上就是今天要讲的内容,本文仅仅简单介绍了LDA主题模型的使用









 京公网安备 11010802041100号
京公网安备 11010802041100号