作者:W你是我的小太阳 | 来源:互联网 | 2023-09-14 10:51
一、个体与集成
集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务。下图显示出集成学习的一般结构:
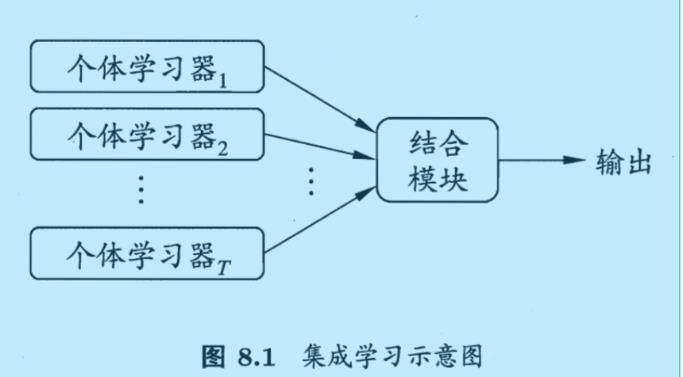
集成学习一般结构:先产生一组个体学习器(也称基学习器),再用某种策略将它们结合起来。基学习器通常是由现有算法(如逻辑回归、决策树)从训练数据产生。基学习器是同种算法,例如都是决策树,也可以包含不同算法,例如决策树和神经网络。
集成学习通过将多个学习器进行结合,常可获得比单一学习器显著优越的性能。因此基学习器往往也被称为弱学习器,尽管它们可能并不是很弱。
集成学习一定比基学习器好吗?在一般经验中,如果把好的东西和坏的东西掺在一起,得到的是中等的东西。那集成学习怎样才能获得比基学习器好的结果呢?一般情况下:要获得好的集成效果,基学习器应”好而不同“,具体地,每个基学习器的分类准确率应超过50%,并且要彼此不同,因为只有这样才能让集成学习捕捉到每个学习器独特的优点。
按照集成方法的不同,集成学习的类型分为:Bagging、Boosting和Stacking。
二、Bagging
Bagging全称Boostrap AGGregatING,是并行式集成学习方法的代表。Bagging的原理为:给定包含m个样本的初始数据集,使用自助抽样法(bootstrap sampling)得到一个也包含m个样本的数据集,依此法得到T个数据集。然后基于每个训练集训练出一个基学习器,再将这T个基学习器进行结合。对于分类任务,采取投票法;对于回归任务,采取平均法。
值得注意的是,自助抽样法只是用了源数据集63.2%的样本,剩下的36.8%的样本可当作”验证集“来对泛化性能进行”包外估计“。
从偏差—方差分解的角度来看,Bagging主要关注降低方差(多个基学习器使得预测结果更加稳定),因此它在决策树、神经网络等易受样本扰动的不稳定学习器上效果更加明显。
Bagging中最著名的算法就是随机森林(Random Forest)。它是Bagging的一个扩展变体。随机森林在以决策树作为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程中引入了随机属性选择。传统的Bagging会对样本进行自主抽样,但会使用所有的属性,而随机森林每次只是随机选择部分属性,从而形成了“双随机”,即样本随机和属性随机。
三、Boosting
Boosting是一类可将弱学习器提升为强学习器的算法。Boostin类算法的原理类似,大致为:先从初始训练集训练出一个基学习器,再根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本在后面的基学习器中受到更多关注,然后基于调整后的样本分布来训练下一个基学习器,如此往复,直至基学习器个数达到了预先指定的数量T,此时由于每个基学习器的表现不一样,对表现好的赋予更大的权重,最终将这T个学习器进行加权结合。
Boosting类算法中最著名的就是AdaBoost,此外还有GBDT、XgBoost和LightGBM等。
 
 







 京公网安备 11010802041100号
京公网安备 11010802041100号