作者:井爱3053_170 | 来源:互联网 | 2024-11-20 15:19
本文详细介绍了层次聚类算法的基本原理,包括其通过构建层次结构来分类样本的特点,以及自底向上(凝聚)和自顶向下(分裂)两种主要的聚类策略。文章还探讨了不同距离度量方法对聚类效果的影响,并提供了具体的参数设置指导。
层次聚类算法详解
层次聚类是一种基于样本间距离的无监督学习方法,它假设不同的类别之间存在一定的层次关系,通过不断合并或分裂的方式形成层次化的类别结构。这一过程可以通过两种主要策略实现:一种是从单个样本开始,逐步合并相近的样本形成更大的类,称为凝聚;另一种则是从所有样本作为一个大类开始,逐步分裂成更小的子类,称为分裂。
凝聚聚类:初始状态下,每个样本被视为独立的一类。随后,算法会根据预先定义的距离度量标准,选择最接近的两类进行合并,形成新的类。这一过程持续进行,直至满足预设的停止条件,例如达到特定的类数量或是最大类内距离阈值。
分裂聚类:与凝聚聚类相反,分裂聚类首先将所有样本视为一个整体类。接着,算法会选择类内距离最远的样本进行分割,创建新的子类。这一过程重复执行,直到满足停止条件。
距离度量方法
在层次聚类过程中,选择合适的距离度量方法对于确保聚类的有效性和准确性至关重要。常见的距离度量方法包括:
1. 最小距离法:这种方法以两个簇中最短的样本间距离作为簇间距离的度量标准,但容易受到异常值的影响。
2. 最大距离法:以两个簇中最长的样本间距离作为度量标准,同样容易受异常值影响。
3. 平均距离法:计算两个簇中所有样本对的平均距离作为度量标准,这种方法相对较为稳健,能够较好地平衡异常值的影响。
层次聚类的实施步骤
了解了基本概念后,接下来具体介绍如何利用层次聚类算法对数据进行分类。主要步骤如下:
- 初始化:将数据集中的每个样本视为单独的类。
- 计算距离:计算所有样本之间的距离,选择距离最近的两个样本或类进行合并。
- 更新距离:重新计算合并后的类与其他类之间的距离。
- 迭代:重复上述步骤,直至达到预定的聚类个数或满足其他终止条件。
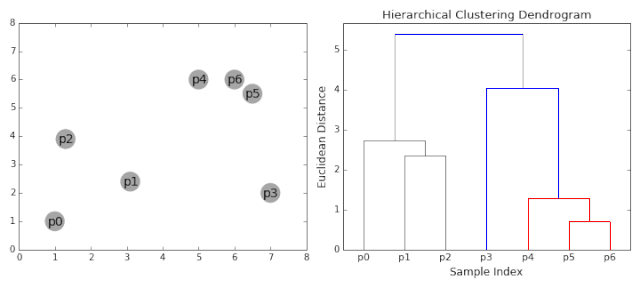
为了帮助理解,下图展示了层次聚类的动态过程:
参数配置
在使用Python的scikit-learn库实现层次聚类时,可以调整多个参数以优化模型性能。主要参数包括:
n_clusters:指定最终聚类的数量,默认值为2。affinity:指定样本间距离的度量方式,支持欧氏距离、曼哈顿距离等,默认为欧氏距离。linkage:指定簇间距离的度量方法,可选值包括'ward'(最小距离法)、'complete'(最大距离法)和'average'(平均距离法),默认为'ward'。
应用实例:鸢尾花数据集
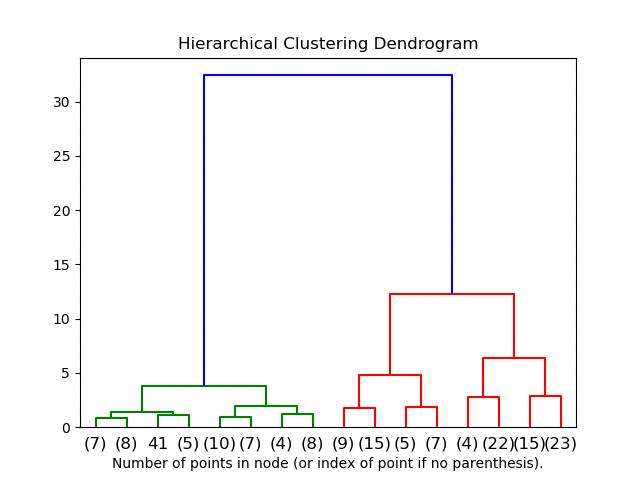
为了更好地说明层次聚类的应用,我们将使用经典的鸢尾花数据集进行演示。该数据集包含了150个样本,每个样本有4个特征:萼片长度、萼片宽度、花瓣长度和花瓣宽度。通过层次聚类算法,我们可以探索这些特征之间的关系,将鸢尾花分为不同的类别,从而辅助植物学家的研究工作。
以下是层次聚类应用于鸢尾花数据集的结果可视化:










 京公网安备 11010802041100号
京公网安备 11010802041100号