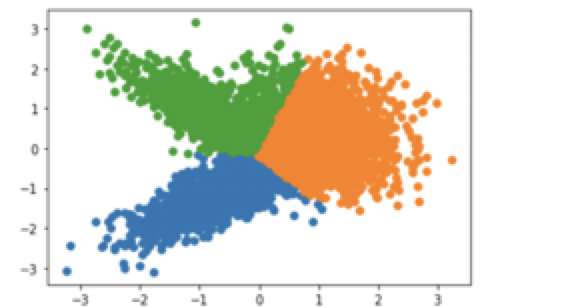
#导入需要的库 from numpy import unique from numpy import where from sklearn.datasets import make_classification from sklearn.preprocessing import LabelEncoder, StandardScaler from matplotlib import pyplot# 将生成的分类数据集用图形化显示 X,y = make_classification(n_samples=5000, n_features=2,n_informative=2, n_redundant=0,n_classes=3,n_clusters_per_class=1,random_state=1) # 数据集标准化操作 X = StandardScaler().fit_transform(X) clusters_temp = unique(y) for cluster_temp in clusters_temp:row_ix = where(y == cluster_temp)pyplot.scatter(X[row_ix,0],X[row_ix,1]) pyplot.show()#显示数据集分布情况 # y.shape
2.使用K-means算法进行聚类
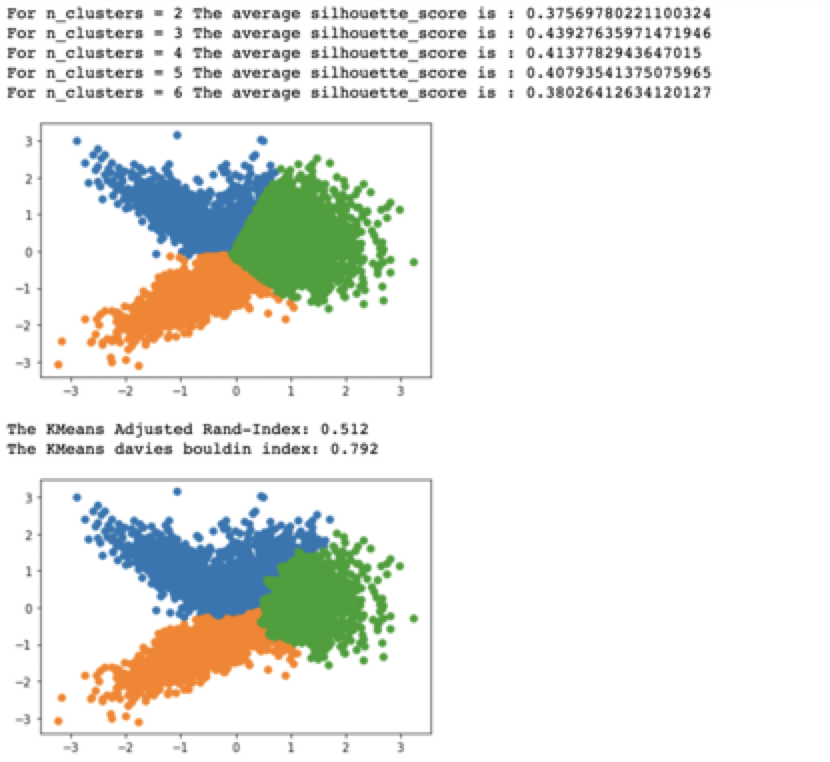
from sklearn.cluster import KMeans from matplotlib import pyplot from numpy import unique from numpy import where from matplotlib import pyplotmodel = KMeans(n_clusters=3)#聚类类别为2 yhat = model.fit_predict(X) clusters = unique(yhat) for cluster in clusters:row_ix = where(yhat == cluster)pyplot.scatter(X[row_ix,0],X[row_ix,1]) pyplot.show()
分类后是这个样子:
3.评价聚类结果
from sklearn import metrics from sklearn.metrics import davies_bouldin_score print("Adjusted Rand-Index: %.3f"% metrics.adjusted_rand_score(y,yhat)) print("davies bouldin index: %.3f"% metrics.davies_bouldin_score(X,yhat))
评价结果如下:
4.用silhouette选择K-means聚类的簇数:
import numpy as np from sklearn.cluster import KMeans from sklearn.metrics import silhouette_samples, silhouette_scorerange_n_clusters =[2,3,4,5,6]for n_clusters in range_n_clusters:clusterer = KMeans(n_clusters=n_clusters, random_state=10)cluster_labels = clusterer.fit_predict(X)silhouette_avg = silhouette_score(X, cluster_labels)print("For n_clusters =",n_clusters,"The average silhouette_score is :",silhouette_avg,)
结果显示分成3簇的时候效果最好
5.使用不同聚类方法
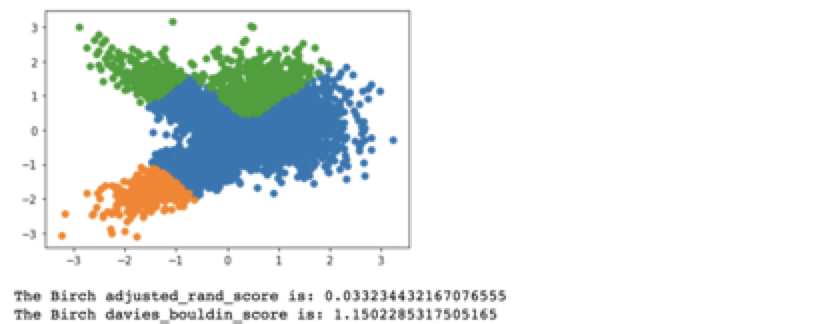
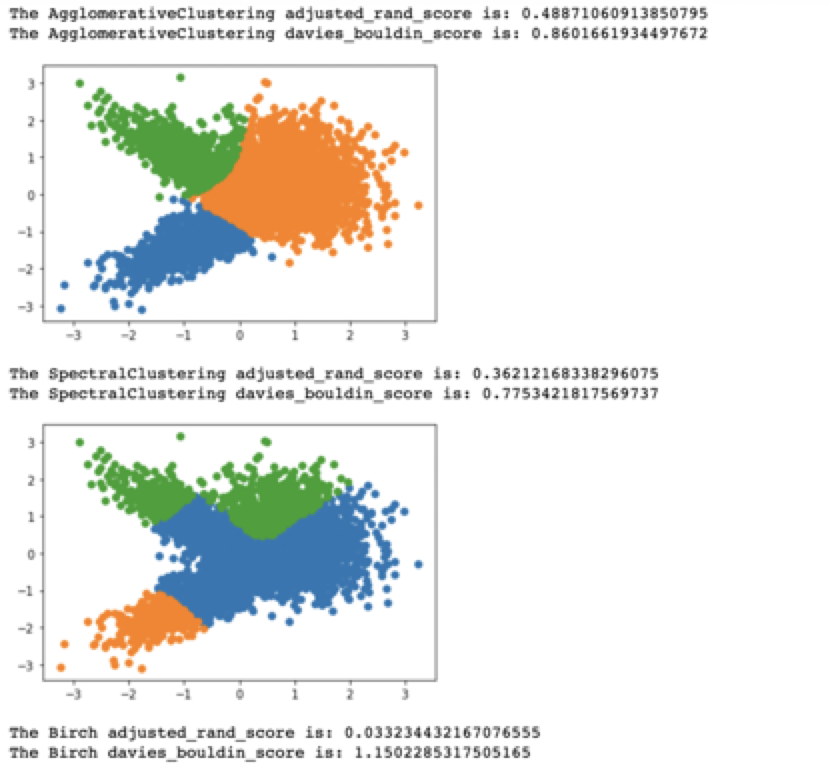
from sklearn.cluster import Birchmodel = Birch(n_clusters=3)yhat = model.fit_predict(X) clusters = unique(yhat) for cluster in clusters:row_ix = where(yhat == cluster)pyplot.scatter(X[row_ix,0],X[row_ix,1]) pyplot.show()print("The Birch adjusted_rand_score is:",metrics.adjusted_rand_score(y,yhat)) print("The Birch davies_bouldin_score is:",metrics.davies_bouldin_score(X,yhat))
结果如下:
完整代码
#导入库 import numpy as np from numpy import unique from numpy import where from matplotlib import pyplot from sklearn.datasets import make_classification from sklearn.preprocessing import LabelEncoder, StandardScaler from sklearn.cluster import KMeans from sklearn.metrics import silhouette_samples, silhouette_score# 生成数据集 X,y = make_classification(n_samples=5000, n_features=2,n_informative=2, n_redundant=0,n_classes=3,n_clusters_per_class=1,random_state=1) X = StandardScaler().fit_transform(X) ################################################################################ range_n_clusters =[2,3,4,5,6] for n_clusters in range_n_clusters: clusterer = KMeans(n_clusters=n_clusters, random_state=10)cluster_labels = clusterer.fit_predict(X)silhouette_avg = silhouette_score(X, cluster_labels)print("For n_clusters =",n_clusters,"The average silhouette_score is :",silhouette_avg,) ################################################################################ model = KMeans(n_clusters=3)#聚类类别为2 yhat = model.fit_predict(X) clusters = unique(yhat) for cluster in clusters:row_ix = where(yhat == cluster)pyplot.scatter(X[row_ix,0],X[row_ix,1]) pyplot.show() print("The KMeans Adjusted Rand-Index: %.3f"% metrics.adjusted_rand_score(y,yhat)) print("The KMeans davies bouldin index: %.3f"% metrics.davies_bouldin_score(X,yhat)) ################################################################################ from sklearn.cluster import AgglomerativeClustering model = AgglomerativeClustering(n_clusters=3) yhat = model.fit_predict(X) clusters = unique(yhat) for cluster in clusters:row_ix = where(yhat == cluster)pyplot.scatter(X[row_ix,0],X[row_ix,1]) pyplot.show() print("The AgglomerativeClustering adjusted_rand_score is:",metrics.adjusted_rand_score(y,yhat)) print("The AgglomerativeClustering davies_bouldin_score is:",metrics.davies_bouldin_score(X,yhat)) ################################################################################ from sklearn.cluster import SpectralClustering model = SpectralClustering(n_clusters=3) yhat = model.fit_predict(X) clusters = unique(yhat) for cluster in clusters:row_ix = where(yhat == cluster)pyplot.scatter(X[row_ix,0],X[row_ix,1]) pyplot.show() print("The SpectralClustering adjusted_rand_score is:",metrics.adjusted_rand_score(y,yhat)) print("The SpectralClustering davies_bouldin_score is:",metrics.davies_bouldin_score(X,yhat)) ################################################################################ from sklearn.cluster import Birch model = Birch(n_clusters=3) yhat = model.fit_predict(X) clusters = unique(yhat) for cluster in clusters:row_ix = where(yhat == cluster)pyplot.scatter(X[row_ix,0],X[row_ix,1]) pyplot.show() print("The Birch adjusted_rand_score is:",metrics.adjusted_rand_score(y,yhat)) print("The Birch davies_bouldin_score is:",metrics.davies_bouldin_score(X,yhat))





 京公网安备 11010802041100号
京公网安备 11010802041100号