1、当预测结果与实际偏差很大时的处理方法:
(1)增加训练样本;
(2)减少特征集防止过拟合;
(3)增加特征集或者多项式特征(如 x1², x2³ 等);
(4)减小 / 增大 lambda .
2、评估假设函数:
将数据集分成两部分:训练集(70%)和测试集(30%)
具体流程:
(1)通过学习获得 θ ,计算训练误差 J(θ);
(2)计算测试误差 Jtest(θ)
①对于线性回归:
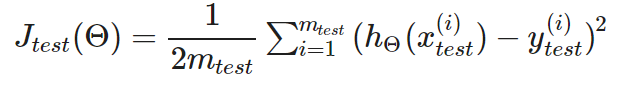
②对于逻辑回归:
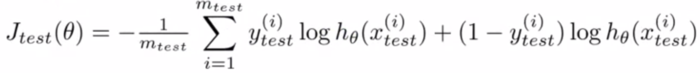
Misclassification error 误分类率(0/1错分率):

测试误差:
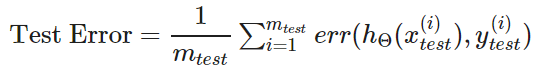
3、模型的选择:
假设有以下10个待选模型:
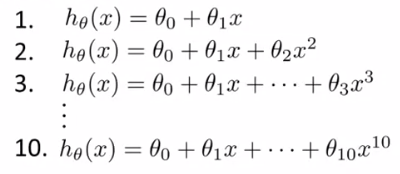
(1)将数据集分为三部分:训练集(60%)、交叉验证集(cross validation set,简写CV,20%)和测试集(20%).

(2)增加参数 d,表示多项式的次数,依次取值 d = 1,2,...,10.
(3)对模型进行依次训练,获得各个模型的 θ,记为 θ(1) , θ(2) , ... , θ(10)
(4)根据交叉验证集计算 JCV(θ(1)) , JCV(θ(2)) , ... , JCV(θ(10)) . 选择误差最小的模型.
(5)得出 d = k(其中第k个模型是选定的模型),使用验证集计算测试误差,对模型进行评估。
4、偏差和方差问题:
(1)举例说明:
Pic.1 欠拟合(高偏差) d = 1 Pic.2 拟合 d = 2 Pic.3 过拟合(高方差) d = 4

当 d 较小时,高偏差问题:Jtrain(θ) 高,JCV(θ) ≈ Jtest(θ) ≈ Jtrain(θ) .
当 d 较大时,高方差问题:Jtrain(θ) 低,JCV(θ) ≈ Jtest(θ) >> Jtrain(θ) .
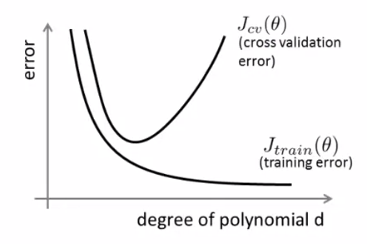
(2)假设已经选出了 d = 4,引入正则化解决过拟合问题:
对于λ 太小,依然存在过拟合;对于 λ 太大,假设函数趋于直线,欠拟合。

① 设置 λ = 0,0.1,0.2,0.4,...,10.24 (最后一组可以设置为10,一共12组),分别进行拟合,获得不同的 θ,对应分别为 θ(1) , θ(2) , ... , θ(12) 。
② 用交叉验证集进行评估,选择评估结果最佳的 λ 。
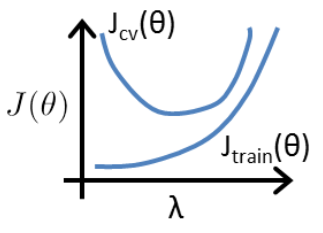
5、学习曲线:
(1)高偏差的情况(欠拟合):
随着训练集的增多,拟合的偏差依然较大,训练集和验证集误差相差较小,且趋于水平。说明收集再多的数据对于结果帮助甚微。
下图举例:随着训练集增多,拟合的结果依然是一根直线,误差依然很大。

学习曲线:

(2)高方差的情况(过拟合):
随着训练集的增多,训练集误差较低,但是验证集误差一直处于较高的状态,两者之间有很大的偏差。如果两者距离随着训练集的增大而靠近,收集更多的训练集可能会对结果带来帮助。
下图举例:随着训练集增多,曲线拟合越来越精细的拟合数据。
学习曲线:

6、算法的改进方法:
(1)收集更多的数据,对于高方差的情况;
(2)减少特征,对于高方差的情况;
(3)增加特征 / 多项式特征,对于高偏差的情况;
(4)增大 lambda,对于高方差的情况;
(5)减小 lambda,对于高偏差的情况。
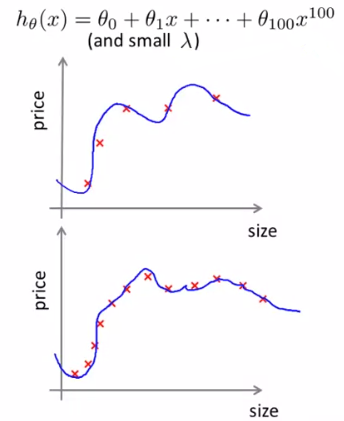
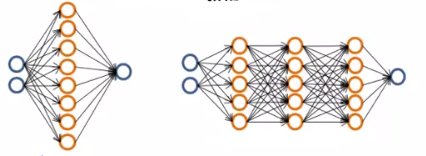
7、神经网络的选择:
(1)小型神经网络:计算量小;隐藏层 / 单元少;参数少;容易出现欠拟合;
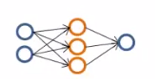
(2)复杂神经网络:计算量大;隐藏层 / 单元多;参数多;容易产生过拟合。
可以使用正规化修正过拟合。
8、Skewed classes (倾斜类)
(1)问题背景:
预测肿瘤问题上,采用机器学习预测准确率为99%,但是实际恶性肿瘤概率只有0.5%,这意味着单纯假设全部为良性的方法准确率为99.5%,比机器学习的准确率更高。然而全部假设为良性的方法并不科学。
(2)Precision(查准率) Recall(召回率):
假设是一个0 / 1二分问题,定义如下表:
|
Actual Class |
|||
|
Predicted Class |
1 |
0 | |
|
1 |
True Positive |
False Positive |
|
| 0 |
False Negative |
True Negative |
|
Precision = True Positive / Predicted Postive = True Positive / (True Positive + False Positive)(预测有癌症的人中多大比例真患癌症)
Recall = True Positive / Actual Positive = True Positive / (True Positive + False Negative)(所有患癌症的人中有多大比例被成功预测)
如果全部预测为良性,即预测 y = 0,那么Recall = 0,可以判断出该方法不合理。
一个好的分类模型,需要拥有较高的查准率和召回率。
(3)平衡Precision 和 Recall:
① 在肿瘤预测的案例中,为了保证在非常确定的情况下才能把恶性肿瘤作为预测结果,需要对预测过程进行修改:
原预测过程:Predict 1 if hθ(x) ≥ 0.5,Predict 0 if hθ(x) < 0.5;
修改后的预测过程:Predict 1 if hθ(x) ≥ 0.7,Predict 0 if hθ(x) < 0.7.
这种情况下将会有较高的precision,但recall将较低。
② 若为了保证在较保守的情况下也将恶性肿瘤作为预测结果,以让患者提早检测治疗,需要对预测过程进行修改:
修改后的预测过程:Predict 1 if hθ(x) ≥ 0.3,Predict 0 if hθ(x) < 0.3.
这种情况下将会有较高的recall,但precision将较低。
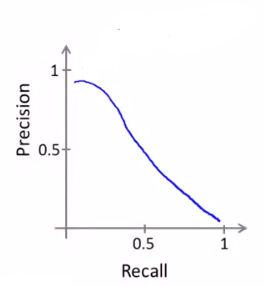
Predict 1 if hθ(x) ≥ threshold.
上图从左到右,threshold = 0.99 To 0.01
③ 如何比较 Precision(P) 和 Recall(R) ?
F1 Score = 2PR / (P + R)









 京公网安备 11010802041100号
京公网安备 11010802041100号