Hi,大家好,我是Mic
一个工作4年的粉丝,投了很多简历
好不容易接到一个互联网公司的面试邀约。
在面试第一轮就被干掉了,原因是对主流互联网技术理解太浅了。
其中就有一个这样的问题:“简单说一下你对序列化和反序列化的理解”
下面看看普通人和高手的回答。
普通人:
序列化和反序列化就是说我要去把一个对象传输到网络上的其他的一个应用上一个情况下,就是我需要对这个对象做序列化。
然后想Java里面我们可以,我们需要对这个对象的序列化的话,我们需要去实现像Serializable这样一个接口吧。
高手:
好的,关于这个问题,我需要从几个方面来回答。
首先,我认为,之所以需要序列化,核心目的是为了解决网络通信之间的对象传输问题。
也就是说,如何把当前JVM进程里面的一个对象,跨网络传输到另外一个JVM进程里面。
而序列化,就是把内存里面的对象转化为字节流,以便用来实现存储或者传输。
反序列化,就是根据从文件或者网络上获取到的对象的字节流,根据字节流里面保存的对象描述信息和状态。
重新构建一个新的对象。
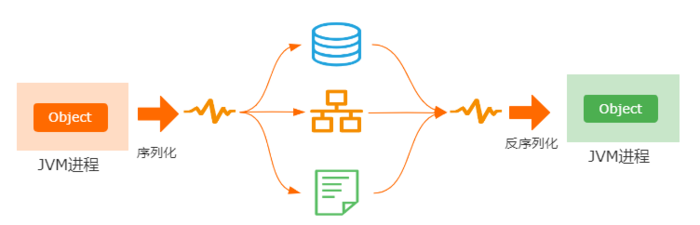
其次呢,序列化的前提是保证通信双方对于对象的可识别性,所以很多时候,我们会把对象先转化为通用的解析格式,
比如json、xml等。然后再把他们转化为数据流进行网络传输,从而实现跨平台和跨语言的可识别性。
最后,我再补充一下序列化选择。
市面上开源的序列化技术非常多,比如Json、Xml、Protobuf、Kyro、hessian等等。
那在实际应用里面,哪种序列化最合适,我认为有几个关键因素。
- 序列化之后的数据大小,因为数据大小会影响传输性能
- 序列化的性能,序列化耗时较长会影响业务的性能
- 是否支持跨平台和跨语言
- 技术的成熟度,越成熟的方案使用的公司越多,也就越稳定。
以上就是我对这个问题的理解!
总结
序列化这个问题,面试问得也比较多
再深入一点,还会问到序列化的算法和原理。
在实际开发中,序列化技术的选择对于性能的影响也是比较大的。
因此互联网公司对这方面的考察会比较多一些。
喜欢我作品的小伙伴,记得点赞收藏加关注。

版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自
Mic带你学架构!
如果本篇文章对您有帮助,还请帮忙点个关注和赞,您的坚持是我不断创作的动力。欢迎关注「跟着Mic学架构」公众号公众号获取更多技术干货!








 京公网安备 11010802041100号
京公网安备 11010802041100号