java.util.List接口是Java Collections Framework的一个重要组成部分,List接口的架构图如下:
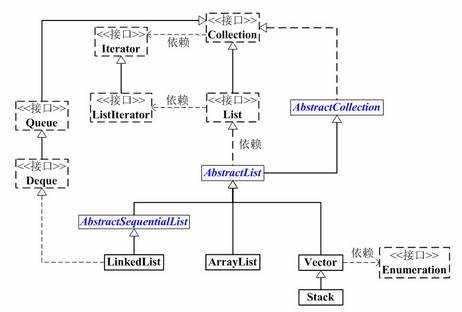
本文将通过剖析List接口的三个实现类——ArrayList、LinkedList和Vector的源码,带你走近List的世界。
ArrayList是List接口可调整数组大小的实现。实现所有可选列表操作,并允许放入包括空值在内的所有元素。每个ArrayList都有一个容量(capacity,区别于size),表示底层数组的实际大小,容器内存储元素的个数不能多于当前容量。
java.util.ArrayList类的继承关系如下:
public class ArrayList
其中需要注意的是RandomAccess接口,这是一个标记接口,没有定义任何具体的内容,该接口的意义是随机存取数据。在该接口的注释中有这样一段话:
/** for (int i=0, n=list.size(); i
这说明在数据量很大的情况下,采用迭代器遍历实现了该接口的集合,速度比较慢。
实现了RandomAccess接口的集合有:ArrayList, AttributeList, CopyOnWriteArrayList, RoleList, RoleUnresolvedList, Stack, Vector等。
ArrayList一些重要的字段如下:
private static final int DEFAULT_CAPACITY = 10;private static final Object[] EMPTY_ELEMENTDATA = {};private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};transient Object[] elementData; // non-private to simplify nested class accessprivate int size;//底层数组中实际元素个数,区别于capacity
可以看到,默认第一次插入元素时创建数组的大小为10。当向容器中添加元素时,如果容量不足,容器会自动增加50%的容量。增加容量的函数grow()源码如下:
private void grow(int minCapacity) {// overflow-conscious codeint oldCapacity &#61; elementData.length;int newCapacity &#61; oldCapacity &#43; (oldCapacity >> 1);//右移一位代表增加50%if (newCapacity - minCapacity <0)newCapacity &#61; minCapacity;if (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity &#61; hugeCapacity(minCapacity);// minCapacity is usually close to size, so this is a win:elementData &#61; Arrays.copyOf(elementData, newCapacity);}private static int hugeCapacity(int minCapacity) {if (minCapacity <0) // overflowthrow new OutOfMemoryError();return (minCapacity > MAX_ARRAY_SIZE) ?Integer.MAX_VALUE :MAX_ARRAY_SIZE;}
值得注意的是&#xff0c;由于集合框架用到了编译器提供的语法糖——泛型&#xff0c;而Java泛型的内在实现是通过类型擦除和类型强制转换来进行的&#xff0c;其实存储的数据类型都是Raw Type&#xff0c;因此集合框架的底层数组都是Object数组&#xff0c;可以容纳任何对象。
ArrayList的实现中大量地调用了Arrays.copyof()和System.arraycopy()方法。在此介绍一下这两个方法。
System.arraycopy()方法是一个native方法&#xff0c;调用了系统的C/C&#43;&#43;代码&#xff0c;在openJDK中可以看到其源码。该方法最终调用了C语言的memmove()函数&#xff0c;因此它可以保证同一个数组内元素的正确复制和移动&#xff0c;比一般的复制方法的实现效率要高很多&#xff0c;很适合用来批量处理数组。Java强烈推荐在复制大量数组元素时使用该方法&#xff0c;以取得更高的效率。
Arrays.copyOf()方法有很多重载版本&#xff0c;但实现思路都是一样的&#xff0c;其泛型版本源码如下&#xff1a;
public static
}
其调用了copyof()方法&#xff1a;
public static
}
该方法实际上是在其内部创建了一个类型为newType、长度为newLength的新数组&#xff0c;调用System.arraycopy()方法&#xff0c;将原来数组中的元素复制到新的数组中。
ArrayList的实现是不同步的&#xff0c;如果多个线程同时访问ArrayList实例&#xff0c;并且至少有一个线程修改list的结构&#xff0c;那么它就必须在外部进行同步。如果没有这些对象&#xff0c; 这个list应该用Collections.synchronizedList()方法进行包装。 最好在list的创建时就完成包装&#xff0c;防止意外地非同步地访问list:
List list &#61; Collections.synchronizedList(new ArrayList(...));
除了未实现同步之外&#xff0c;ArrayList大致相当于Vector。
size(), isEmpty(), get(),set()方法均能在常数时间内完成&#xff0c;add()方法的时间开销跟插入位置有关(adding n elements requires O(n) time)&#xff0c;addAll()方法的时间开销跟添加元素的个数成正比。其余方法大都是线性时间。
ArrayList常用的size(), isEmpty(), get(),set()方法实现都比较简单&#xff0c;读者可自行翻阅源码&#xff0c;它们均能在常数时间内完成&#xff0c;性能很高&#xff0c;这也是数组实现的优势所在。add()方法的时间开销跟插入位置有关(adding n elements requires O(n) time)&#xff0c;addAll()方法的时间开销跟添加元素的个数成正比。其余方法大都是线性时间。
add()方法
public boolean add(E e) {ensureCapacityInternal(size &#43; 1); // Increments modCount!!elementData[size&#43;&#43;] &#61; e;return true;
}
public void add(int index, E element) {rangeCheckForAdd(index);ensureCapacityInternal(size &#43; 1); // Increments modCount!!System.arraycopy(elementData, index, elementData, index &#43; 1,size - index);elementData[index] &#61; element;size&#43;&#43;;
}
前者是在ArrayList尾部插入一个元素&#xff0c;后者是在指定位置插入元素。值得注意的是&#xff0c;将元素的索引赋给elementData[size]时可能会出现数组越界&#xff0c;这里的关键就在于ensureCapacity(size&#43;1)的调用&#xff0c;这个方法的作用是确保数组的容量&#xff0c;它的源码如下&#xff1a;
ensureCapacity()和ensureExplicitCapacity()方法&#xff1a;
public void ensureCapacity(int minCapacity) {int minExpand &#61; (elementData !&#61; DEFAULTCAPACITY_EMPTY_ELEMENTDATA)// any size if not default element table? 0// larger than default for default empty table. It&#39;s already// supposed to be at default size.: DEFAULT_CAPACITY;if (minCapacity > minExpand) {ensureExplicitCapacity(minCapacity);}
}private void ensureExplicitCapacity(int minCapacity) {modCount&#43;&#43;;// overflow-conscious codeif (minCapacity - elementData.length > 0)grow(minCapacity);
}
其中有一个重要的实例变量modCount&#xff0c;它是在AbstractList类中定义的&#xff0c;在使用迭代器遍历的时候&#xff0c;用modCount来检查列表中的元素是否发生结构性变化&#xff08;列表元素数量发生改变&#xff09;了&#xff0c;如果modCount值改变&#xff0c;则代表列表中元素发生了结构性变化。
前面说过&#xff0c;ArrayList是非线程安全的&#xff0c;modCount主要在多线程环境下进行安全检查&#xff0c;防止一个线程正在迭代遍历&#xff0c;另一个线程修改了这个列表的结构。如果在使用迭代器进行遍历ArrayList的时候modCount值改变&#xff0c;则会报ConcurrentModificationException异常。
可以看出&#xff0c;直接在数组后面插入一个元素add(e)效率也很高&#xff0c;但是如果要按下标来插入元素&#xff0c;则需要调用System.arraycopy()方法来移动部分受影响的元素&#xff0c;这会导致性能低下&#xff0c;这也是使用数组实现的ArrayList的劣势。
同理&#xff0c;remove()方法也会改变modCount的值&#xff0c;效率与按下标插入元素相似&#xff0c;在此不加赘述。
addAll()方法
public boolean addAll(Collection c) {Object[] a &#61; c.toArray();int numNew &#61; a.length;ensureCapacityInternal(size &#43; numNew); // Increments modCountSystem.arraycopy(a, 0, elementData, size, numNew);size &#43;&#61; numNew;return numNew !&#61; 0;
}
public boolean addAll(int index, Collection c) {rangeCheckForAdd(index);Object[] a &#61; c.toArray();int numNew &#61; a.length;ensureCapacityInternal(size &#43; numNew); // Increments modCountint numMoved &#61; size - index;if (numMoved > 0)System.arraycopy(elementData, index, elementData, index &#43; numNew,numMoved);System.arraycopy(a, 0, elementData, index, numNew);size &#43;&#61; numNew;return numNew !&#61; 0;
}
addAll方法也分在末尾插入和在指定位置插入&#xff0c;先将入参中的集合c转换成数组&#xff0c;根据转换后数组的程度和ArrayList的size拓展容量&#xff0c;之后调用System.arraycopy()方法复制元素到相应位置&#xff0c;调整size。根据返回的内容分析&#xff0c;只要集合c的大小不为空&#xff0c;即转换后的数组长度不为0则返回true。
容易看出&#xff0c;addAll()方法的时间开销是跟添加元素的个数成正比的。
trimToSize()方法
下面来看一个简单但是很有用的方法trimToSize()。
public void trimToSize() {modCount&#43;&#43;;if (size
由于elementData的长度会被拓展&#xff0c;size标记的是其中包含的元素的个数。所以会出现size很小但elementData.length很大的情况&#xff0c;将出现空间的浪费。trimToSize()将返回一个新的数组给elementData&#xff0c;元素内容保持不变&#xff0c;length和size相同&#xff0c;节省空间。
在实际应用中&#xff0c;考虑这样一种情形&#xff0c;当某个应用需要&#xff0c;一个ArrayList扩容到比如size&#61;10000&#xff0c;之后经过一系列remove操作size&#61;15&#xff0c;在后面的很长一段时间内这个ArrayList的size一直保持在<100以内&#xff0c;那么就造成了很大的空间浪费&#xff0c;这时候建议显式调用一下trimToSize()方法&#xff0c;以优化一下内存空间。 或者在一个ArrayList中的容量已经固定&#xff0c;但是由于之前每次扩容都扩充50%&#xff0c;所以有一定的空间浪费&#xff0c;可以调用trimToSize()消除这些空间上的浪费。
LinkedList与ArrayList一样也实现了List接口&#xff0c;LinkedList使用双向链表实现&#xff0c;允许存储元素重复&#xff0c;链表与ArrayList的数组实现相比&#xff0c;在进行插入和删除操作时效率更高&#xff0c;但查找操作效率更低&#xff0c;因此在实际使用中应根据自己的程序计算需求来从二者中取舍。
与ArrayList一样&#xff0c;LinkedList也是非线程安全的。
java.util.LinkedList的继承关系如下&#xff1a;
public class LinkedList
LinkedList继承自抽象类AbstractSequenceList&#xff0c;其实AbstractSequenceList已经实现了List接口&#xff0c;这里标注出List只是更加清晰而已。AbstractSequenceList提供了List接口骨干性的实现以减少从而减少了实现受“连续访问”数据存储&#xff08;如链表&#xff09;支持的此接口所需的工作。对于随机访问数据&#xff08;如数组&#xff09;&#xff0c;则应该优先使用抽象类AbstractList。
可以看到&#xff0c;LinkedList除了实现了List接口外&#xff0c;还实现了Deque接口&#xff0c;Deque即“Double Ended Queue”&#xff0c;是可以在两端插入和移动数据的线性数据结构&#xff0c;我们熟知的栈和队列皆可以通过实现Deque接口来实现。因此在LinkedList的实现中&#xff0c;除了提供了列表相关的方法如add()、remove()等&#xff0c;还提供了栈和队列的pop()、peek()、poll()、offer()等相关方法。这些方法中有些彼此之间只是名称的区别&#xff0c;内部实现完全相同&#xff0c;以使得这些名字在特定的上下文中显得更加的合适。
LinkedList定义的字段如下&#xff1a;
transient int size &#61; 0;
transient Node
transient Node
Size代表的是链表中存储的元素个数&#xff0c;而first和last分别代表链表的头节点和尾节点。 其中Node是LinkedList定义的静态内部类&#xff1a;
private static class Node
}
Node是链表的节点类&#xff0c;其中的三个属性item、next、prev分别代表了节点的存储属性值、前继节点和后继节点。
add(e)方法
public boolean add(E e) {linkLast(e);return true;
}void linkLast(E e) {final Node
}
由上述代码可见&#xff0c;LinkedList在表尾添加元素&#xff0c;只要直接修改相关节点的前后继节点信息&#xff0c;而无需移动其他元素的位置&#xff0c;因此执行添加操作时效率很高。此外&#xff0c;LinkedList也是非线程安全的
remove(o)方法
public boolean remove(Object o) {if (o &#61;&#61; null) {for (Node
}E unlink(Node
}
与add方法一样&#xff0c;remove方法的底层实现也无需移动列表里其他元素的位置&#xff0c;而只需要修改被删除节点及其前后节点的prev与next属性即可。
get(index)方法
该方法可以返回指定位置的元素&#xff0c;下面来看一看代码
public E get(int index) {checkElementIndex(index);return node(index).item;
}Node
}
可以看到&#xff0c;LinkedList要想找到index对应位置的元素&#xff0c;必须要遍历整个列表&#xff0c;在源码实现中已经使用了二分查找&#xff08;size >> 1即是除以2&#xff09;的方法来进行优化&#xff0c;但查找元素的开销依然很大&#xff0c;并且与查找的位置有关。相比较ArrayList的常数级时间的消耗而言&#xff0c;差距很大。
clear()方法
public void clear() {// Clearing all of the links between nodes is "unnecessary", but:// - helps a generational GC if the discarded nodes inhabit// more than one generation// - is sure to free memory even if there is a reachable Iteratorfor (Node
}
该方法并不复杂&#xff0c;作用只是遍历列表&#xff0c;清空表中的元素和节点连接而已。之所以单独拿出来讲&#xff0c;是基于GC方面的考虑&#xff0c;源码注释中讲道&#xff0c;该方法中将所有节点之间的“连接”都断开并不是必要的&#xff0c;但是由于链表中的不同节点可能位于分代GC的不同年代中&#xff0c;如果它们互相引用会给GC带来一些额外的麻烦&#xff0c;因此执行此方法断开节点间的相互引用&#xff0c;可以帮助分代GC在这种情况下提高性能。
作为伴随JDK早期诞生的容器&#xff0c;Vector现在基本已经被弃用&#xff0c;不过依然有一些老版本的代码使用到它&#xff0c;因此也有必要做一些了解。Vector与ArrayList的实现基本相同&#xff0c;它们底层都是基于Object数组实现的&#xff0c;两者最大的区别在于ArrayList是非线程安全的&#xff0c;而Vector是线程安全的。由于Vector与ArrayList的实现非常相近&#xff0c;前面对于ArrayList已经进行过详细介绍了&#xff0c;这里很多东西就不在赘述&#xff0c;重点介绍Vector与ArrayList的不同之处。
Vector与ArrayList还有一处细节上的不同&#xff0c;那就是Vector进行添加操作时&#xff0c;如果列表容量不够需要扩容&#xff0c;每次增加的大小是原来的100%&#xff0c;而前面已经讲过&#xff0c;ArrayList一次只增加原有容量的50%。具体代码如下&#xff1a;
private void grow(int minCapacity) {// overflow-conscious codeint oldCapacity &#61; elementData.length;int newCapacity &#61; oldCapacity &#43; ((capacityIncrement > 0) ?capacityIncrement : oldCapacity);if (newCapacity - minCapacity <0)newCapacity &#61; minCapacity;if (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity &#61; hugeCapacity(minCapacity);elementData &#61; Arrays.copyOf(elementData, newCapacity);
}
Vector类内部的大部分方法与ArrayList均相同&#xff0c;区别仅在于加上了synchronized关键字&#xff0c;比如&#xff1a;
public synchronized void trimToSize() {modCount&#43;&#43;;int oldCapacity &#61; elementData.length;if (elementCount
这也保证了同一时刻只有一个线程能够写Vector&#xff0c;避免多线程同时写而引起的不一致性&#xff0c;但实现同步需要很高的花费&#xff0c;因此&#xff0c;访问Vector比访问ArrayList要慢。
前面说过&#xff0c;由于性能和一些设计问题&#xff0c;Vector现在基本已被弃用&#xff0c;当涉及到线程安全时&#xff0c;可以如前文介绍ArrayList时所说的&#xff0c;对ArrayList进行简单包装&#xff0c;即可实现同步。
Vector还有一个子类叫Stack&#xff0c;其实现了栈的基本操作。这也是在JDK早期出现的容器&#xff0c;很多设计不够规范&#xff0c;现在已经过时&#xff0c;使用Queue接口的相关实现可以完全取代它。








 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 